gharchive.org
 gharchive.org copied to clipboard
gharchive.org copied to clipboard
Is it possible to add githubarchive data to bigquery public datasets?
Looking through public datasets on the google cloud dashboard for bigquery, githubarchive doesn't show up, is there anyway to get it added?
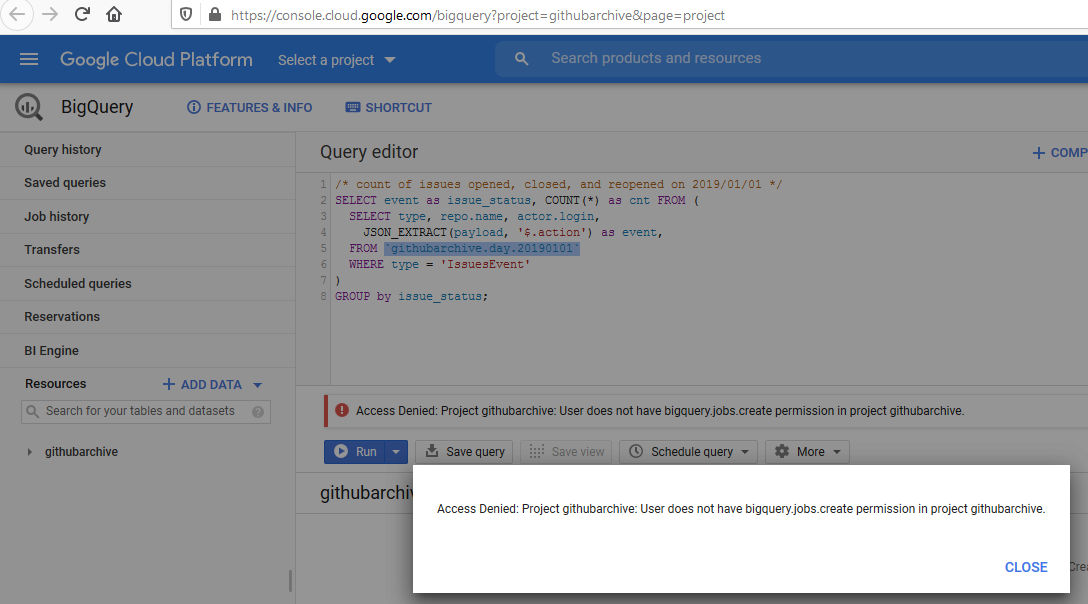
+1, trying to apply the following tutorial at https://www.gharchive.org/ breaks with Access Denied: Project githubarchive: User does not have bigquery.jobs.create permission in project githubarchive.
The entire GH Archive is also available as a public dataset on Google BigQuery: the dataset is automatically updated every hour and enables you to run arbitrary SQL-like queries over the entire dataset in seconds. To get started:
If you don't already have a Google project... Login into the Google Developer Console Create a project and activate the BigQuery API Open public dataset: https://console.cloud.google.com/bigquery?project=githubarchive&page=project Execute your first query.../* count of issues opened, closed, and reopened on 2019/01/01 / SELECT event as issue_status, COUNT() as cnt FROM ( SELECT type, repo.name, actor.login, JSON_EXTRACT(payload, '$.action') as event, FROM
githubarchive.day.20190101WHERE type = 'IssuesEvent' ) GROUP by issue_status; view raw bq.sql hosted with ❤ by GitHub
Am I missing something ?
Bigquery dataset is most likely to be outdated, but we prepared another publicly available dataset for interactive access. It is published at https://gh.clickhouse.tech/explorer/
You may experience faster query times because it is hosted in ClickHouse.
@alexey-milovidov that's awesome, thanks!
Curious, which fields are indexed? I was trying a few queries and they were timing out. I'm curious to know which columns are indexed so that I can write more efficient queries and avoid time-outs :)
Only repo_name is indexed.
Let me find the timed out queries in logs...
I cannot find your queries. Could you please post examples here, and maybe I will suggest something?
Basicaly I was trying something as simple as this in the hope of getting a sense of what the data look like and understand the schema.
SELECT * FROM github_events
WHERE created_at > '2020-11-01'
ORDER by created_at DESC
LIMIT 10
Obviously not ideal if created_at is not indexed 😄 !
Adding a new condition LOWER(repo_name) = 'facebook/react' did the trick.
Yes, the first query stopped after processing 1 TiB of data :smile:
Code: 307, e.displayText() = DB::Exception: Limit for rows or bytes to read exceeded, max bytes: 931.32 GiB, current bytes: 931.37 GiB: While executing MergeTreeThread (version 20.13.1.5366 (official build))
For future reference, here are the fields available in the ClickHouse:
action
actor_login
additions
assignee
assignees
author_association
base_ref
base_sha
body
changed_files
closed_at
comment_id
comments
commit_id
commits
created_at
creator_user_login
deletions
diff_hunk
file_time event_type
head_ref
head_sha
labels
line
locked
maintainer_can_modify
member_login
merge_commit_sha
mergeable
mergeable_state
merged
merged_at
merged_by
number
original_commit_id
original_position
path
position
push_distinct_size
push_size
rebaseable
ref
ref_type
release_name
release_tag_name
repo_name
requested_reviewers
requested_teams
review_comments
review_state
state
title
updated_at
Is the interactive dataset in clickhouse still accessible? I could not find it, just the downloaded version.
Nevermind, I just found out that I can click on the queries, edit and run them!
Yes, it is available at https://play.clickhouse.com/play?user=play#REVTQ1JJQkUgVEFCTEUgZ2l0aHViX2V2ZW50cw==