Establish API service needs for partial-annotation-set retrieval
This is an issue to capture the process of defining one chunk of API service needs for the Notebook and scaling:
What API service additions/changes are needed to support the Notebook and (in future) Sidebar applications so that they may retrieve a sub-set of an annotation set, instead of (as now) needing to retrieve the full set? This is necessary to scale to result sets in the thousands and larger.
This is done when needs are documented and an API surface suggested for folks to implement.
Text from an in-progress update I wrote last week for backend-folks in Slack:
Regarding fetching subsets of annotation results:
At a high level, we’re going to want the back end (API) to start doing some thinking in units of threads (in contrast and addition to individual annotations). This is probably not a surprise. We’re working through the needs and use cases in the client and Notebook, and also evaluating the scope of changes needed in the front-end code to support only loading a subset of the total annotation set—to this point, the front end has always worked with the entire applicable set of annotations, which doesn’t scale to the Notebook.
Any changes we recommend for the API have significant repercussions on the front-end logic, flow and (possibly) UI, so we are by necessity taking our time to work through this. Work is actively ongoing on a daily basis; it’s just, you know…a lotta work :).
A service that mimics the current search endpoint but returns threads is a likely direction here, where threads is (probably) a flat list of root-level “threads.” We’re working on thinking through what a “thread” might look like and contain. There’s some flexibility here, and some nuance. Should a thread resource contain any actual annotation data? Should it return a list of IDs only? How should it indicate which annotations in the thread match the current search query (versus annotations that are just “in the thread” but don’t match)? What if there is a huge number of annotations in a single thread? Can replies be batched? Should it be possible to request only the root-level annotation of the threads that match? Or maybe the root-level annotation should always be returned?
Moving away from service interface specifics (cart/horse/etc.), the kinds of questions we want to be able to answer via the API that are not currently supported:
- How many threads have one or more matches to this search query? (In addition to the total annotation results. This will allow us to know the total number of threads without having to perform the threading, which requires the entire result set).
- What is the first/nth batch of x threads and their root-level annotations that match this query? (This would allow us to show a page of “unfiltered” annotation threads, similar to the current UI behavior of the sidebar and Notebook when first launched, but lazy-load replies as needed, later).
- What is the first/nth batch of x threads that match this query, and which annotations in those threads match the query? (This will allow us to show threaded search results, as we currently do)
- How many descendants does a given thread (or annotation) have? (This allows us to retrieve part of a thread, possibly just the root-level annotation, e.g., and know how many replies it has)
Requirements as of 2021-05-26, from notes:
Goal: The frontend applications can display threaded annotation content without having to fetch the entire set of all relevant annotations, which can be very large, especially in the Notebook.
We need:
- An endpoint that is harmonized with the current annotation-search endpoint https://h.readthedocs.io/en/latest/api-reference/#tag/annotations/paths/~1search/get but returns “thread” resources instead of “annotation” resources.
- This endpoint should return a “thread” resource for every thread containing one or more annotations that match the current search criteria.
- The endpoint should also return some metadata:
- How many threads match the current search (new concept)
- How many annotations match the current search (similar to the
totalfield in the annotation-search endpoint)
- The endpoint should behave similarly to the annotation-search endpoint in terms of:
- It should be paginate-able via
search_afterandlimit(it is optional to retain the deprecatedoffsetpagination mechanism) - Threads should be sorted based on the
sortandorderparameters:- Unknown: We need to define a sorting behavior for threads that lack a root annotation (i.e. it has been deleted).
- In general, the endpoint should accept the parameters that the current annotation-search accepts.
- It should be paginate-able via
Unknown: We haven’t bottomed out on how much annotation data each thread resource should contain. Screenshots of each mode are below. How much annotation data we (functionally) need depends on the current “mode” the client is in:
-
“Root-Thread” mode: The search criteria is such that either 0 or all of a thread’s annotations will match—we’re dealing in entire threads. This is the “default” state of the Sidebar and Notebook. In the Sidebar, we’re filtering by a group+document combination by default; in the Notebook, we’re filtering by group by default.
All of the annotations in a thread always belong to the same group and document, so an entire thread either matches (every one of its annotations matches) or it doesn’t (0 do).
In this case, we may only need annotation data for the thread’s root annotation, along with metadata about how many immediate children it has—we could lazy-load the children when they’re needed, if ever (e.g. the user clicks on something to show replies).
This is the “mode” the client and Notebook are in in the vast majority of cases. If we only ever operated in this “mode”, we’d be kind of done here, but…
-
“Filtered” mode: The user is filtering on something beyond group or document (keyword, tag, user, whatever), such that 0 - n of the annotations in a given thread might match. Currently all of this filtering is done client-side, and we then display the results in a threaded context.
To support this, we will likely need more annotation data to come back with a thread resource—this is the main piece I’m still noodling through.
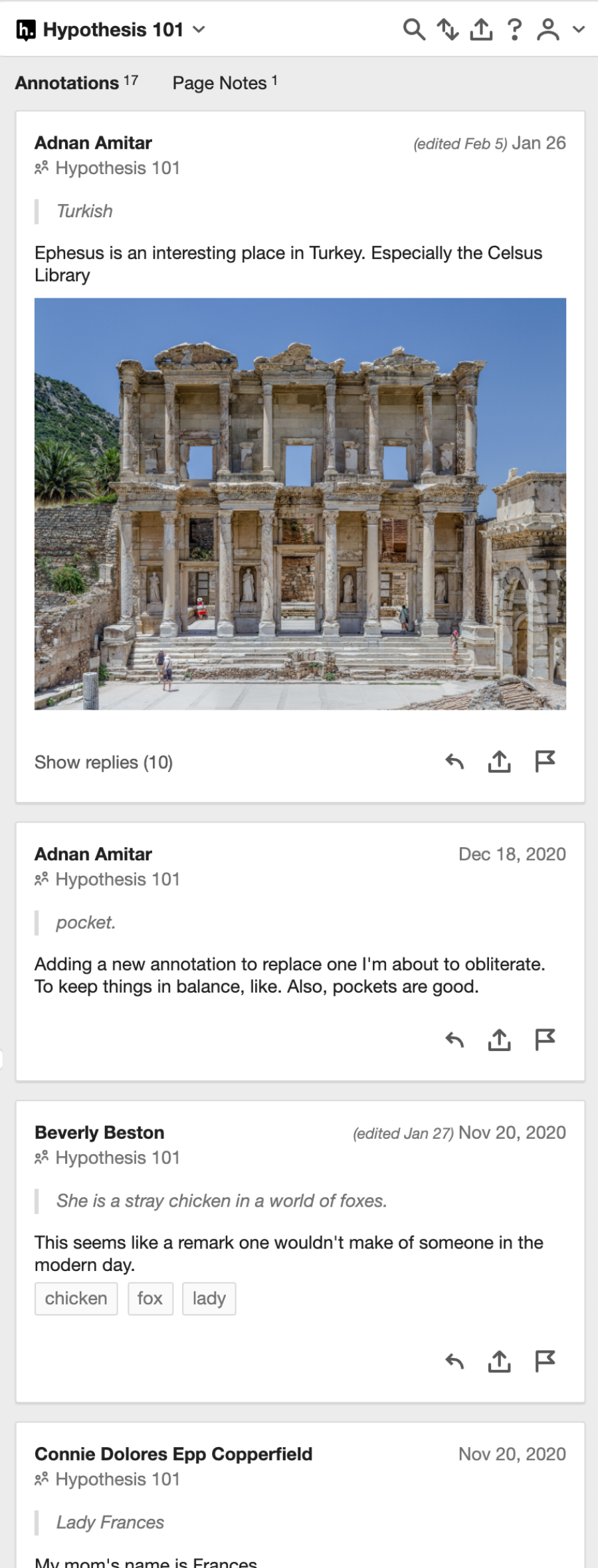
The client operating in “root-thread” (“unfiltered” mode, showing only root-level annotations in threads:
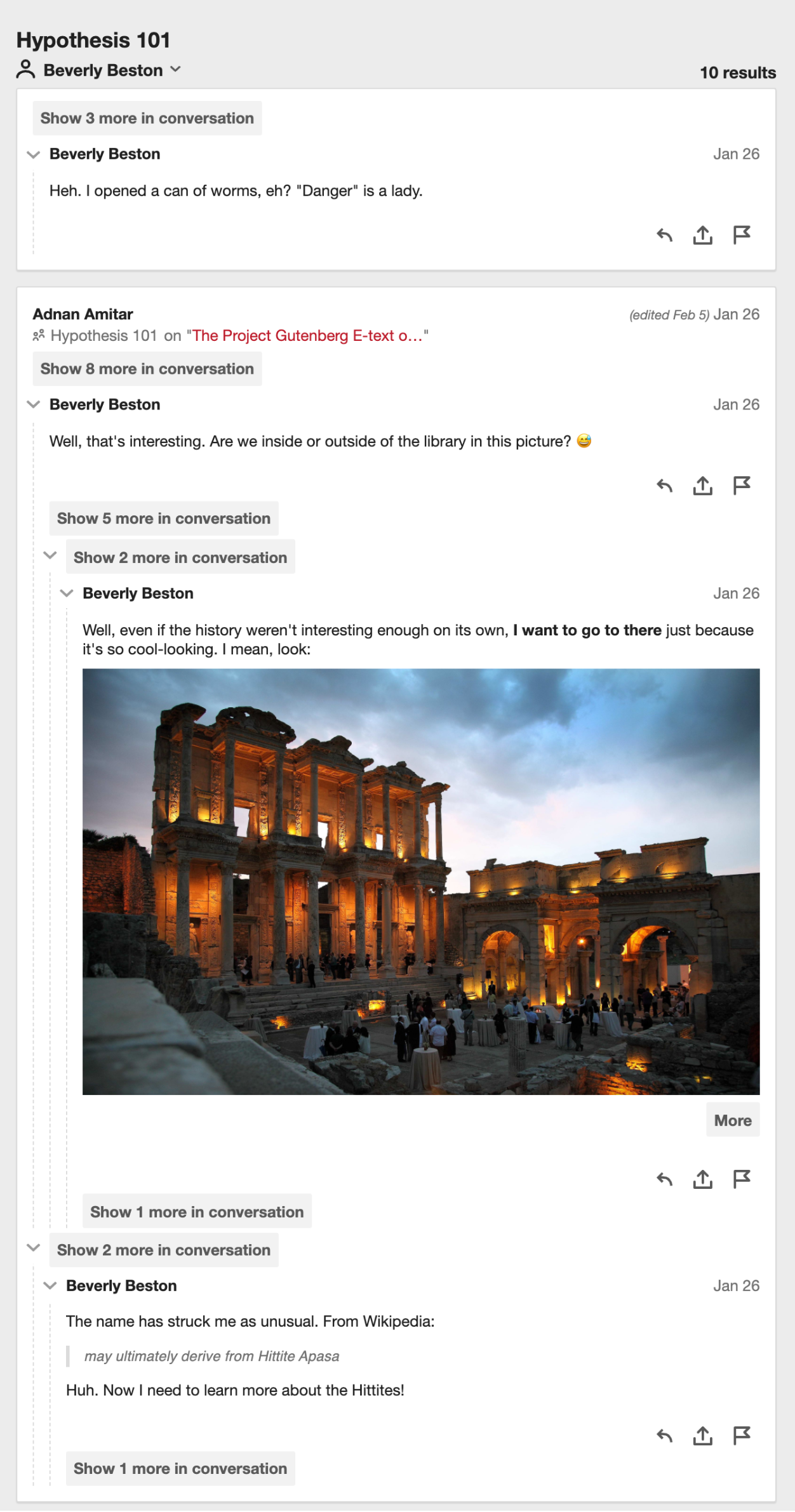
The Notebook in “filtered mode”, filtered by user, showing all annotations in a thread that match the current filter:
Update: There are still details to work out about the annotation data contained within thread resources, but enough has been scoped out here to give the team something to chew on/work on when it's time to start doing so. I will leave this issue open until we do bottom out on the annotation data question.
https://github.com/hypothesis/client/issues/3451#issuecomment-1731457508