Entropy continually increases throughout the training
Hi,
using the current implementation of the PPO using the PPOTrainer, im seeing that the entropy of the actively updated model continues to increase as the training proceeds. It seems to be making the model generate random and gibberish content, which actually is a degradation from the original model rather than an improvement.
Any idea how to prevent the learning process from allowing the entropy to increase? I thought entropy was used as part of the optimization based on the original PPO paper.
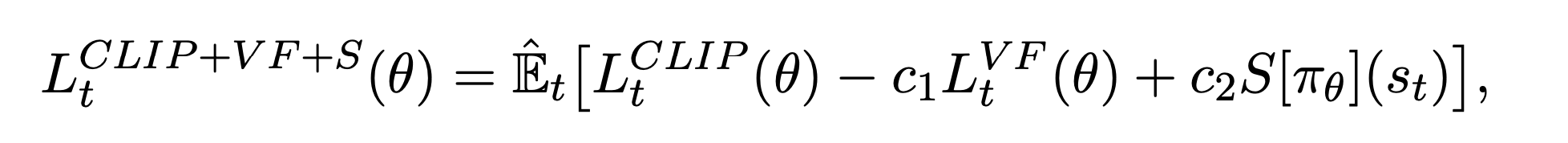
I do not seem to see entropy contributing to the current loss in this implementation.
As far as I can tell from the paper the entropy bonus is optional and not used in the experiments (see section 6.1). To avoid the model from generating gibberish TRL uses the KL penalty approach proposed by OpenAI's follow up work for tuning language models. This should prevent the model from deviating to far from the original distribution.
interestingly im still observing the training process resulting in ever increasing entropy and therefore gibberish output. What would be the parameters I should tune/update to discourage the model from increasing the entropy too much
Hard to know what could be the issue without a minimal example and some logs. Can you share a bit more?