pytorch-image-models
 pytorch-image-models copied to clipboard
pytorch-image-models copied to clipboard
The largest collection of PyTorch image encoders / backbones. Including train, eval, inference, export scripts, and pretrained weights -- ResNet, ResNeXT, EfficientNet, NFNet, Vision Transformer (ViT)...
**Is your feature request related to a problem? Please describe.** [ViTAE/ViTAEv2](https://github.com/ViTAE-Transformer/ViTAE-Transformer) has been open sourced, which implemented using timm. 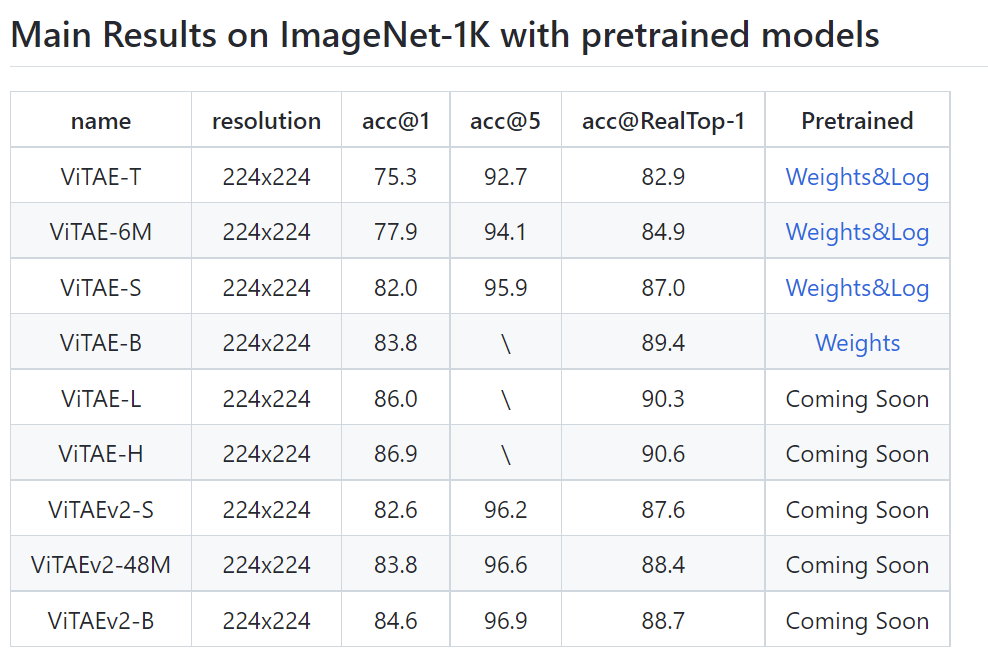
Before, the one_hot could only run in device='cuda'. Now it will run on input device automatically.
Previously, this would only log a warning. ## Motivation Calling e.g. `timm.create_model('mobilenetv3_small_075', pretrained=True)` to retrieve a pre-trained model will sometimes fail silently (or: only with a warning), potentially leading to...
Tkx for your great work, I found this repository not contain RepVGG-A0 and RepVGG-A1, could you add these models in this repository reference link [repvgg](https://github.com/DingXiaoH/RepVGG/blob/9f4de3c7a065f8d0e56ad73ee4c1f53df9e66014/repvgg.py#L196)
**Is your feature request related to a problem? Please describe.** Add support for S^2-MLP: Spatial-Shift MLP Architecture for Vision. https://arxiv.org/abs/2106.07477 **Describe the solution you'd like** A clear and concise description...

When building optimizers now, we can use the function `create_optimizer_v2` to take in keyword arguments instead of the parser arguments. This makes it easier to set up configuration files (can...
The timm library currently only has Vit and resnet as Hybrid Models. I would really love to See Swin transformers And EffNets As Hybrid ones Being added into the Library
For certain contexts, it is interesting to look at only convolution-based models (and/or compare to attention-based architectures). To facilitate this, there could be an optional column in the [CSV](https://github.com/rwightman/pytorch-image-models/blob/master/results/results-imagenet.csv) files....
I have trained model using timm distributed_train.sh, but I have 0.1 validation accuracy on imagenet. Images in validation folder are all placed in root directory going like `ILSVRC2012_val_00000001.JPEG ... ILSVRC2012_val_00050000.JPEG`....
It seems that ```VisionTransformer``` doesn't support feature extraction of all outputs in the ```forward_features``` method. Only returning of the cls token or [cls_token, distillation_token] is available [timm/models/vision_transformer.py#L291-L304](https://github.com/rwightman/pytorch-image-models/blob/23c18a33e4168dc7cb11439c1f9acd38dc8e9824/timm/models/vision_transformer.py#L291-L304). This functionality seems...
Metadata
Owner
Metadata
The largest collection of PyTorch image encoders / backbones. Including train, eval, inference, export scripts, and pretrained weights -- ResNet, ResNeXT, EfficientNet, NFNet, Vision Transformer (ViT)...