Annotate and Highlight buttons do not appear at https://replayweb.page due to Shadow DOM
Steps to reproduce
- Navigate to https://replayweb.page.
- Activate Hypothesis Chrome Extension.
- Select any text in the viewport.
Expected behaviour
I expect that the Hypothesis Annotate and Highlight buttons should appear above or below the selected text.
Actual behaviour
No Annotate or Highlight buttons appear.
Browser/system information
Google Chrome Version 88.0.4324.96 (Official Build) (x86_64)
Additional details
I suspect that the Hypothesis client might not handle selections within shadow root nodes as desired.
Hi @matt-continuousdelta - could you email [email protected] or fill out our help form with this info? A member of our support team can help you troubleshoot from there.
Hello - As it happens another member of the Hypothesis team (👋 @esanzgar ) encountered this recently. You're right - the client doesn't currently see text selections that happen inside shadow roots. See https://github.com/hypothesis/client/pull/2926.
Ah, thanks, Rob! @matt-continuousdelta there is no need to write in to our support team in that case! I'll get this on our bug backlog.
@robertknight @esanzgar
I found some info about a proposal for a forthcoming getComposedRange API.
In the meantime, it seems like the following like this might work well enough.
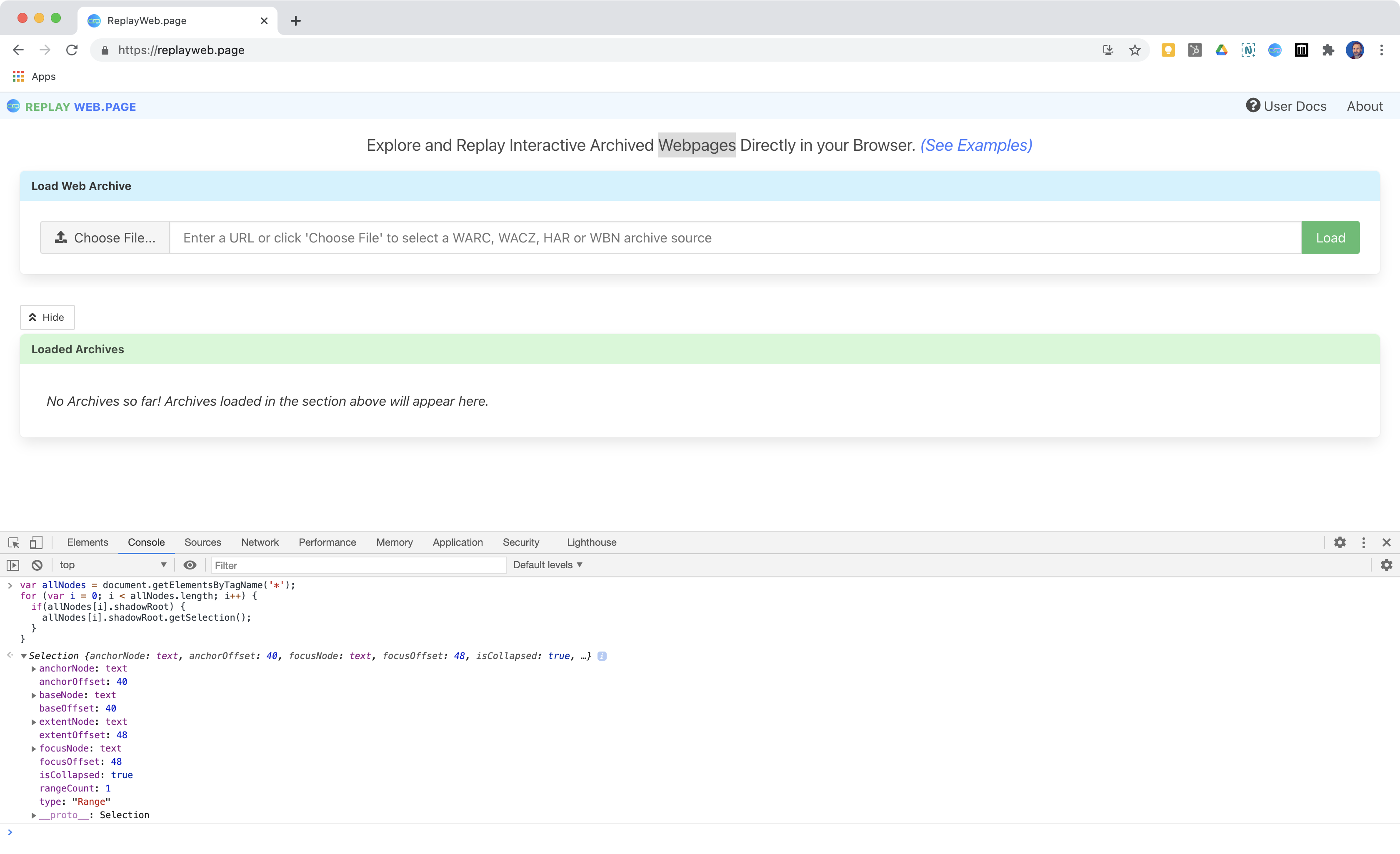
var allNodes = document.getElementsByTagName('*');
for (var i = 0; i < allNodes.length; i++) {
if(allNodes[i].shadowRoot) {
allNodes[i].shadowRoot.getSelection();
}
}
In the meantime, it seems like the following like this might work well enough.
Unfortunately the ShadowRoot.getSelection API is non-standard and not available in Safari.
In addition to resolving the issue with identifying the selection when it is in Shadow DOM, we also need to adjust the code that anchors/locates annotations in the page. None of the various anchoring mechanisms (XPath, text quote, text position) are currently aware of Shadow DOM. The main case that needs to be solved is the text quote selector. That currently uses document.body.textContent, which does not include text from shadow roots. We could walk the DOM to construct the text, including traversing into shadow roots. This could get very expensive for large documents though, compared to body.textContent, so we'll probably have to do some work to make this more efficient and/or ensure we don't block interaction while extracting the text.