OpenFGA/OktaFGA retriever to authorize user/document access when doing RAG
Opening this PR to start a discussion on best way to implement this.
First some context: OpenFGA/Okta FGA are systems to simplify authorization at scale. When implementing RAG, it is possible that not all users have access to all documents (chunks) to be retrieved. Systems like FGA (there are others beyond the ones I linked to), can help solve this problem.
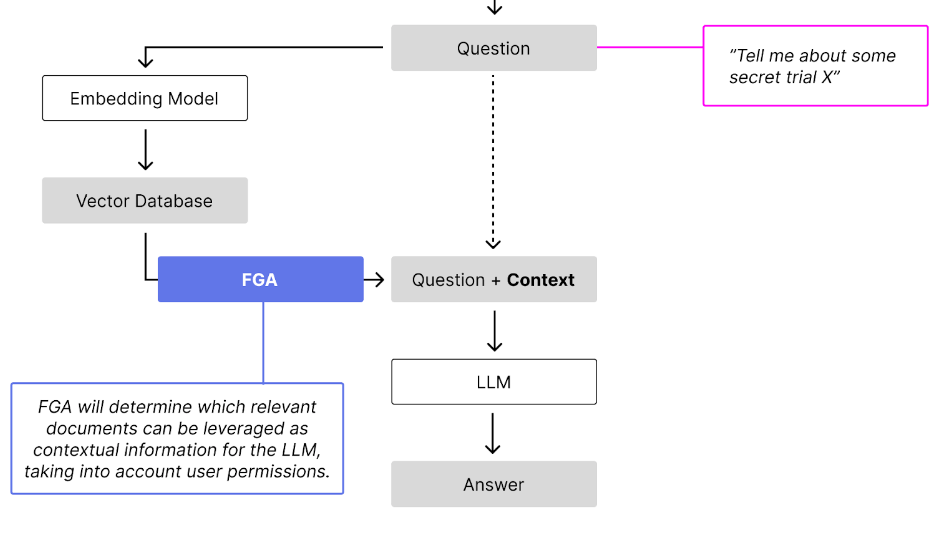
The FGARetriever implementation aims to maintain the same interface for developers doing RAG with Langchain today, but adding support for authorization. This first implementation is a basic one that can be improved over time as use of it increases.
Usage Assuming tuples are already in FGA, the retrieval logic would look like this:
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { Document } from "@langchain/core/documents";
import { OpenAIEmbeddings } from "@langchain/openai";
import { FGARetriever } from "./fgaRetriever";
import dotenv from "dotenv";
import { CredentialsMethod, OpenFgaClient } from "@openfga/sdk";
dotenv.config();
const embeddings = new OpenAIEmbeddings();
const docs = [
new Document({
metadata: {id: 'mem1'},
pageContent: 'Document related to Auth0 1',
}),
new Document({
metadata: {id: 'mem2'},
pageContent: 'Document related to Auth0 2',
}),
new Document({
metadata: {id: 'mem3'},
pageContent: 'Document related to Auth0 3',
}),
new Document({
metadata: {id: 'mem4'},
pageContent: 'Document related to Auth0 4',
}),
];
const fgaClient = new OpenFgaClient({
apiUrl: process.env.FGA_API_URL,
storeId: process.env.FGA_STORE_ID,
authorizationModelId: process.env.FGA_MODEL_ID,
credentials: {
method: CredentialsMethod.ClientCredentials,
config: {
apiTokenIssuer: process.env.FGA_API_TOKEN_ISSUER || '',
apiAudience: process.env.FGA_API_AUDIENCE || '',
clientId: process.env.FGA_CLIENT_ID || '',
clientSecret: process.env.FGA_CLIENT_SECRET || '',
},
}
});
MemoryVectorStore.fromDocuments(
docs,
embeddings
).then(vs => {
const retriever = new FGARetriever({
fgaClient,
user: 'jane',
retriever: vs.asRetriever(),
checkFromDocument: (user, doc) => ({
user: `user:${user}`,
relation: 'can_read',
object: `doc:${doc.metadata.id}`,
})
});
retriever.invoke('Auth0').then((docs) => console.log(docs));
});
To discuss
As the example above shows, to make FGARetriever filter results based on a specific user, an instance of FGARetriever needs to be created per user. This is obvious from the resulting API, but can be confusing to developers.
This can be addressed by adding a context object to both invoke and _getRelevantDocuments in BaseRetriever. So instead of
_getRelevantDocuments(_query: string, _callbacks?: CallbackManagerForRetrieverRun): Promise<DocumentInterface<Metadata>[]>;
invoke(input: string, options?: RunnableConfig): Promise<DocumentInterface<Metadata>[]>;
it'd define:
_getRelevantDocuments(_query: string, _context Map<string, any>, _callbacks?: CallbackManagerForRetrieverRun): Promise<DocumentInterface<Metadata>[]>;
invoke(input: string, context Map<string, any>, options?: RunnableConfig): Promise<DocumentInterface<Metadata>[]>;
I am not a Langchain expert, so I am open to other suggestions/alternatives. If the above makes sense I could send a PR to support that API first and then update the FGARetriever implementation based on it.
Questions
- Where should I put usage examples, in which folder? I found them in different places.
- Seems tests are skipped for other retrievers. Why is that? I'd like to add working tests but will adhere to project practices.
Thanks!
The latest updates on your projects. Learn more about Vercel for Git ↗︎
| Name | Status | Preview | Comments | Updated (UTC) |
|---|---|---|---|---|
| langchainjs-docs | ✅ Ready (Inspect) | Visit Preview | Aug 26, 2024 4:47pm |
1 Skipped Deployment
| Name | Status | Preview | Comments | Updated (UTC) |
|---|---|---|---|---|
| langchainjs-api-refs | ⬜️ Ignored (Inspect) | Aug 26, 2024 4:47pm |
Cool. I'll wait for guidelines around the implementation and then add tests + samples once there's alignment there.
Hey @dschenkelman, we unfortunately can't change the base signatures.
I think passing user into the constructor is fine - if you really wanted to you could override getRelevantDocuments (no underscore) like this:
async getRelevantDocuments(
query: string,
config?: Callbacks | BaseCallbackConfig
): Promise<DocumentInterface<Metadata>[]> {
const parsedConfig = ensureConfig(parseCallbackConfigArg(config));
const callbackManager_ = await CallbackManager.configure(
parsedConfig.callbacks,
this.callbacks,
parsedConfig.tags,
this.tags,
parsedConfig.metadata,
this.metadata,
{ verbose: this.verbose }
);
const runManager = await callbackManager_?.handleRetrieverStart(
this.toJSON(),
query,
parsedConfig.runId,
undefined,
undefined,
undefined,
parsedConfig.runName
);
try {
const user = config.configurable?. user;
// Your logic here
await runManager?.handleRetrieverEnd(results);
return results;
} catch (error) {
await runManager?.handleRetrieverError(error);
throw error;
}
}
But would be much simpler to just rely on the constructor
Hey @dschenkelman, sorry to revive an old PR!
The community package has become rather unwieldy, so generally we recommend repackaging changes like this into a standalone NPM module. You can keep this in your own GitHub repo and publish it to NPM yourself without our involvement, but to make it discoverable you can still create a PR that adds a page about it in our integration docs.
We're happy to support this in any way we can, but adding additional maintenance burden to the langchain.js monorepo currently isn't tenable for us right now.