ML OCR memory leaks?
I have searched the existing issues, both open and closed, to make sure this is not a duplicate report.
- [x] Yes
The bug
I have over 30k photos and videos on my immich server, which has no gpu. So after I upload a bunch of fresh photos, I run immich-ml on my pc that has RTX 4070 Super via docker desktop and it crunches through face detection and smart search stuff in mere minutes. With OCR it runs like a turtle, so I left it running overnight.
When I came back 5 hours later, container ate all my resources:
- CPU: 99.97% (AMD Ryzen 5600X 6c/12t)
- RAM (container): 12.32GB / 15.58GB
- GPU VRAM: 11.7/12GB Dedicated, 15.5/16GB Shared, 27.2/28GB Total memory (ReBAR?) You can see from logs that it all happened in just one hour
This behavior is not isolated to Docker desktop, WSL or CUDA. When immich switched to its internal ml server, it maxed out 48c/96t Xeon CPU and load has not dropped even after I cancelled OCR job and cleaned the queue. The only fix was to restart ml container.
Used model: PP-OCRv5_server (~~I will test mobile version and report its performance later~~ UPD: PP-OCRv5_mobile doesn't have such issue)
Not related, but for some reason I couldn't run OCR in parallel (concurrency > 1), ml worker errors with
[E:onnxruntime:, sequential_executor.cc:516 ExecuteKernel] Non-zero status code returned while running FusedConv node. Name:'Conv.0' Status Message: CUDA error cudaErrorStreamCaptureUnsupported:operation not permitted when stream is capturing
The OS that Immich Server is running on
Debian 13 (via docker compose)
Version of Immich Server
v2.2.0
Version of Immich Mobile App
irrelevant
Platform with the issue
- [x] Server
- [ ] Web
- [ ] Mobile
Device make and model
No response
Your docker-compose.yml content
# ML worker compose content
name: immich
services:
immich-machine-learning:
container_name: immich_machine_learning
# For hardware acceleration, add one of -[armnn, cuda, rocm, openvino, rknn] to the image tag.
# Example tag: ${IMMICH_VERSION:-release}-cuda
image: ghcr.io/immich-app/immich-machine-learning:${IMMICH_VERSION:-release}-cuda
extends: # uncomment this section for hardware acceleration - see https://docs.immich.app/features/ml-hardware-acceleration
file: hwaccel.ml.yml
service: cuda # set to one of [armnn, cuda, rocm, openvino, openvino-wsl, rknn] for accelerated inference - use the `-wsl` version for WSL2 where applicable
volumes:
- model-cache:/cache
environment:
- IMMICH_VERSION=v2
restart: always
healthcheck:
disable: false
ports:
- 3003:3003
volumes:
model-cache:
Your .env content
IMMICH_VERSION=v2
Reproduction steps
described above
Relevant log output
immich_machine_learning | [11/01/25 00:49:08] INFO Setting execution providers to
immich_machine_learning | ['CUDAExecutionProvider', 'CPUExecutionProvider'],
immich_machine_learning | in descending order of preference
immich_machine_learning | [11/01/25 00:49:08] INFO Using engine_name: onnxruntime
immich_machine_learning | 2025-11-01 01:39:54.138027723 [E:onnxruntime:, sequential_executor.cc:516 ExecuteKernel] Non-zero status code returned while running Concat node. Name:'Concat.16' Status Message: /onnxruntime_src/onnxruntime/core/framework/bfc_arena.cc:376 void* onnxruntime::BFCArena::AllocateRawInternal(size_t, bool, onnxruntime::Stream*, bool, onnxruntime::WaitNotificationFn) Failed to allocate memory for requested buffer of size 3706060800
immich_machine_learning |
immich_machine_learning | [11/01/25 01:39:54] ERROR Exception in ASGI application
immich_machine_learning |
immich_machine_learning | ╭─────── Traceback (most recent call last) ───────╮
immich_machine_learning | │ /opt/venv/lib/python3.11/site-packages/rapidocr │
immich_machine_learning | │ /inference_engine/onnxruntime/main.py:90 in │
immich_machine_learning | │ __call__ │
immich_machine_learning | │ │
immich_machine_learning | │ 87 │ def __call__(self, input_content: np. │
immich_machine_learning | │ 88 │ │ input_dict = dict(zip(self.get_in │
immich_machine_learning | │ 89 │ │ try: │
immich_machine_learning | │ ❱ 90 │ │ │ return self.session.run(self. │
immich_machine_learning | │ 91 │ │ except Exception as e: │
immich_machine_learning | │ 92 │ │ │ error_info = traceback.format │
immich_machine_learning | │ 93 │ │ │ raise ONNXRuntimeError(error_ │
immich_machine_learning | │ │
immich_machine_learning | │ /opt/venv/lib/python3.11/site-packages/onnxrunt │
immich_machine_learning | │ ime/capi/onnxruntime_inference_collection.py:22 │
immich_machine_learning | │ 0 in run │
immich_machine_learning | │ │
immich_machine_learning | │ 217 │ │ if not output_names: │
immich_machine_learning | │ 218 │ │ │ output_names = [output.name │
immich_machine_learning | │ 219 │ │ try: │
immich_machine_learning | │ ❱ 220 │ │ │ return self._sess.run(output │
immich_machine_learning | │ 221 │ │ except C.EPFail as err: │
immich_machine_learning | │ 222 │ │ │ if self._enable_fallback: │
immich_machine_learning | │ 223 │ │ │ │ print(f"EP Error: {err!s │
immich_machine_learning | ╰─────────────────────────────────────────────────╯
immich_machine_learning | RuntimeException: [ONNXRuntimeError] : 6 :
immich_machine_learning | RUNTIME_EXCEPTION : Non-zero status code returned
immich_machine_learning | while running Concat node. Name:'Concat.16' Status
immich_machine_learning | Message:
immich_machine_learning | /onnxruntime_src/onnxruntime/core/framework/bfc_are
immich_machine_learning | na.cc:376 void*
immich_machine_learning | onnxruntime::BFCArena::AllocateRawInternal(size_t,
immich_machine_learning | bool, onnxruntime::Stream*, bool,
immich_machine_learning | onnxruntime::WaitNotificationFn) Failed to allocate
immich_machine_learning | memory for requested buffer of size 3706060800
immich_machine_learning |
immich_machine_learning |
immich_machine_learning | The above exception was the direct cause of the
immich_machine_learning | following exception:
immich_machine_learning |
immich_machine_learning | ╭─────── Traceback (most recent call last) ───────╮
immich_machine_learning | │ /usr/src/immich_ml/main.py:177 in predict │
immich_machine_learning | │ │
immich_machine_learning | │ 174 │ │ inputs = text │
immich_machine_learning | │ 175 │ else: │
immich_machine_learning | │ 176 │ │ raise HTTPException(400, "Either │
immich_machine_learning | │ ❱ 177 │ response = await run_inference(inputs │
immich_machine_learning | │ 178 │ return ORJSONResponse(response) │
immich_machine_learning | │ 179 │
immich_machine_learning | │ 180 │
immich_machine_learning | │ │
immich_machine_learning | │ /usr/src/immich_ml/main.py:202 in run_inference │
immich_machine_learning | │ │
immich_machine_learning | │ 199 │ │ response[entry["task"]] = output │
immich_machine_learning | │ 200 │ │
immich_machine_learning | │ 201 │ without_deps, with_deps = entries │
immich_machine_learning | │ ❱ 202 │ await asyncio.gather(*[_run_inference │
immich_machine_learning | │ 203 │ if with_deps: │
immich_machine_learning | │ 204 │ │ await asyncio.gather(*[_run_infer │
immich_machine_learning | │ 205 │ if isinstance(payload, Image): │
immich_machine_learning | │ │
immich_machine_learning | │ /usr/src/immich_ml/main.py:197 in │
immich_machine_learning | │ _run_inference │
immich_machine_learning | │ │
immich_machine_learning | │ 194 │ │ │ │ message = f"Task {entry[' │
immich_machine_learning | │ output of {dep}" │
immich_machine_learning | │ 195 │ │ │ │ raise HTTPException(400, │
immich_machine_learning | │ 196 │ │ model = await load(model) │
immich_machine_learning | │ ❱ 197 │ │ output = await run(model.predict, │
immich_machine_learning | │ 198 │ │ outputs[model.identity] = output │
immich_machine_learning | │ 199 │ │ response[entry["task"]] = output │
immich_machine_learning | │ 200 │
immich_machine_learning | │ │
immich_machine_learning | │ /usr/src/immich_ml/main.py:215 in run │
immich_machine_learning | │ │
immich_machine_learning | │ 212 │ if thread_pool is None: │
immich_machine_learning | │ 213 │ │ return func(*args, **kwargs) │
immich_machine_learning | │ 214 │ partial_func = partial(func, *args, * │
immich_machine_learning | │ ❱ 215 │ return await asyncio.get_running_loop │
immich_machine_learning | │ 216 │
immich_machine_learning | │ 217 │
immich_machine_learning | │ 218 async def load(model: InferenceModel) -> │
immich_machine_learning | │ │
immich_machine_learning | │ /usr/local/lib/python3.11/concurrent/futures/th │
immich_machine_learning | │ read.py:58 in run │
immich_machine_learning | │ │
immich_machine_learning | │ /usr/src/immich_ml/models/base.py:60 in predict │
immich_machine_learning | │ │
immich_machine_learning | │ 57 │ │ self.load() │
immich_machine_learning | │ 58 │ │ if model_kwargs: │
immich_machine_learning | │ 59 │ │ │ self.configure(**model_kwargs │
immich_machine_learning | │ ❱ 60 │ │ return self._predict(*inputs) │
immich_machine_learning | │ 61 │ │
immich_machine_learning | │ 62 │ @abstractmethod │
immich_machine_learning | │ 63 │ def _predict(self, *inputs: Any, **mo │
immich_machine_learning | │ │
immich_machine_learning | │ /usr/src/immich_ml/models/ocr/detection.py:68 │
immich_machine_learning | │ in _predict │
immich_machine_learning | │ │
immich_machine_learning | │ 65 │ │ return session │
immich_machine_learning | │ 66 │ │
immich_machine_learning | │ 67 │ def _predict(self, inputs: bytes | Ima │
immich_machine_learning | │ ❱ 68 │ │ results = self.model(decode_cv2(in │
immich_machine_learning | │ 69 │ │ if results.boxes is None or result │
immich_machine_learning | │ 70 │ │ │ return self._empty │
immich_machine_learning | │ 71 │ │ return { │
immich_machine_learning | │ │
immich_machine_learning | │ /opt/venv/lib/python3.11/site-packages/rapidocr │
immich_machine_learning | │ /ch_ppocr_det/main.py:59 in __call__ │
immich_machine_learning | │ │
immich_machine_learning | │ 56 │ │ if prepro_img is None: │
immich_machine_learning | │ 57 │ │ │ return TextDetOutput() │
immich_machine_learning | │ 58 │ │ │
immich_machine_learning | │ ❱ 59 │ │ preds = self.session(prepro_img) │
immich_machine_learning | │ 60 │ │ boxes, scores = self.postprocess_ │
immich_machine_learning | │ 61 │ │ if len(boxes) < 1: │
immich_machine_learning | │ 62 │ │ │ return TextDetOutput() │
immich_machine_learning | │ │
immich_machine_learning | │ /opt/venv/lib/python3.11/site-packages/rapidocr │
immich_machine_learning | │ /inference_engine/onnxruntime/main.py:93 in │
immich_machine_learning | │ __call__ │
immich_machine_learning | │ │
immich_machine_learning | │ 90 │ │ │ return self.session.run(self. │
immich_machine_learning | │ 91 │ │ except Exception as e: │
immich_machine_learning | │ 92 │ │ │ error_info = traceback.format │
immich_machine_learning | │ ❱ 93 │ │ │ raise ONNXRuntimeError(error_ │
immich_machine_learning | │ 94 │ │
immich_machine_learning | │ 95 │ def get_input_names(self) -> List[str │
immich_machine_learning | │ 96 │ │ return [v.name for v in self.sess │
immich_machine_learning | ╰─────────────────────────────────────────────────╯
immich_machine_learning | ONNXRuntimeError: Traceback (most recent call
immich_machine_learning | last):
immich_machine_learning | File
immich_machine_learning | "/opt/venv/lib/python3.11/site-packages/rapidocr/in
immich_machine_learning | ference_engine/onnxruntime/main.py", line 90, in
immich_machine_learning | __call__
immich_machine_learning | return
immich_machine_learning | self.session.run(self.get_output_names(),
immich_machine_learning | input_dict)[0]
immich_machine_learning | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
immich_machine_learning | ^^^^^^^^^^^^^
immich_machine_learning | File
immich_machine_learning | "/opt/venv/lib/python3.11/site-packages/onnxruntime
immich_machine_learning | /capi/onnxruntime_inference_collection.py", line
immich_machine_learning | 220, in run
immich_machine_learning | return self._sess.run(output_names, input_feed,
immich_machine_learning | run_options)
immich_machine_learning | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
immich_machine_learning | ^^^^^^^^^^^^^
immich_machine_learning | onnxruntime.capi.onnxruntime_pybind11_state.Runtime
immich_machine_learning | Exception: [ONNXRuntimeError] : 6 :
immich_machine_learning | RUNTIME_EXCEPTION : Non-zero status code returned
immich_machine_learning | while running Concat node. Name:'Concat.16' Status
immich_machine_learning | Message:
immich_machine_learning | /onnxruntime_src/onnxruntime/core/framework/bfc_are
immich_machine_learning | na.cc:376 void*
immich_machine_learning | onnxruntime::BFCArena::AllocateRawInternal(size_t,
immich_machine_learning | bool, onnxruntime::Stream*, bool,
immich_machine_learning | onnxruntime::WaitNotificationFn) Failed to allocate
immich_machine_learning | memory for requested buffer of size 3706060800
Additional information
No response
I found two potential memory issues in RapidOCR:
-
Memory leak in OpenVINO (not an actual leak, but a huge cache that grows continuously) https://medium.com/@dannysiu/solving-a-stubborn-memory-leak-in-my-openvino-paddleocr-service-f4e38a966e24
-
limit_type should be "max" instead of "min". According to the documentation, when limit_type=min and limit_side_len=736, if the minimum side of the image is less than 736, the minimum side will be stretched to 736, and the other side will be scaled proportionally according to the original image ratio. A 1x1000 pixel image will then be enlarged to 736x736000, consuming a large amount of memory.
I also encountered a similar problem.
`2025-11-01 22:06:21.747628180 [E:onnxruntime:, sequential_executor.cc:516 ExecuteKernel] Non-zero status code returned while running OpenVINO-EP-subgraph_1 node. Name:'OpenVINOExecutionProvider_OpenVINO-EP-subgraph_1_0' Status Message: /onnxruntime/onnxruntime/core/providers/openvino/ov_interface.cc:243 void onnxruntime::openvino_ep::OVInferRequest::WaitRequest() [OpenVINO-EP] Wait Model Failed: Exception from src/inference/src/cpp/infer_request.cpp:245: Check 'layout.bytes_count() + used_mem <= get_max_memory_size()' failed at src/plugins/intel_gpu/src/runtime/ocl/ocl_engine.cpp:143: [GPU] Exceeded max size of memory allocation: Required 1140506640 bytes, already occupied : 15924337288 bytes, but available memory size is 16251318272 bytes
[11/01/25 22:06:21] ERROR Exception in ASGI application
╭─────── Traceback (most recent call last) ───────╮
│ /opt/venv/lib/python3.11/site-packages/rapidocr │
│ /inference_engine/onnxruntime/main.py:90 in │
│ __call__ │
│ │
│ 87 │ def __call__(self, input_content: np. │
│ 88 │ │ input_dict = dict(zip(self.get_in │
│ 89 │ │ try: │
│ ❱ 90 │ │ │ return self.session.run(self. │
│ 91 │ │ except Exception as e: │
│ 92 │ │ │ error_info = traceback.format │
│ 93 │ │ │ raise ONNXRuntimeError(error_ │
│ │
│ /opt/venv/lib/python3.11/site-packages/onnxrunt │
│ ime/capi/onnxruntime_inference_collection.py:22 │
│ 0 in run │
│ │
│ 217 │ │ if not output_names: │
│ 218 │ │ │ output_names = [output.name │
│ 219 │ │ try: │
│ ❱ 220 │ │ │ return self._sess.run(output │
│ 221 │ │ except C.EPFail as err: │
│ 222 │ │ │ if self._enable_fallback: │
│ 223 │ │ │ │ print(f"EP Error: {err!s │
╰─────────────────────────────────────────────────╯
Fail: [ONNXRuntimeError] : 1 : FAIL : Non-zero
status code returned while running
OpenVINO-EP-subgraph_1 node.
Name:'OpenVINOExecutionProvider_OpenVINO-EP-subgrap
h_1_0' Status Message:
/onnxruntime/onnxruntime/core/providers/openvino/ov
_interface.cc:243 void
onnxruntime::openvino_ep::OVInferRequest::WaitReque
st() [OpenVINO-EP] Wait Model Failed: Exception
from src/inference/src/cpp/infer_request.cpp:245:
Check 'layout.bytes_count() + used_mem <=
get_max_memory_size()' failed at
src/plugins/intel_gpu/src/runtime/ocl/ocl_engine.cp
p:143:
[GPU] Exceeded max size of memory allocation:
Required 1140506640 bytes, already occupied :
15924337288 bytes, but available memory size is
16251318272 bytes
The above exception was the direct cause of the
following exception:
╭─────── Traceback (most recent call last) ───────╮
│ /usr/src/immich_ml/main.py:177 in predict │
│ │
│ 174 │ │ inputs = text │
│ 175 │ else: │
│ 176 │ │ raise HTTPException(400, "Either │
│ ❱ 177 │ response = await run_inference(inputs │
│ 178 │ return ORJSONResponse(response) │
│ 179 │
│ 180 │
│ │
│ /usr/src/immich_ml/main.py:202 in run_inference │
│ │
│ 199 │ │ response[entry["task"]] = output │
│ 200 │ │
│ 201 │ without_deps, with_deps = entries │
│ ❱ 202 │ await asyncio.gather(*[_run_inference │
│ 203 │ if with_deps: │
│ 204 │ │ await asyncio.gather(*[_run_infer │
│ 205 │ if isinstance(payload, Image): │
│ │
│ /usr/src/immich_ml/main.py:197 in │
│ _run_inference │
│ │
│ 194 │ │ │ │ message = f"Task {entry[' │
│ output of {dep}" │
│ 195 │ │ │ │ raise HTTPException(400, │
│ 196 │ │ model = await load(model) │
│ ❱ 197 │ │ output = await run(model.predict, │
│ 198 │ │ outputs[model.identity] = output │
│ 199 │ │ response[entry["task"]] = output │
│ 200 │
│ │
│ /usr/src/immich_ml/main.py:215 in run │
│ │
│ 212 │ if thread_pool is None: │
│ 213 │ │ return func(*args, **kwargs) │
│ 214 │ partial_func = partial(func, *args, * │
│ ❱ 215 │ return await asyncio.get_running_loop │
│ 216 │
│ 217 │
│ 218 async def load(model: InferenceModel) -> │
│ │
│ /usr/local/lib/python3.11/concurrent/futures/th │
│ read.py:58 in run │
│ │
│ /usr/src/immich_ml/models/base.py:60 in predict │
│ │
│ 57 │ │ self.load() │
│ 58 │ │ if model_kwargs: │
│ 59 │ │ │ self.configure(**model_kwargs │
│ ❱ 60 │ │ return self._predict(*inputs) │
│ 61 │ │
│ 62 │ @abstractmethod │
│ 63 │ def _predict(self, *inputs: Any, **mo │
│ │
│ /usr/src/immich_ml/models/ocr/detection.py:68 │
│ in _predict │
│ │
│ 65 │ │ return session │
│ 66 │ │
│ 67 │ def _predict(self, inputs: bytes | Ima │
│ ❱ 68 │ │ results = self.model(decode_cv2(in │
│ 69 │ │ if results.boxes is None or result │
│ 70 │ │ │ return self._empty │
│ 71 │ │ return { │
│ │
│ /opt/venv/lib/python3.11/site-packages/rapidocr │
│ /ch_ppocr_det/main.py:59 in __call__ │
│ │
│ 56 │ │ if prepro_img is None: │
│ 57 │ │ │ return TextDetOutput() │
│ 58 │ │ │
│ ❱ 59 │ │ preds = self.session(prepro_img) │
│ 60 │ │ boxes, scores = self.postprocess_ │
│ 61 │ │ if len(boxes) < 1: │
│ 62 │ │ │ return TextDetOutput() │
│ │
│ /opt/venv/lib/python3.11/site-packages/rapidocr │
│ /inference_engine/onnxruntime/main.py:93 in │
│ __call__ │
│ │
│ 90 │ │ │ return self.session.run(self. │
│ 91 │ │ except Exception as e: │
│ 92 │ │ │ error_info = traceback.format │
│ ❱ 93 │ │ │ raise ONNXRuntimeError(error_ │
│ 94 │ │
│ 95 │ def get_input_names(self) -> List[str │
│ 96 │ │ return [v.name for v in self.sess │
╰─────────────────────────────────────────────────╯
ONNXRuntimeError: Traceback (most recent call
last):
File
"/opt/venv/lib/python3.11/site-packages/rapidocr/in
ference_engine/onnxruntime/main.py", line 90, in
__call__
return
self.session.run(self.get_output_names(),
input_dict)[0]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
^^^^^^^^^^^^^
File
"/opt/venv/lib/python3.11/site-packages/onnxruntime
/capi/onnxruntime_inference_collection.py", line
220, in run
return self._sess.run(output_names, input_feed,
run_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
^^^^^^^^^^^^^
onnxruntime.capi.onnxruntime_pybind11_state.Fail:
[ONNXRuntimeError] : 1 : FAIL : Non-zero status
code returned while running OpenVINO-EP-subgraph_1
node.
Name:'OpenVINOExecutionProvider_OpenVINO-EP-subgrap
h_1_0' Status Message:
/onnxruntime/onnxruntime/core/providers/openvino/ov
_interface.cc:243 void
onnxruntime::openvino_ep::OVInferRequest::WaitReque
st() [OpenVINO-EP] Wait Model Failed: Exception
from src/inference/src/cpp/infer_request.cpp:245:
Check 'layout.bytes_count() + used_mem <=
get_max_memory_size()' failed at
src/plugins/intel_gpu/src/runtime/ocl/ocl_engine.cp
p:143:
[GPU] Exceeded max size of memory allocation:
Required 1140506640 bytes, already occupied :
15924337288 bytes, but available memory size is
16251318272 bytes `
I can confirm I am seeing the same OOM issue.
System Details
- CPU/GPU: Intel Ultra 7 255H (using the integrated Arc GPU for ML)
- RAM: 64GB
- Version 2.2.1
- Ubuntu 25.04 Server
Problem Description
- Running the server model (PP-OCRv5_server) causes memory usage to climb continuously until the container crashes with an OOM error.
- My logs show the same ONNXRuntimeError and Failed to allocate memory errors as reported by others.
Workaround & New Observation As shown in the attached memory graph, I switched to the mobile model (PP-OCRv5_mobile) at 10:40:00.
- Memory: The mobile model's memory usage is stable at ~10GB.
- CPU/GPU: However, after switching, my CPU usage increased significantly, as seen in the gpu top output. This makes me question if the mobile model is correctly utilizing the Arc GPU or if it's falling back to the CPU.
I will report back on the long-term stability of the mobile model.
[11/01/25 17:46:15] ERROR Exception in ASGI application
╭─────── Traceback (most recent call last) ───────╮
│ /usr/src/immich_ml/main.py:177 in predict │
│ │
│ 174 │ │ inputs = text │
│ 175 │ else: │
│ 176 │ │ raise HTTPException(400, "Either │
│ ❱ 177 │ response = await run_inference(inputs │
│ 178 │ return ORJSONResponse(response) │
│ 179 │
│ 180 │
│ │
│ /usr/src/immich_ml/main.py:204 in run_inference │
│ │
│ 201 │ without_deps, with_deps = entries │
│ 202 │ await asyncio.gather(*[_run_inference │
│ 203 │ if with_deps: │
│ ❱ 204 │ │ await asyncio.gather(*[_run_infer │
│ 205 │ if isinstance(payload, Image): │
│ 206 │ │ response["imageHeight"], response │
│ 207 │
│ │
│ /usr/src/immich_ml/main.py:197 in │
│ _run_inference │
│ │
│ 194 │ │ │ │ message = f"Task {entry[' │
│ output of {dep}" │
│ 195 │ │ │ │ raise HTTPException(400, │
│ 196 │ │ model = await load(model) │
│ ❱ 197 │ │ output = await run(model.predict, │
│ 198 │ │ outputs[model.identity] = output │
│ 199 │ │ response[entry["task"]] = output │
│ 200 │
│ │
│ /usr/src/immich_ml/main.py:215 in run │
│ │
│ 212 │ if thread_pool is None: │
│ 213 │ │ return func(*args, **kwargs) │
│ 214 │ partial_func = partial(func, *args, * │
│ ❱ 215 │ return await asyncio.get_running_loop │
│ 216 │
│ 217 │
│ 218 async def load(model: InferenceModel) -> │
│ │
│ /usr/local/lib/python3.11/concurrent/futures/th │
│ read.py:58 in run │
│ │
│ /usr/src/immich_ml/models/base.py:60 in predict │
│ │
│ 57 │ │ self.load() │
│ 58 │ │ if model_kwargs: │
│ 59 │ │ │ self.configure(**model_kwargs │
│ ❱ 60 │ │ return self._predict(*inputs) │
│ 61 │ │
│ 62 │ @abstractmethod │
│ 63 │ def _predict(self, *inputs: Any, **mo │
│ │
│ /usr/src/immich_ml/models/ocr/recognition.py:72 │
│ in _predict │
│ │
│ 69 │ │ boxes, img, box_scores = texts["b │
│ 70 │ │ if boxes.shape[0] == 0: │
│ 71 │ │ │ return self._empty │
│ ❱ 72 │ │ rec = self.model(TextRecInput(img │
│ 73 │ │ if rec.txts is None: │
│ 74 │ │ │ return self._empty │
│ 75 │
│ │
│ /opt/venv/lib/python3.11/site-packages/rapidocr │
│ /ch_ppocr_rec/main.py:137 in __call__ │
│ │
│ 134 │ │ │ │ rec_res[indices[beg_img_n │
│ 135 │ │ │
│ 136 │ │ all_line_results, all_word_result │
│ ❱ 137 │ │ txts, scores = list(zip(*all_line │
│ 138 │ │ │
│ 139 │ │ elapse = time.perf_counter() - st │
│ 140 │ │ return TextRecOutput( │
╰─────────────────────────────────────────────────╯
ValueError: not enough values to unpack (expected
2, got 0)
I can confirm memory leaks with new ocr implementation. I have server with 256GB of RAM and after 1 day of processing photos immich ml container was using all of it and crashed because OOM.
The mobile model also seems to be affected, it just takes longer to appear.
I think OpenVINO likely has a memory leak here, but I haven't seen anything to suggest CPU or CUDA leaks memory. High RAM usage is not the same thing as a leak, for reference.
For the latter topic, I think the comment on the resolution limit behavior is something to experiment with and potentially change.
I run it in an docker. My machine is n305 with 16gb, after 5 seconds, the server stop all docker containers and incus containers. I think it is a mem leak but don't have time to dig into the problem yet.
After I made the following modifications, it worked properly for a long time and seemed to have no issues: In immich_ml/models/ocr/detection.py and immich_ml/models/ocr/recognition.py, change session = OrtSession(self.model_path) to session = OrtSession(self.model_path, ['CPUExecutionProvider']) to force the use of CPU instead of OpenVINO. In immich_ml/models/ocr/detection.py, change limit_type="min" to limit_type="max", and set max_resolution to 4000 in the UI.
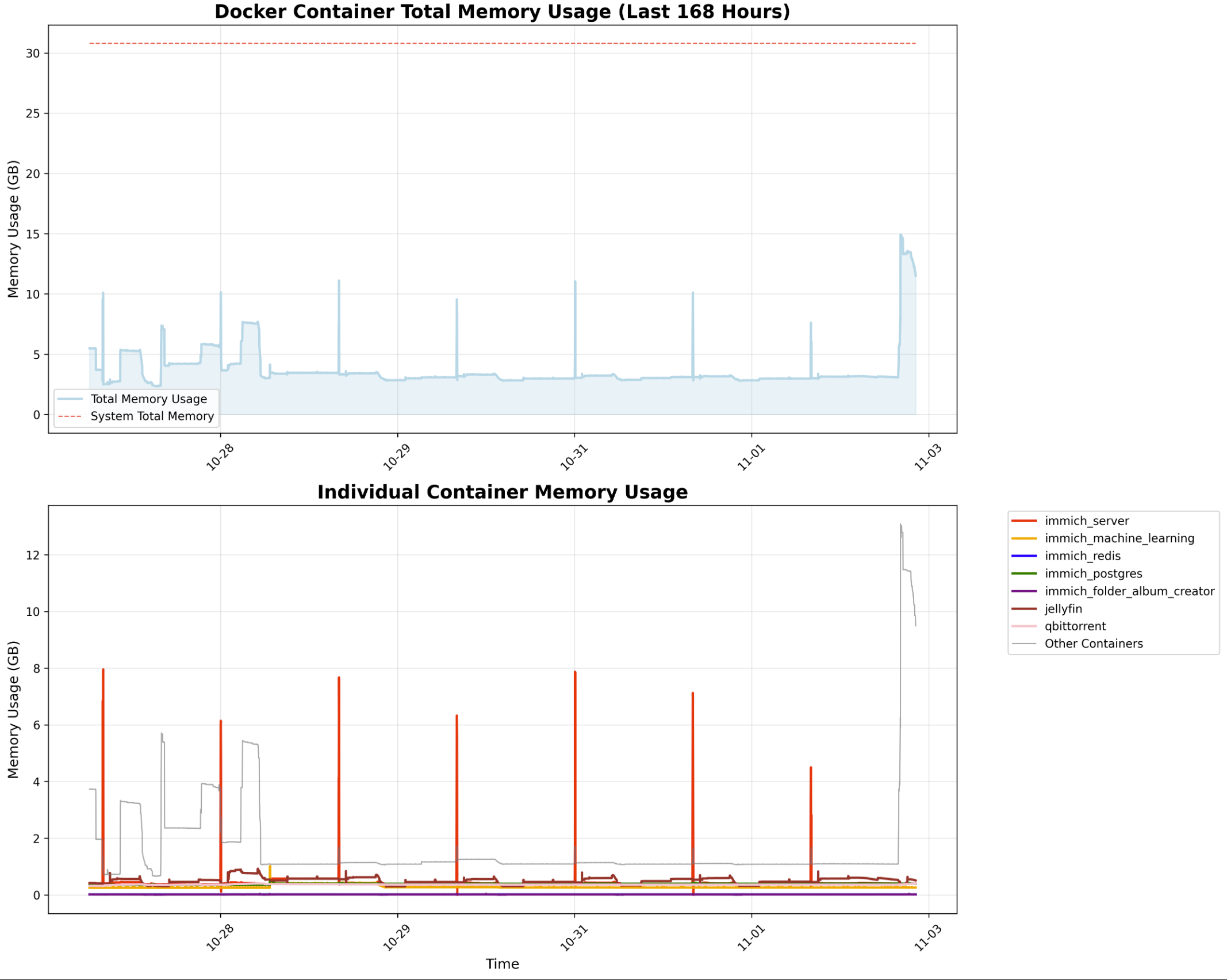
I mean, I see this all the time, I wrote a systemd service to restart the 6 ML workers I am running when it shows in the logs. seems to keep the whole system from freaking out
ONNXRuntimeError: Traceback (most recent call
ml-gpu-1-1 | last):
ml-gpu-1-1 | File
ml-gpu-1-1 | "/opt/venv/lib/python3.11/site-packages/rapidocr/in
ml-gpu-1-1 | ference_engine/onnxruntime/main.py", line 90, in
ml-gpu-1-1 | __call__
ml-gpu-1-1 | return
ml-gpu-1-1 | self.session.run(self.get_output_names(),
ml-gpu-1-1 | input_dict)[0]
ml-gpu-1-1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ml-gpu-1-1 | ^^^^^^^^^^^^^
ml-gpu-1-1 | File
ml-gpu-1-1 | "/opt/venv/lib/python3.11/site-packages/onnxruntime
ml-gpu-1-1 | /capi/onnxruntime_inference_collection.py", line
ml-gpu-1-1 | 220, in run
ml-gpu-1-1 | return self._sess.run(output_names, input_feed,
ml-gpu-1-1 | run_options)
ml-gpu-1-1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ml-gpu-1-1 | ^^^^^^^^^^^^^
ml-gpu-1-1 | onnxruntime.capi.onnxruntime_pybind11_state.Runtime
ml-gpu-1-1 | Exception: [ONNXRuntimeError] : 6 :
ml-gpu-1-1 | RUNTIME_EXCEPTION : Non-zero status code returned
ml-gpu-1-1 | while running Resize node. Name:'Resize.6' Status
ml-gpu-1-1 | Message:
ml-gpu-1-1 | /onnxruntime_src/onnxruntime/core/framework/bfc_are
ml-gpu-1-1 | na.cc:376 void*
ml-gpu-1-1 | onnxruntime::BFCArena::AllocateRawInternal(size_t,
ml-gpu-1-1 | bool, onnxruntime::Stream*, bool,
ml-gpu-1-1 | onnxruntime::WaitNotificationFn) Failed to allocate
ml-gpu-1-1 | memory for requested buffer of size 6464471040
ml-gpu-3-1 | ONNXRuntimeError: Traceback (most recent call
ml-gpu-3-1 | last):
ml-gpu-3-1 | File
ml-gpu-3-1 | "/opt/venv/lib/python3.11/site-packages/rapidocr/in
ml-gpu-3-1 | ference_engine/onnxruntime/main.py", line 90, in
ml-gpu-3-1 | __call__
ml-gpu-3-1 | return
ml-gpu-3-1 | self.session.run(self.get_output_names(),
ml-gpu-3-1 | input_dict)[0]
ml-gpu-3-1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ml-gpu-3-1 | ^^^^^^^^^^^^^
ml-gpu-3-1 | File
ml-gpu-3-1 | "/opt/venv/lib/python3.11/site-packages/onnxruntime
ml-gpu-3-1 | /capi/onnxruntime_inference_collection.py", line
ml-gpu-3-1 | 220, in run
ml-gpu-3-1 | return self._sess.run(output_names, input_feed,
ml-gpu-3-1 | run_options)
ml-gpu-3-1 | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ml-gpu-3-1 | ^^^^^^^^^^^^^
ml-gpu-3-1 | onnxruntime.capi.onnxruntime_pybind11_state.Runtime
ml-gpu-3-1 | Exception: [ONNXRuntimeError] : 6 :
ml-gpu-3-1 | RUNTIME_EXCEPTION : Non-zero status code returned
ml-gpu-3-1 | while running FusedConv node. Name:'Conv.18' Status
ml-gpu-3-1 | Message:
ml-gpu-3-1 | /onnxruntime_src/onnxruntime/core/providers/cuda/cu
ml-gpu-3-1 | da_call.cc:123 std::conditional_t<THRW, void,
ml-gpu-3-1 | onnxruntime::common::Status>
ml-gpu-3-1 | onnxruntime::CudaCall(ERRTYPE, const char*, const
ml-gpu-3-1 | char*, ERRTYPE, const char*, const char*, int)
ml-gpu-3-1 | [with ERRTYPE = cudaError; bool THRW = true;
ml-gpu-3-1 | std::conditional_t<THRW, void, common::Status> =
ml-gpu-3-1 | void]
ml-gpu-3-1 | /onnxruntime_src/onnxruntime/core/providers/cuda/cu
ml-gpu-3-1 | da_call.cc:116 std::conditional_t<THRW, void,
ml-gpu-3-1 | onnxruntime::common::Status>
ml-gpu-3-1 | onnxruntime::CudaCall(ERRTYPE, const char*, const
ml-gpu-3-1 | char*, ERRTYPE, const char*, const char*, int)
ml-gpu-3-1 | [with ERRTYPE = cudaError; bool THRW = true;
ml-gpu-3-1 | std::conditional_t<THRW, void, common::Status> =
ml-gpu-3-1 | void] CUDA failure 2: out of memory ; GPU=0 ;
ml-gpu-3-1 | hostname=a0e946587957 ;
ml-gpu-3-1 | file=/onnxruntime_src/onnxruntime/core/providers/cu
ml-gpu-3-1 | da/cuda_allocator.cc ; line=47 ;
ml-gpu-3-1 | expr=cudaMalloc((void**)&p, size);
After I made the following modifications, it worked properly for a long time and seemed to have no issues: In immich_ml/models/ocr/detection.py and immich_ml/models/ocr/recognition.py, change session = OrtSession(self.model_path) to session = OrtSession(self.model_path, ['CPUExecutionProvider']) to force the use of CPU instead of OpenVINO. In immich_ml/models/ocr/detection.py, change limit_type="min" to limit_type="max", and set max_resolution to 4000 in the UI.
I did all these changes. Thanks! When it tried using my GPU (Intel Arc A380) it produced mostly gibberish output after a while (at first, it looked to be working but after running for some time it starts producing gibberish) and very high CPU usage, sysram was steadily climbing. Not searchable. With CPU only, OCR works fine. Did these changes and running "All" again. Looking good as of now, running OCR on CPU only and clip/face on GPU. Let's see how it goes. It also uses about half CPU now and no GPU when on CPU only. Pretty sure OpenVINO is broken for OCR at the moment, at least in my case. Using the mobile model.
Pretty sure OpenVINO is broken for OCR at the moment, at least in my case. Using the mobile model.
Same here, no RAM crashes but all the work is done by the CPU and it seems quite intensive even with concurrency set to 1, took about 2 days and a half to process 75k assets on my Intel N100.
I got a crash for my lxc in proxmox - I noted that a core was non responding in the dump. So I have disabled OCR for now.
N305 with 12 GB memory allocated.
Has disabling OCR in ML settings been working for people? Is it a good workaround for now?
I switched to do OCR on CPU only, it works ok but slooow. https://github.com/immich-app/immich/issues/23462#issuecomment-3477923569
You can also remove the GPU from the ML-container temporary and it will do everything on CPU only. Could be done to do OCR on all the old assets and switch back when done.
very similar problems on my end but with the rocm image
Fail: [ONNXRuntimeError] : 1 : FAIL : Non-zero immich_machine_learning | status code returned while running ConvTranspose immich_machine_learning | node. Name:'ConvTranspose.0' Status Message: MIOPEN immich_machine_learning | failure 3: miopenStatusBadParm ; GPU=0 ;
immich_machine_learning | 2025-11-03 18:54:30.672862066 [E:onnxruntime:Default, rocm_call.cc:119 RocmCall] MIOPEN failure 3: miopenStatusBadParm ; GPU=0 ; hostname=09f9fe94960d ; file=/code/onnxruntime/onnxruntime/core/providers/rocm/nn/conv_transpose.cc ; line=133 ; expr=miopenFindConvolutionBackwardDataAlgorithm( GetMiopenHandle(context), s_.x_tensor, x_data, s_.w_desc, w_data, s_.conv_desc, s_.y_tensor, y_data, 1, &algo_count, &perf, algo_search_workspace.get(), AlgoSearchWorkspaceSize, false); immich_machine_learning | 2025-11-03 18:54:30.672870856 [E:onnxruntime:, sequential_executor.cc:516 ExecuteKernel] Non-zero status code returned while running ConvTranspose node. Name:'ConvTranspose.0' Status Message: MIOPEN failure 3: miopenStatusBadParm ; GPU=0 ; hostname=09f9fe94960d ; file=/code/onnxruntime/onnxruntime/core/providers/rocm/nn/conv_transpose.cc ; line=133 ; expr=miopenFindConvolutionBackwardDataAlgorithm( GetMiopenHandle(context), s_.x_tensor, x_data, s_.w_desc, w_data, s_.conv_desc, s_.y_tensor, y_data, 1, &algo_count, &perf, algo_search_workspace.get(), AlgoSearchWorkspaceSize, false);
Has disabling OCR in ML settings been working for people? Is it a good workaround for now?
I disabled OCR in the ML settings and my ml pod memory usage has returned to normal.
Yeah, I have a very similar issue. Using an Intel Arc A380 with Immich, when I start the OCR job the VRAM usage on the GPU is <1GB but after ~3hrs it is over 2.5GB and eventually causes an OOM issue (the A380 has 6GB of VRAM). Using the openvino image with the mobile model.
Best temporary fix I've found is to restart the ML pod every 10 hours or so via cron, not an ideal solution but should allow large OCR to complete (I have 480k images to be processed)
High RAM usage is not the same thing as a leak, for reference.
True, but not reasonable. If a container will naturally spike to 10-16GB memory use the feature should be opt-in and provided with a warning instead of causing systems to crash. Not every computer has 64GB of memory or willing to allocate so much RAM to photo backup.
High RAM usage is not the same thing as a leak, for reference.
True, but not reasonable. If a container will naturally spike to 10-16GB memory use the feature should be opt-in and provided with a warning instead of causing systems to crash. Not every computer has 64GB of memory or willing to allocate so much RAM to photo backup.
Default settings on engines besides OpenVINO don't use anywhere near this much RAM. That being said, we are working on reducing RAM usage for all backends, with special consideration for OpenVINO.
I think this relates to https://github.com/immich-app/immich/pull/23541 and is potentially fixed/improved with 2.2.3
Not sure if this is a bug or I'm doing something wrong, after updating to 2.2.3, OCR with a GPU (CUDA) maxes out 24GB of VRAM and hangs like that until it gets shut down for inactivity. Maximum resolution is set to 1080. Concurrency set to 1. Container log output when running CUDA:
[11/05/25 22:23:57] INFO Initialized request thread pool with 24 threads.
[11/05/25 22:23:57] INFO Application startup complete.
[11/05/25 22:27:46] INFO Loading detection model 'PP-OCRv5_server' to memory
[11/05/25 22:27:46] INFO Setting execution providers to
['CUDAExecutionProvider', 'CPUExecutionProvider'],
in descending order of preference
2025-11-05 22:28:46.291717228 [E:onnxruntime:, sequential_executor.cc:516 ExecuteKernel] Non-zero status code returned while running Resize node. Name:'Resize.6' Status Message: /onnxruntime_src/onnxruntime/core/providers/cuda/shared_inc/fast_divmod.h:50 onnxruntime::cuda::DivMod<int>::DivMod(int) d_ >= 1 && d_ <= static_cast<uint32_t>(std::numeric_limits<int>::max()) was false.
[11/05/25 22:28:46] ERROR Exception in ASGI application
╭─────── Traceback (most recent call last) ───────╮
│ /usr/src/immich_ml/main.py:177 in predict │
│ │
│ 174 │ │ inputs = text │
│ 175 │ else: │
│ 176 │ │ raise HTTPException(400, "Either │
│ ❱ 177 │ response = await run_inference(inputs │
│ 178 │ return ORJSONResponse(response) │
│ 179 │
│ 180 │
│ │
│ /usr/src/immich_ml/main.py:202 in run_inference │
│ │
│ 199 │ │ response[entry["task"]] = output │
│ 200 │ │
│ 201 │ without_deps, with_deps = entries │
│ ❱ 202 │ await asyncio.gather(*[_run_inference │
│ 203 │ if with_deps: │
│ 204 │ │ await asyncio.gather(*[_run_infer │
│ 205 │ if isinstance(payload, Image): │
│ │
│ /usr/src/immich_ml/main.py:197 in │
│ _run_inference │
│ │
│ 194 │ │ │ │ message = f"Task {entry[' │
│ output of {dep}" │
│ 195 │ │ │ │ raise HTTPException(400, │
│ 196 │ │ model = await load(model) │
│ ❱ 197 │ │ output = await run(model.predict, │
│ 198 │ │ outputs[model.identity] = output │
│ 199 │ │ response[entry["task"]] = output │
│ 200 │
│ │
│ /usr/src/immich_ml/main.py:215 in run │
│ │
│ 212 │ if thread_pool is None: │
│ 213 │ │ return func(*args, **kwargs) │
│ 214 │ partial_func = partial(func, *args, * │
│ ❱ 215 │ return await asyncio.get_running_loop │
│ 216 │
│ 217 │
│ 218 async def load(model: InferenceModel) -> │
│ │
│ /usr/local/lib/python3.11/concurrent/futures/th │
│ read.py:58 in run │
│ │
│ /usr/src/immich_ml/models/base.py:60 in predict │
│ │
│ 57 │ │ self.load() │
│ 58 │ │ if model_kwargs: │
│ 59 │ │ │ self.configure(**model_kwargs │
│ ❱ 60 │ │ return self._predict(*inputs) │
│ 61 │ │
│ 62 │ @abstractmethod │
│ 63 │ def _predict(self, *inputs: Any, **mo │
│ │
│ /usr/src/immich_ml/models/ocr/detection.py:70 │
│ in _predict │
│ │
│ 67 │ │ w, h = inputs.size │
│ 68 │ │ if w < 32 or h < 32: │
│ 69 │ │ │ return self._empty │
│ ❱ 70 │ │ out = self.session.run(None, {"x" │
│ 71 │ │ boxes, scores = self.postprocess( │
│ 72 │ │ if len(boxes) == 0: │
│ 73 │ │ │ return self._empty │
│ │
│ /usr/src/immich_ml/sessions/ort.py:51 in run │
│ │
│ 48 │ │ input_feed: dict[str, NDArray[np. │
│ 49 │ │ run_options: Any = None, │
│ 50 │ ) -> list[NDArray[np.float32]]: │
│ ❱ 51 │ │ outputs: list[NDArray[np.float32] │
│ run_options) │
│ 52 │ │ return outputs │
│ 53 │ │
│ 54 │ @property │
│ │
│ /opt/venv/lib/python3.11/site-packages/onnxrunt │
│ ime/capi/onnxruntime_inference_collection.py:22 │
│ 0 in run │
│ │
│ 217 │ │ if not output_names: │
│ 218 │ │ │ output_names = [output.name │
│ 219 │ │ try: │
│ ❱ 220 │ │ │ return self._sess.run(output │
│ 221 │ │ except C.EPFail as err: │
│ 222 │ │ │ if self._enable_fallback: │
│ 223 │ │ │ │ print(f"EP Error: {err!s │
╰─────────────────────────────────────────────────╯
RuntimeException: [ONNXRuntimeError] : 6 :
RUNTIME_EXCEPTION : Non-zero status code returned
while running Resize node. Name:'Resize.6' Status
Message:
/onnxruntime_src/onnxruntime/core/providers/cuda/sh
ared_inc/fast_divmod.h:50
onnxruntime::cuda::DivMod<int>::DivMod(int) d_ >= 1
&& d_ <=
static_cast<uint32_t>(std::numeric_limits<int>::max
()) was false.
[11/05/25 22:32:47] INFO Shutting down due to inactivity.
[11/05/25 22:32:47] INFO Shutting down
[11/05/25 22:32:47] INFO Waiting for application shutdown.
[11/05/25 22:32:48] INFO Application shutdown complete.
[11/05/25 22:32:48] INFO Finished server process [9]
[11/05/25 22:32:49] ERROR Worker (pid:9) was sent SIGINT!
[11/05/25 22:32:49] INFO Booting worker with pid: 230
[11/05/25 22:32:51] INFO Started server process [230]
[11/05/25 22:32:51] INFO Waiting for application startup.
[11/05/25 22:32:51] INFO Created in-memory cache with unloading after 300s
of inactivity.
[11/05/25 22:32:51] INFO Initialized request thread pool with 24 threads.
[11/05/25 22:32:51] INFO Application startup complete.
[11/05/25 22:34:24] INFO Loading detection model 'PP-OCRv5_server' to memory
[11/05/25 22:34:24] INFO Setting execution providers to
['CUDAExecutionProvider', 'CPUExecutionProvider'],
in descending order of preference
2025-11-05 22:35:24.709696664 [E:onnxruntime:, sequential_executor.cc:516 ExecuteKernel] Non-zero status code returned while running Resize node. Name:'Resize.6' Status Message: /onnxruntime_src/onnxruntime/core/providers/cuda/shared_inc/fast_divmod.h:50 onnxruntime::cuda::DivMod<int>::DivMod(int) d_ >= 1 && d_ <= static_cast<uint32_t>(std::numeric_limits<int>::max()) was false.
[11/05/25 22:35:24] ERROR Exception in ASGI application
╭─────── Traceback (most recent call last) ───────╮
│ /usr/src/immich_ml/main.py:177 in predict │
│ │
│ 174 │ │ inputs = text │
│ 175 │ else: │
│ 176 │ │ raise HTTPException(400, "Either │
│ ❱ 177 │ response = await run_inference(inputs │
│ 178 │ return ORJSONResponse(response) │
│ 179 │
│ 180 │
│ │
│ /usr/src/immich_ml/main.py:202 in run_inference │
│ │
│ 199 │ │ response[entry["task"]] = output │
│ 200 │ │
│ 201 │ without_deps, with_deps = entries │
│ ❱ 202 │ await asyncio.gather(*[_run_inference │
│ 203 │ if with_deps: │
│ 204 │ │ await asyncio.gather(*[_run_infer │
│ 205 │ if isinstance(payload, Image): │
│ │
│ /usr/src/immich_ml/main.py:197 in │
│ _run_inference │
│ │
│ 194 │ │ │ │ message = f"Task {entry[' │
│ output of {dep}" │
│ 195 │ │ │ │ raise HTTPException(400, │
│ 196 │ │ model = await load(model) │
│ ❱ 197 │ │ output = await run(model.predict, │
│ 198 │ │ outputs[model.identity] = output │
│ 199 │ │ response[entry["task"]] = output │
│ 200 │
│ │
│ /usr/src/immich_ml/main.py:215 in run │
│ │
│ 212 │ if thread_pool is None: │
│ 213 │ │ return func(*args, **kwargs) │
│ 214 │ partial_func = partial(func, *args, * │
│ ❱ 215 │ return await asyncio.get_running_loop │
│ 216 │
│ 217 │
│ 218 async def load(model: InferenceModel) -> │
│ │
│ /usr/local/lib/python3.11/concurrent/futures/th │
│ read.py:58 in run │
│ │
│ /usr/src/immich_ml/models/base.py:60 in predict │
│ │
│ 57 │ │ self.load() │
│ 58 │ │ if model_kwargs: │
│ 59 │ │ │ self.configure(**model_kwargs │
│ ❱ 60 │ │ return self._predict(*inputs) │
│ 61 │ │
│ 62 │ @abstractmethod │
│ 63 │ def _predict(self, *inputs: Any, **mo │
│ │
│ /usr/src/immich_ml/models/ocr/detection.py:70 │
│ in _predict │
│ │
│ 67 │ │ w, h = inputs.size │
│ 68 │ │ if w < 32 or h < 32: │
│ 69 │ │ │ return self._empty │
│ ❱ 70 │ │ out = self.session.run(None, {"x" │
│ 71 │ │ boxes, scores = self.postprocess( │
│ 72 │ │ if len(boxes) == 0: │
│ 73 │ │ │ return self._empty │
│ │
│ /usr/src/immich_ml/sessions/ort.py:51 in run │
│ │
│ 48 │ │ input_feed: dict[str, NDArray[np. │
│ 49 │ │ run_options: Any = None, │
│ 50 │ ) -> list[NDArray[np.float32]]: │
│ ❱ 51 │ │ outputs: list[NDArray[np.float32] │
│ run_options) │
│ 52 │ │ return outputs │
│ 53 │ │
│ 54 │ @property │
│ │
│ /opt/venv/lib/python3.11/site-packages/onnxrunt │
│ ime/capi/onnxruntime_inference_collection.py:22 │
│ 0 in run │
│ │
│ 217 │ │ if not output_names: │
│ 218 │ │ │ output_names = [output.name │
│ 219 │ │ try: │
│ ❱ 220 │ │ │ return self._sess.run(output │
│ 221 │ │ except C.EPFail as err: │
│ 222 │ │ │ if self._enable_fallback: │
│ 223 │ │ │ │ print(f"EP Error: {err!s │
╰─────────────────────────────────────────────────╯
RuntimeException: [ONNXRuntimeError] : 6 :
RUNTIME_EXCEPTION : Non-zero status code returned
while running Resize node. Name:'Resize.6' Status
Message:
/onnxruntime_src/onnxruntime/core/providers/cuda/sh
ared_inc/fast_divmod.h:50
onnxruntime::cuda::DivMod<int>::DivMod(int) d_ >= 1
&& d_ <=
static_cast<uint32_t>(std::numeric_limits<int>::max
()) was false.
Running CPU only OCR goes up to ~7GB of RAM and then loops the following output in the log:
[11/05/25 22:42:56] INFO Initialized request thread pool with 24 threads.
[11/05/25 22:42:56] INFO Application startup complete.
[11/05/25 22:43:54] INFO Loading detection model 'PP-OCRv5_server' to memory
[11/05/25 22:43:54] INFO Setting execution providers to
['CPUExecutionProvider'], in descending order of
preference
[11/05/25 22:45:42] ERROR Worker (pid:9) was sent SIGKILL! Perhaps out of
memory?
[11/05/25 22:45:42] INFO Booting worker with pid: 119
[11/05/25 22:45:45] INFO Started server process [119]
[11/05/25 22:45:45] INFO Waiting for application startup.
[11/05/25 22:45:45] INFO Created in-memory cache with unloading after 300s
of inactivity.
[11/05/25 22:45:45] INFO Initialized request thread pool with 24 threads.
[11/05/25 22:45:45] INFO Application startup complete.
[11/05/25 22:45:49] INFO Loading detection model 'PP-OCRv5_server' to memory
[11/05/25 22:45:49] INFO Setting execution providers to
['CPUExecutionProvider'], in descending order of
preference
[11/05/25 22:47:36] ERROR Worker (pid:119) was sent SIGKILL! Perhaps out of
memory?
[11/05/25 22:47:36] INFO Booting worker with pid: 221
[11/05/25 22:47:39] INFO Started server process [221]
[11/05/25 22:47:39] INFO Waiting for application startup.
[11/05/25 22:47:39] INFO Created in-memory cache with unloading after 300s
of inactivity.
[11/05/25 22:47:39] INFO Initialized request thread pool with 24 threads.
The system at the time of the error had ~40GB of memory free.
Disregard my previous post, that behaviour seems to be caused by an erroneous asset somewhere in my library, I cannot replicate it with newly added photos.
It took me longer to realize, but OCR has also caused memory issues for me. My system was consistently hard crashing while processing a catalogue of images for OCR, and only disabling OCR in the settings resolved the issue.
I also received an out of error memory issue with the immich machine learning container, this was during the running of the OCR job using the default settings (mobile ocr). I've since added a memory limit to the container.
UNRAID / 32GB RAM / docker-compose method / Immich v2.21 Using hardware acceleration with onboard intel iGPU i5-13500.
I also noted that it was using CPU power instead of GPU and was very slow.
immich-machine-learning:
container_name: immich_machine_learning
# image: ghcr.io/immich-app/immich-machine-learning:${IMMICH_VERSION:-release}
image: ghcr.io/immich-app/immich-machine-learning:${IMMICH_VERSION:-release}-openvino # HW ACCELERATION OPEN-VINO
volumes:
- /mnt/nvme4tb/immich/model-cache:/cache
- /dev/bus/usb:/dev/bus/usb # HW ACCELERATION OPEN-VINO
env_file:
- .env
restart: always
healthcheck:
disable: false
device_cgroup_rules: # HW ACCELERATION OPEN-VINO
- 'c 189:* rmw' # HW ACCELERATION OPEN-VINO
devices:
- /dev/dri:/dev/dri # HW ACCELERATION OPEN-VINO
deploy:
resources:
limits:
cpus: "8"
I also noted that it was using CPU power instead of GPU and was very slow.
Seems like OpenVINO OCR is broken for many people:
https://github.com/immich-app/immich/issues/23408 (not sure why it was closed) https://github.com/immich-app/immich/issues/23600#issuecomment-3486464729
OCR i broken for me too with OpenVINO on docker container on TruenNAS Scale 25.10. (my memory usage grows witouth limit)