Different inference results from local transformer vs inference API
System Info
I am getting two slightly different probability values when comparing inference results from the local transformer and inference API on the same sentence. I am wondering why this is happening? It only occurs for some sentences.

Moreover, the local transformer seems to select the highest probability result and return it alone compared to the API that returns a score for each label. Sometimes a score from the API is greater than 1 (have seen 9) and I am wondering why that is and am if it invalidates the results?
Cheers!
Who can help?
No response
Information
- [X] The official example scripts
- [X] My own modified scripts
Tasks
- [ ] An officially supported task in the
examplesfolder (such as GLUE/SQuAD, ...) - [ ] My own task or dataset (give details below)
Reproduction
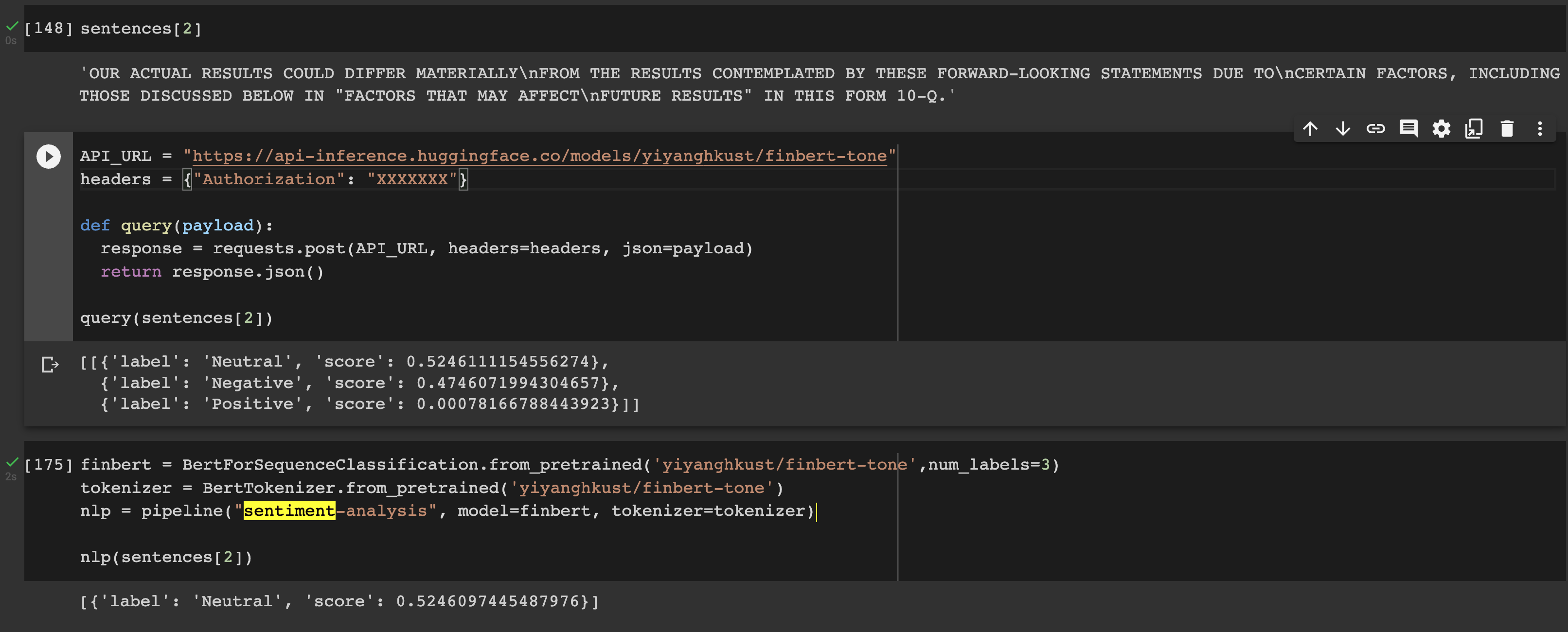
Expected behavior
Naturally I expect each version of the model to produce the same score.
Small differences in numbers can be explained by hardware, torch version etc... Nothing can be done about it.
For the difference in output the API uses a different default from the pipeline pipe = pipeline(..., topk=None) as it makes more sense for the widget to see multiple proposition.
In addition the results are sorted for the API (again for UX).
Are you able to reproduce larger than 1 results ? Seems like a pretty bad bug if true !
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the contributing guidelines are likely to be ignored.
I am having the same issue. I though it may be due to me using TF instead of pytorch, or as was suggested by hardware differences. I am however seeing bigger difference than yours, the inference api gets me some positives while the local model some (false) negatives.