ssdb
 ssdb copied to clipboard
ssdb copied to clipboard
Published
20 hours ago •
 ideawu
ideawu
hclear , qclear 在表的数量很大时,非常慢,会卡库
在实际使用说,通过hclear清空一个具有4000万条数据的hash表时,cpu非常高,执行时间很长,整个db被卡很久。下面是ssdb的源码:
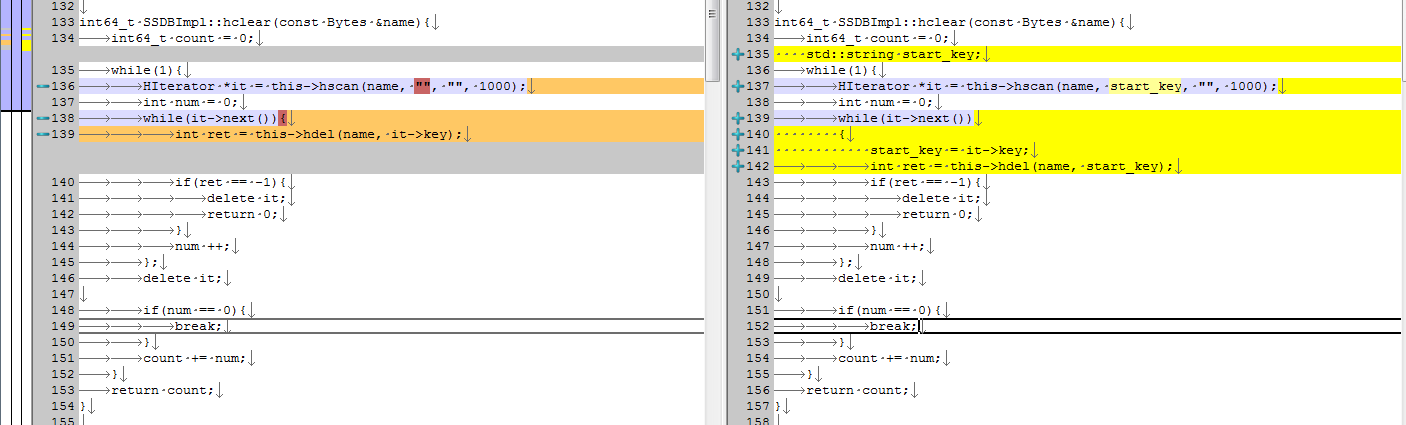
int64_t SSDBImpl::hclear(const Bytes &name){
int64_t count = 0;
while(1){
HIterator *it = this->hscan(name, "", "", 1000);
int num = 0;
while(it->next()){
int ret = this->hdel(name, it->key);
if(ret == -1){
delete it;
return 0;
}
num ++;
};
delete it;
if(num == 0){
break;
}
count += num;
}
return count;
}
通过分析上面源码以及leveldb底层源码发现,性能问题主要出在上面的hscan那行。 首先说一下leveldb的scan实现原理:
- 删除1条数据时,leveldb只是做了一个删除标记,并没有实际删除数据 2.一个1000条数据的表删除了前面999条,调用scan(name, "", "", 1000)找到第1条时,leveldb底层是需要遍历next1000次的(前面999次,判断到这些数据有删除标记,跳过)。 所以删除数据是不能减少scan内部的遍历次数的
对比上面ssdb的源码,我们通过计算发现:n条数据的表,leveldb需要遍历执行next操作的次数为: n(A1 + An)/2 (等差数列求和公式), 假设条数为1000w,那么n=10000, A1=0, An=1000w, 执行next次数为:500亿次 这个执行次数和我们期望中的1000w次相差非常大。
了解了来龙去脉,解决问题的方式就是增加一个startKey,避免每次hscan时,next操作都需要重复遍历已经删除的数据
int64_t SSDBImpl::hclear(const Bytes &name){
int64_t count = 0;
std::string start_key;
while(1){
HIterator *it = this->hscan(name, start_key, "", 1000);
int num = 0;
while(it->next())
{
start_key = it->key;
int ret = this->hdel(name, start_key);
if(ret == -1){
delete it;
return 0;
}
num ++;
};
delete it;
if(num == 0){
break;
}
count += num;
}
return count;
}
修改之后,多次测试,通过打印log,hclear删除100w条数据的表,执行时间比未修改前减少了12倍
谢谢反馈, 已经更新 hclear. https://github.com/ideawu/ssdb/commit/ff065c7d705bd7f1f9b373ad9d8a0314c6da70b9