Quantization support for heads and embeddings
Feature request
Hi! I’ve been researching LLM quantization recently (this paper), and noticed a potentially improtant issue that arises when using LLMs with 1-2 bit quantization.
Problem description :mag:
Transformers supports several great ways for quantizing transformer ‘body’, but it seems that there is no built-in way to quantize embeddings and/or lm head.
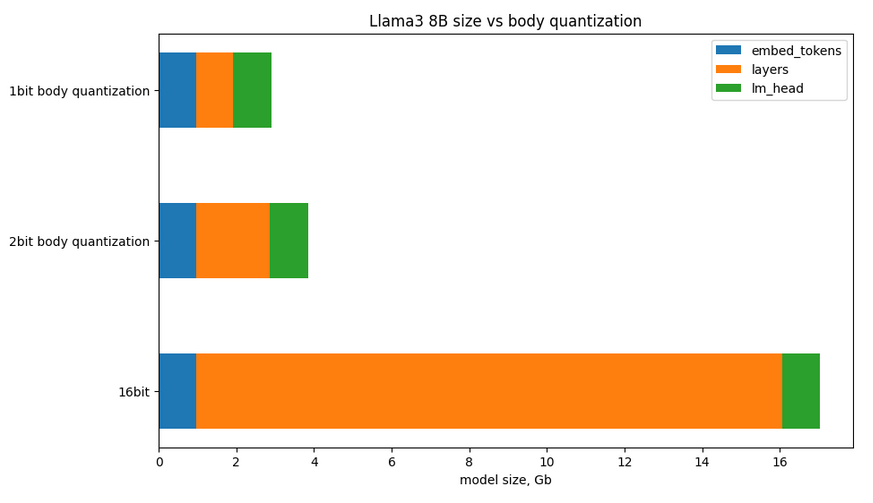
The reason why this is important is that some of the recent LLMs have very large vocabularies, and as a result, their embeddings and heads can get massive. For instance, Llama 3 has 128K token vocabulary, Qwen 2 has over 150K, Gemma 2b has 256K
As a result, if you load NF4 or AQLM quantized models, their embeddings can take up 50% or more of the model footprint. This is even more critical for lower bitwidth quantization:
Feature Request :rocket:
It would be great if transformers had a flag to quantize embeddings and heads using some of the existing quantization methods. One simple way would be to use LLM.int8 or NF4 by Tim Dettmers since transformers already supports this.
I’ve investigated how quantizing embeddings with these methods affects common models. Below is model perplexity for Llama 3 8B using AQLM+PV 2-bit quantization. I measured three configurations: fp16 embeddings, int8 embeddings and NF4 embeddings with the same parameters that transformers uses for linear layers.
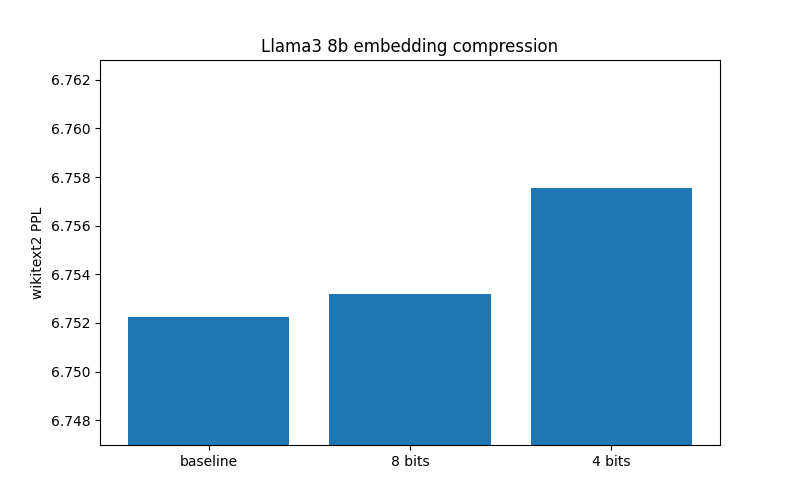
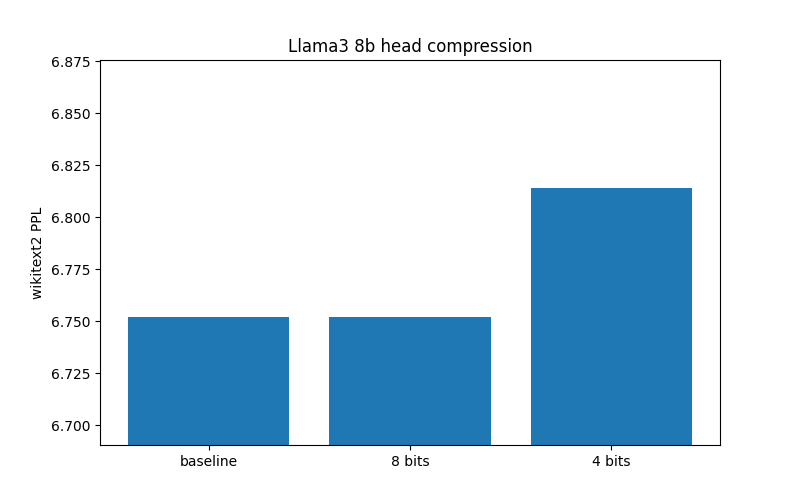
The values represent perplexity on WikiText-2 test set measured with the same protocol used in GPTQ / AQLM / QuIP# papers. The code for these measurements can be found here.
Overall, 8-bit compression looks nearly lossless, the increase in perplexity does not exceed the error you get when quantizing the transformer with the same LLM int8 codec. In turn, NF4 introduces some error (within 0.05 for Llama 3), but I would argue that this trade-off makes sense for low memory applications. Also, embeddings appear easier to quantize than heads.
Implementation details :gear:
There are multiple obstacles on the way to implementing this feature:
No support for mixed quantization
Currently, transformers does not support quantizing with multiple HfQuantizers. IMO this is a good behaviour, as interactions between different quantizators can be messy. The problem is that this feature requires for transformers library to use different compression methods for body and heads/embeddings. I think that can be solved by extending HfQuantizer interface by adding embedding/head quantization methods and adding new [embed,head]_quantization_config arguments to QuantizationConfigMixin or something in this area.
No support for embedding quantization in bitsandbytes
As far as I know, no quantization method supports nn.Embedding-like interface. I can ask bitsandbytes maintainers if they would accept a PR that fixes that.
Also, there is a caveat that some models use tied embeddings/heads, while implementing, one need to be mindful of them.
Cool things that this can enable :trophy:
If we can implement 4-bit embeddings, it will be possible to write a colab notebook that runs Llama 3 70B model on the free tier T4 GPU without offoading, by combining embedding/heads quantization and the PV-tuned model https://huggingface.co/ISTA-DASLab/Meta-Llama-3-70B-AQLM-PV-1Bit-1x16 .
Another use case is running quantized LLMs on smartphones or embedded devices: for instance, the gemma-2b can fit into 1GB RAM, but only if you quantize embeddings/heads in addition to transformer weights.
If you’re interested in making a demo out of this, I’d be excited to implement this with your review / recommendations if you prefer, or wait for you to implement it your way.
What do you think?
Motivation
We are faced with a new bottleneck in model quantization. I think we can manage to fix it
Your contribution
I can allocate my time to submitting PR, but we need to figure out what to do first
I'd suggest to introduce a quantization_map concept, that would act similarly to device_map. It would guide creation of the empty model object, and then the weights and quant-components would be loaded using standard transformers functions as parameters / buffers.
For the existing quantized models, the quantization_map would have default value like {"embedding": None, "Layers": "existing_q_method", ...}. Perhaps its values should be not just strings, but sub-dicts with quantization params.
The quantization_map would be stored and loaded from model config, similarly to quantization config
I'd also use this occasion to revive #28874 which streamlines saving format for bnb.
I also have a question about memory usage of quantizing the lm_head. I found that currently quantizing huge lm_head seems to increase the memory usage?😳I try to quantize Gemma's 256k lm_head into 4bit with AWQ but found the memory footprint increase, which didn't happen when quantizing a smaller 32k lm_head.
Because I am not an expert in quantization, could anyone explain this? I am wondering is this due to the dimension of lm_head? because for gemma, the vocab_size >> hidden_size🤔
(Please correct me if there is anything wrong with my code below)
from transformers import AutoConfig, AutoModelForCausalLM
from transformers import AwqConfig
from transformers.integrations.awq import replace_with_awq_linear
model_id = "google/gemma-2b"
# model_id = "TinyLlama/TinyLlama_v1.1"
quantization_config = AwqConfig(bits=4)
model = AutoModelForCausalLM.from_pretrained(model_id)
model, _ = replace_with_awq_linear(
model, quantization_config=quantization_config,
modules_to_not_convert=["lm_head"]
)
model.cuda()
print('Model Memory Footprint', model.get_memory_footprint(), 'bytes')
print('Model Struture: \n', model)
# Gemma-2b (256k vocab_size)
# quant everything include `lm_head` 3,399,459,840 bytes
# quant everything except `lm_head` 3,127,075,840 bytes # enable `modules_to_not_convert=["lm_head"]`
# TinyLlama-1.1b (32k vocab_size)
# quant everything include `lm_head` 799,929,088 bytes
# quant everything except `lm_head` 1,028,025,088 bytes # enable `modules_to_not_convert=["lm_head"]`
Beside, I also hope to know why you think embeddings appear easier to quantize than heads😳Could you please elaborate more on this? @galqiwi
@Orion-Zheng, this issue is a feature request, i.e. we discuss a potential future enhancement of transformers here. Your question seems important, but it is not related to this feature request, and I currently do not know enough about AWQ to help - but someone else likely does. It looks like your question may belong to the forum.
Speaking of this feature request, I am now trying to put together a minimal prototype of a quantized embedding for bitsandbytes and will be back with news (hopefully) by Thursday. If you have any tips or suggestions on how to implement this, please comment.
@Orion-Zheng, this issue is a feature request, i.e. we discuss a potential future enhancement of transformers here. Your question seems important, but it is not related to this feature request, and I currently do not know enough about AWQ to help - but someone else likely does. It looks like your question may belong to the forum.
Yes, I think my question is related to the feature request here. In my understanding, the quantization is aimed to save memory usage. But if in some huge vocabulary scenario, current quantization implementation can even increase memory usage, it means we need to double check the implementation to avoid this. Otherwise the quantization of lm_head doesn't make sense: not only increase memory usage, but also slower the inference speed due to the quant/dequant processes🤔 Please feel free to correct me if i am wrong!😃
@Orion-Zheng, this issue is a feature request, i.e. we discuss a potential future enhancement of transformers here. Your question seems important, but it is not related to this feature request, and I currently do not know enough about AWQ to help - but someone else likely does. It looks like your question may belong to the forum.
Yes, I think my question is related to the feature request here. In my understanding, the quantization is aimed to save memory usage. But if in some huge vocabulary scenario, current quantization implementation can even increase memory usage, it means we need to double check the implementation to avoid this. Otherwise the quantization of lm_head doesn't make sense: not only increase memory usage, but also slower the inference speed due to the quant/dequant processes🤔 Please feel free to correct me if i am wrong!😃
Oh I think I found the reason. For Gemma-2b and Qwen-1.5b (Small LLM + Huge Vocabulary), they share the same weight of Embedding layer with lm_head layer. Therefore when I quantize the lm_head, a new quantized lm_head was added to the original model, which lead to the increment of GPU memory usage. But for LLama-8B and Qwen2-7b, they use separated lm_head and embedding layers, so quantizing lm_head will save GPU memory usage.
Is this because use shared weight between lm_head and embedding will lead to some performance loss for LLMs?🤔So bigger model tend to use different weights?
Hi @galqiwi, thanks for the detailed report. The results you showed are very promising ! I think you have a deep understanding on how quantization is implemented in transformers and the challenges we have to add this new features. Here are a few points that we need to be careful at:
- mixed quantization : Having multiple HfQuantizers can lead to a real mess with potentials conflits between quantization methods so I would prefer not going that road for now if possible. As you suggested, we should potentially extend HfQuantizer interface instead. For the POC, I would go either with bnb, quanto or hqq as you can quantize on the fly and I would not allow serializing for now as loading the mixed quantized model can be tricky (I think that only bnb support serialization for now).
- Tied weights: As @Orion-Zheng pointed out, we need to be careful when dealing with tied weights.
- Lm-head: We put by default the
lm_headinside ofmodules_not_to_convertsince we saw that it degraded a lot the performance of the llm. However, it could make sense to quantize in higher precision or indicate that fact in our docs, so that users who wants to compress the model even further knows how to do that.
Apart from doing mixed quantization, we can also achieve the same results with our current methods if we :
- Add the possibility to quantize the embeddings -> should be fairly straightforward
- support for heterogeneous quantization (each linear can be quantized with a different precision/nb of bits). For example, HQQ integration in transformers already support that (check HqqConfig). GPTQ exl2 format is doing that and we should try to add support for that since this is quite popular.
Of course, for methods such as AQLM where we can only quantize in low bit (1/2bits), adding the mixed quantization is needed if we can't extend the method to quantize in higher precision (4/6/8 bits).
Thanks again for taking the lead on this @galqiwi and happy to discuss further to improve the design of the PR !
cc @mobicham as you might be interested
I run lm-eval with Llama3-8B-Instruct, quantizing the lm-head and the embeddings with HQQ, 4-bit, group-size=64.
It's working fine (or even better :D ).
Here's how to quantize the embedding (hacky, just for the evaluation):
dummy_linear = torch.nn.Linear(1, 1, bias=False)
dummy_linear.weight.data = model.model.embed_tokens.weight;
model.model.embed_tokens.hqq_layer = HQQLinear(dummy_linear, quant_config=quant_config, compute_dtype=compute_dtype, device=device, del_orig=False)
def embed_hqq(self, x):
return torch.nn.functional.embedding(x, self.hqq_layer.dequantize() , padding_idx=self.padding_idx)
model.model.embed_tokens.forward = lambda x: embed_hqq(model.model.embed_tokens, x)
# Cleanup
del model.model.embed_tokens.weight;
torch.cuda.empty_cache();
gc.collect();
I have a question about the use case 'running quantized LLMs on smartphones or embedded devices: for instance, the gemma-2b can fit into 1GB RAM, but only if you quantize embeddings/heads in addition to transformer weights' as claimed in @galqiwi's initial description.
During experiments with BitsandBytes and HQQ, I think although we can quantize a large lm_head (e.g. 1GB for gemma's 16bit lm_head) into lower precision, such as Linear4bit or HqqLinear, when performing the computation, we have to dequantize each layer into compute_dtype which is usually 16bit. So the memory usage of lm_head is still very large and cannot be reduced🤔For example, 4bit gemma's lm_head takes up 256MB, but during computation, it will be dequantized to 16bit as an intermediate result (1024MB), which makes the total memory usage is 256MB + 1024MB = 1280MB
Please feel free to correct me if I am wrong!
@Orion-Zheng currently, that's not the case for lm_head, because the fused gemv dequantizes the weights on-the-fly. However, it is the case for the Embedding layer. However, it's possible to have a fused kernel for the embedding layer as well.
I think for mobile, the activations would be 8-bit not 16-bit, there are some W4A8 kernels for mobile: https://app.aihub.qualcomm.com/docs/hub/api.html
@Orion-Zheng currently, that's not the case for
lm_head, because the fused gemv dequantizes the weights on-the-fly. However, it is the case for the Embedding layer. However, it's possible to have a fused kernel for the embedding layer as well. I think for mobile, the activations would be 8-bit not 16-bit, there are some W4A8 kernels for mobile: https://app.aihub.qualcomm.com/docs/hub/api.html
Thanks a lot for your explanation!
FYI, my pr to bnb got merged, now they support 0shot embedding quantization. Planning to make a pr to transformers in about a week or two with changes discussed above