Issue replicating the x4 RRDN weights from the sample weights
I've been having some issues trying to replicate the x4 perceptual weights from the repository. I'm using the DIV2K set for the training together with the following configuration:
import ISR
from ISR.models import RRDN
from ISR.models import Discriminator
from ISR.models import Cut_VGG19
lr_train_patch_size = 40
layers_to_extract = [5, 9]
scale = 4
hr_train_patch_size = lr_train_patch_size * scale
rrdn = RRDN(arch_params={'C':4, 'D':3, 'G':32, 'G0':32, 'T':10, 'x':scale}, patch_size=lr_train_patch_size)
f_ext = Cut_VGG19(patch_size=hr_train_patch_size, layers_to_extract=layers_to_extract)
discr = Discriminator(patch_size=hr_train_patch_size, kernel_size=3)
from ISR.train import Trainer
loss_weights = {
'generator': 1.0,
'feature_extractor': 0.0833,
'discriminator': 0.01
}
losses = {
'generator': 'mae',
'feature_extractor': 'mse',
'discriminator': 'binary_crossentropy'
}
log_dirs = {'logs': './logs', 'weights': './weights'}
learning_rate = {'initial_value': 0.0004, 'decay_factor': 0.5, 'decay_frequency': 50}
flatness = {'min': 0.0, 'max': 0.24, 'increase': 0.01, 'increase_frequency': 3}
trainer = Trainer(
generator=rrdn,
discriminator=discr,
feature_extractor=f_ext,
lr_train_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/train_lr/',
hr_train_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/train_hr/',
lr_valid_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/valid_lr/',
hr_valid_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/valid_hr/',
loss_weights=loss_weights,
learning_rate=learning_rate,
flatness=flatness,
dataname='dataset',
log_dirs=log_dirs,
weights_generator=None,
weights_discriminator=None,
n_validation=100,
)
trainer.train(
epochs=86,
steps_per_epoch=1000,
batch_size=8,
monitored_metrics={'val_generator_PSNR_Y': 'max'}
)
After just the first 10 epochs with these parameters the result reaches a PSNR of 23.9 after which is generalizes with some big dips. I have copied the parameters from the session file provided so I'm not sure why this is happening.
Do you have any idea what could be the issue here or any advice on how I can reproduce the weights from the repository?
Hi, I recommend you first train using only MSE and then add the VGG loss and GANs. In my experiments I trained for about 60 epochs with MSE (PSNR) and used this as a starting point for my different experiments. Hope this helps.
Thank you for the quick reply. I'm now trying to do as you said, but for some reason it's not saving the weights now after every epoch. Do you know why this could be? Code I'm running:
import ISR
from ISR.models import RRDN
from ISR.models import Discriminator
from ISR.models import Cut_VGG19
lr_train_patch_size = 40
layers_to_extract = [5, 9]
scale = 4
hr_train_patch_size = lr_train_patch_size * scale
rrdn = RRDN(arch_params={'C':4, 'D':3, 'G':32, 'G0':32, 'T':10, 'x':scale}, patch_size=lr_train_patch_size)
f_ext = Cut_VGG19(patch_size=hr_train_patch_size, layers_to_extract=layers_to_extract)
discr = Discriminator(patch_size=hr_train_patch_size, kernel_size=3)
from ISR.train import Trainer
loss_weights = {
'generator': 1.0,
'feature_extractor': 0.0833,
'discriminator': 0.01
}
losses = {
'generator': 'mae',
'feature_extractor': 'mse',
'discriminator': 'binary_crossentropy'
}
log_dirs = {'logs': './logs', 'weights': './weights'}
learning_rate = {'initial_value': 0.0004, 'decay_factor': 0.5, 'decay_frequency': 50}
flatness = {'min': 0.0, 'max': 0.24, 'increase': 0.01, 'increase_frequency': 3}
trainer = Trainer(
generator=rrdn,
discriminator=None,
feature_extractor=None,
lr_train_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/train_lr/',
hr_train_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/train_hr/',
lr_valid_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/valid_lr/',
hr_valid_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/valid_hr/',
loss_weights=loss_weights,
learning_rate=learning_rate,
flatness=flatness,
dataname='dataset',
log_dirs=log_dirs,
weights_generator=None,
weights_discriminator=None,
n_validation=100,
)
trainer.train(
epochs=60,
steps_per_epoch=1000,
batch_size=8,
monitored_metrics={'val_generator_PSNR_Y': 'max'}
)
Yes, this is sth I have to fix. The issue is with monitored metrics: the name changes when no discriminator is used, so you have to change it accordingly, I believe it's val_PSNR_Y. Rather dumb and not particularly useful, I'll remove it or make it fallback to any metric matching "val_*". Any PR for this is welcome, obviously.
Thanks for your help. I have finished training the weights. I used the DIV2K set and the same configuration as in the session_config from the perceptual rrdn weights, but my results don't match the ones from the repository. After training with the VGG loss and GAN the predictions all have a red dot pattern over them. Do you know what could cause this issue?
I've added an example of the red dots and the configuration I used for training.

import ISR
from ISR.models import RRDN
from ISR.models import Discriminator
from ISR.models import Cut_VGG19
lr_train_patch_size = 40
layers_to_extract = [5, 9]
scale = 4
hr_train_patch_size = lr_train_patch_size * scale
rrdn = RRDN(arch_params={'C':4, 'D':3, 'G':32, 'G0':32, 'T':10, 'x':scale}, patch_size=lr_train_patch_size)
f_ext = Cut_VGG19(patch_size=hr_train_patch_size, layers_to_extract=layers_to_extract)
discr = Discriminator(patch_size=hr_train_patch_size, kernel_size=3)
from ISR.train import Trainer
loss_weights = {
'generator': 0.0,
'feature_extractor': 0.0833,
'discriminator': 0.01
}
losses = {
'generator': 'mae',
'feature_extractor': 'mse',
'discriminator': 'binary_crossentropy'
}
log_dirs = {'logs': './logs', 'weights': './weights'}
learning_rate = {'initial_value': 0.0004, 'decay_factor': 0.5, 'decay_frequency': 50}
flatness = {'min': 0.0, 'max': 0.24, 'increase': 0.01, 'increase_frequency': 3}
trainer = Trainer(
generator=rrdn,
discriminator=discr,
feature_extractor=f_ext,
lr_train_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/train_lr/',
hr_train_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/train_hr/',
lr_valid_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/valid_lr/',
hr_valid_dir='/nfs/home1/lorenzok/image-super-resolution/dataset/valid_hr/',
loss_weights=loss_weights,
learning_rate=learning_rate,
flatness=flatness,
dataname='dataset',
log_dirs=log_dirs,
weights_generator='/nfs/home1/lorenzok/image-super-resolution/weights/rrdn-C4-D3-G32-G032-T10-x4/2021-01-12_2056/rrdn-C4-D3-G32-G032-T10-x4_best-val_PSNR_Y_epoch165.hdf5',
weights_discriminator=None,
n_validation=100,
)
trainer.train(
epochs=299,
steps_per_epoch=1000,
batch_size=8,
monitored_metrics={'val_generator_PSNR_Y': 'max'}
)
@Lorenzokrd does this happen after the initial MSE training phase too? How long did you train with MSE only?
edit: I just recognized the 165 initial epochs of MSE. Still, are these patterns visible with this initial model too?
My bad for not checking those before. Yes there also seems to be a pattern after the first 165 epochs. There are no red dots but there is a blocky pattern visible.

Do you know what could've caused this? This is my session config of the full training:
2021-01-08_1529:
discriminator: null
feature_extractor: null
generator:
name: rrdn
parameters:
C: 4
D: 3
G: 32
G0: 32
T: 10
x: 4
weights_generator: null
training_parameters:
adam_optimizer:
beta1: 0.9
beta2: 0.999
epsilon: null
batch_size: 8
dataname: dataset
fallback_save_every_n_epochs: 2
flatness:
increase: 0.01
increase_frequency: 3
max: 0.24
min: 0.0
hr_train_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/train_hr/
hr_valid_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/valid_hr/
learning_rate:
decay_factor: 0.5
decay_frequency: 50
initial_value: 0.0004
log_dirs:
logs: ./logs
weights: ./weights
loss_weights:
discriminator: 0.01
feature_extractor: 0.0833
generator: 1.0
losses:
discriminator: binary_crossentropy
feature_extractor: mse
generator: mae
lr_patch_size: 40
lr_train_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/train_lr/
lr_valid_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/valid_lr/
metrics:
generator: &id001 !!python/name:ISR.utils.metrics.PSNR_Y ''
n_validation: 100
starting_epoch: 0
steps_per_epoch: 1000
2021-01-12_2056:
discriminator: null
feature_extractor: null
generator:
name: rrdn
parameters:
C: 4
D: 3
G: 32
G0: 32
T: 10
x: 4
weights_generator: /nfs/home1/lorenzok/image-super-resolution/weights/rrdn-C4-D3-G32-G032-T10-x4/2021-01-08_1529/rrdn-C4-D3-G32-G032-T10-x4_best-val_PSNR_Y_epoch057.hdf5
training_parameters:
adam_optimizer:
beta1: 0.9
beta2: 0.999
epsilon: null
batch_size: 8
dataname: dataset
fallback_save_every_n_epochs: 2
flatness:
increase: 0.01
increase_frequency: 3
max: 0.24
min: 0.0
hr_train_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/train_hr/
hr_valid_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/valid_hr/
learning_rate:
decay_factor: 0.5
decay_frequency: 50
initial_value: 0.0004
log_dirs:
logs: ./logs
weights: ./weights
loss_weights:
discriminator: 0.01
feature_extractor: 0.0833
generator: 1.0
losses:
discriminator: binary_crossentropy
feature_extractor: mse
generator: mae
lr_patch_size: 40
lr_train_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/train_lr/
lr_valid_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/valid_lr/
metrics:
generator: *id001
n_validation: 100
starting_epoch: 57
steps_per_epoch: 1000
2021-01-13_2043:
discriminator:
name: srgan-large
weights_discriminator: null
feature_extractor:
layers:
- 5
- 9
name: vgg19
generator:
name: rrdn
parameters:
C: 4
D: 3
G: 32
G0: 32
T: 10
x: 4
weights_generator: /nfs/home1/lorenzok/image-super-resolution/weights/rrdn-C4-D3-G32-G032-T10-x4/2021-01-12_2056/rrdn-C4-D3-G32-G032-T10-x4_best-val_PSNR_Y_epoch165.hdf5
training_parameters:
adam_optimizer:
beta1: 0.9
beta2: 0.999
epsilon: null
batch_size: 8
dataname: dataset
fallback_save_every_n_epochs: 2
flatness:
increase: 0.01
increase_frequency: 3
max: 0.24
min: 0.0
hr_train_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/train_hr/
hr_valid_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/valid_hr/
learning_rate:
decay_factor: 0.5
decay_frequency: 50
initial_value: 0.0004
log_dirs:
logs: ./logs
weights: ./weights
loss_weights:
discriminator: 0.01
feature_extractor: 0.0833
generator: 0.0
losses:
discriminator: binary_crossentropy
feature_extractor: mse
generator: mae
lr_patch_size: 40
lr_train_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/train_lr/
lr_valid_dir: /nfs/home1/lorenzok/image-super-resolution/dataset/valid_lr/
metrics:
generator: *id001
n_validation: 100
starting_epoch: 165
steps_per_epoch: 1000
I cannot check the code right now, but I think you've been using the features from the VGG network too, not MSE only. If that's the case, this is kind of expected, selecting accurately the VGG features is important and they should only be used while training with GANs. Retrain from scratch using (or make sure they are deactivate)
loss_weights:
feature_extractor: 0.0
in short: initially MSE, then GANS+VGG
Further leads, in case you actually where not using these features are:
- blocky pattern can come from the upscaling layer, read the literature on checkboard patterns with deconvolutions
- use different VVG layers when training with GANs, use a mix of early and later layers as well as a few only to understand how to control them. As far as I remember using multiple layers (up to 8) delivered the best results.
Dear @cfrancesco, First, thanks for your contribution with this repository, the code is very clear and it's been really useful.
Second, I'm facing the same issue training with my own dataset. First I trained the MSE with these parameters for 100 epoch: loss_weights = { 'generator': 1.0, 'feature_extractor': 0.0, 'discriminator': 0.0 }
Then I used the val_generator_PSNR_Y_epoch as starting point for training GANS+VGG with different combinations of feature_extractor and discriminator weigths (I set the generator weight to 0). Currently, iterations of 0,1 from 0 to 1 with each parameter(feature_extractor and discriminator), this is 100 different models to be trained, currently I have results for the first 20, 50 epoch on each one. In some of them there are bad configurations of colors while others seem to be more accurate to the original image, however, in all of them those patterns are visible (see images below):

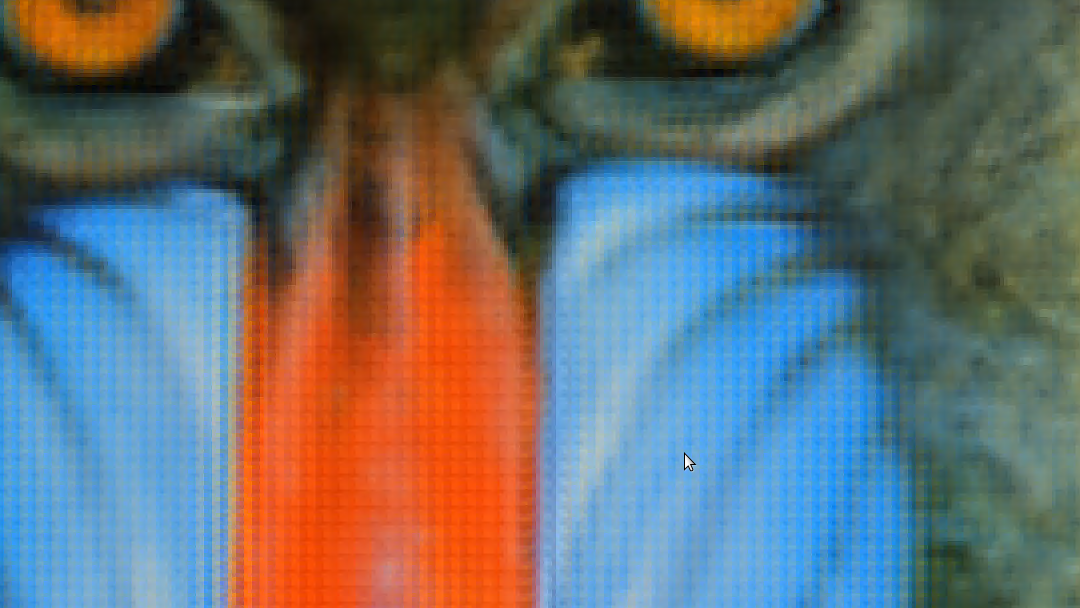
In the training with only MSE those patterns are not present or at least, are not so obvious:

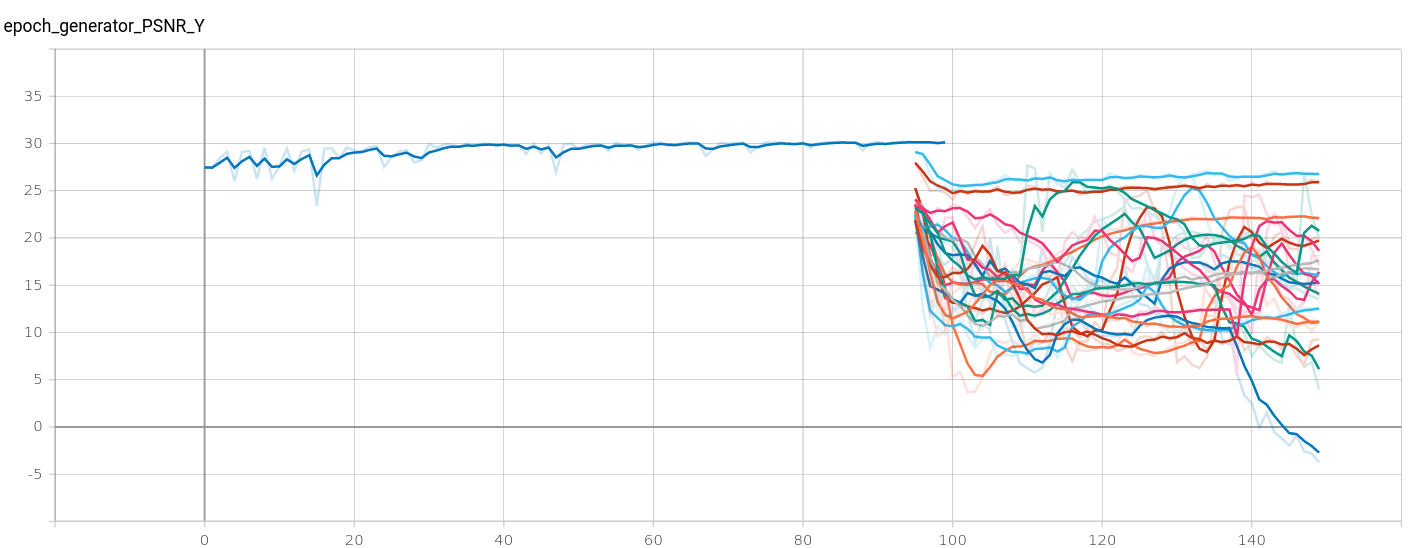
Also, according to metrics in Tennsorboard, the PSNR for MSE cant' get better than 0.30 and all the trainings with GAN+VGG have worse results and it does not seem possible to improve this value with more training:
so...any suggestions to solve this?