Issues with set_peft_model_state_dict, dictionary not properly updating.
So in the previous peft version, before the recent adalora changes, set_peft_model_state_dict returned a wrapped model object.
Now, it appears to function as a mutator (returns None). So I changed my code appropriately.
 I am trying to further fine-tune an existing lora adapter that I have. The problem appears to be that it's not actually updating the state_dict at all, because when I resume training, not only are all the training parameters off, but I also have a ton of dict keys that are mismatched.
I am trying to further fine-tune an existing lora adapter that I have. The problem appears to be that it's not actually updating the state_dict at all, because when I resume training, not only are all the training parameters off, but I also have a ton of dict keys that are mismatched.
 and
and
 Epoch should be 6, but thinks it's 1.3, etc
Epoch should be 6, but thinks it's 1.3, etc
Retraining the adapter from scratch does nothing. Does anyone have any ideas?
@ElleLeonne
I am checking the set_peft_model_state_dict diffs and the AdaLora changes only added an if condition that should not have broken anything as far as llama lora training goes. I'm getting more and more confused on all the peft/transformer changes recently that have broken llama code in multiple places at once.
def set_peft_model_state_dict(model, peft_model_state_dict):
"""
Set the state dict of the Peft model.
Args:
model ([`PeftModel`]): The Peft model.
peft_model_state_dict (`dict`): The state dict of the Peft model.
"""
if model.peft_config.peft_type == PeftType.ADALORA:
rank_pattern = model.peft_config.rank_pattern
if rank_pattern:
model.base_model.resize_modules_by_rank_pattern(rank_pattern)
model.load_state_dict(peft_model_state_dict, strict=False)
if model.peft_config.peft_type not in (PeftType.LORA, PeftType.ADALORA):
model.prompt_encoder.embedding.load_state_dict(
{"weight": peft_model_state_dict["prompt_embeddings"]}, strict=True
)
return model
https://github.com/huggingface/peft/blob/382b178911edff38c1ff619bbac2ba556bd2276b/src/peft/utils/save_and_load.py#L65
Wait, why does this function return a model object again? That wasn't there this morning when I was trying to debug...
Ah, I see. You just linked the Adalora change. I think at some point after that, this script got updated further, with the intent to manually go over the weights. The live version is quite different.
Hello @ElleLeonne,
We made recent changes to support multiple adapter inference and training. As such, there was a need to load the save adapters with their params in frozen mode without, that explains the all the training parameters off. To have the trainable params of adapters when loading, either set inference_mode=False in the PeftConfig or use from_pretrained method with param is_trainable=True.
I'm unable to reproduce any errors. Below are the screenshots of the code snippets along with the outputs, everything is working as expected.
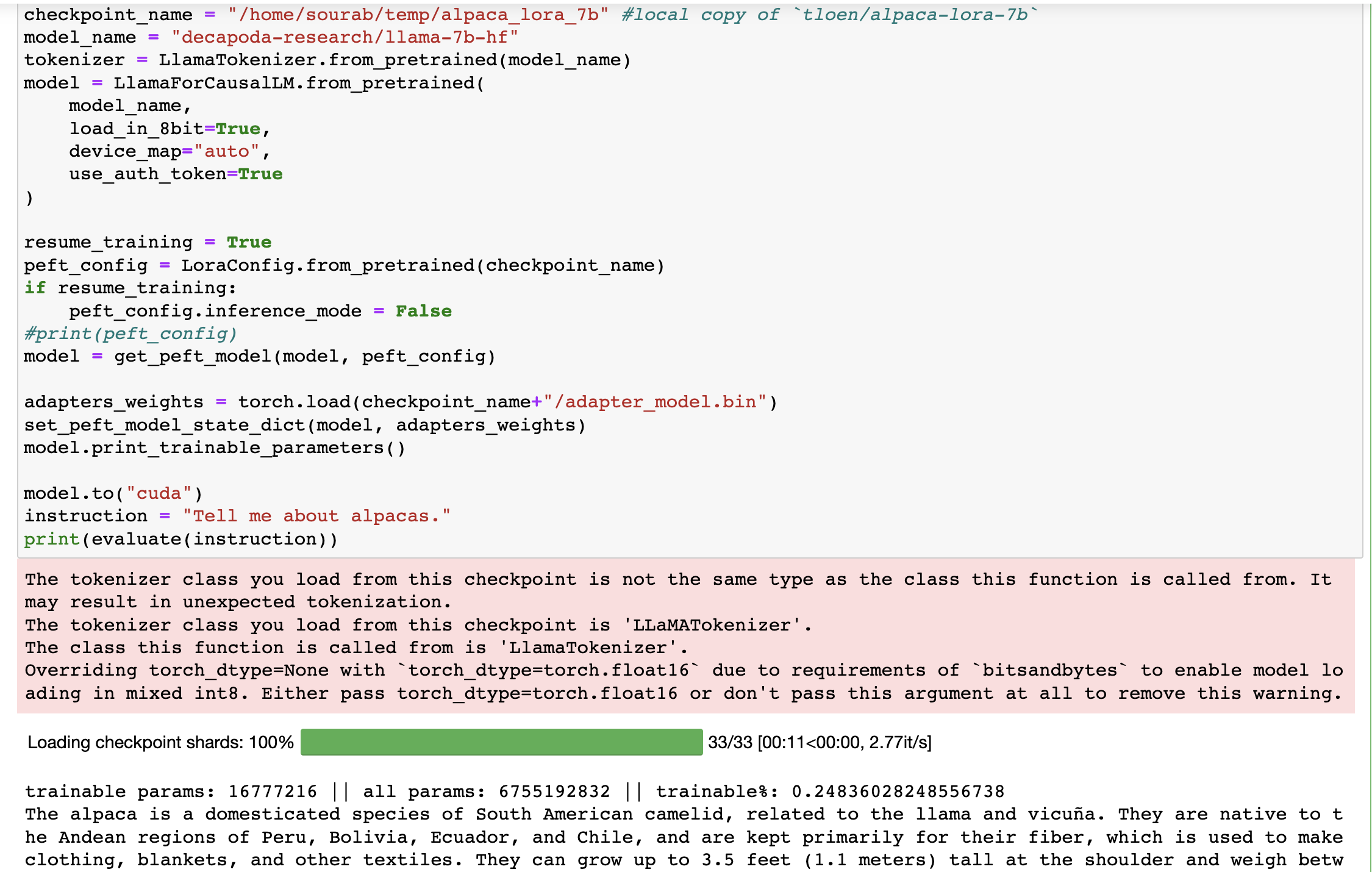
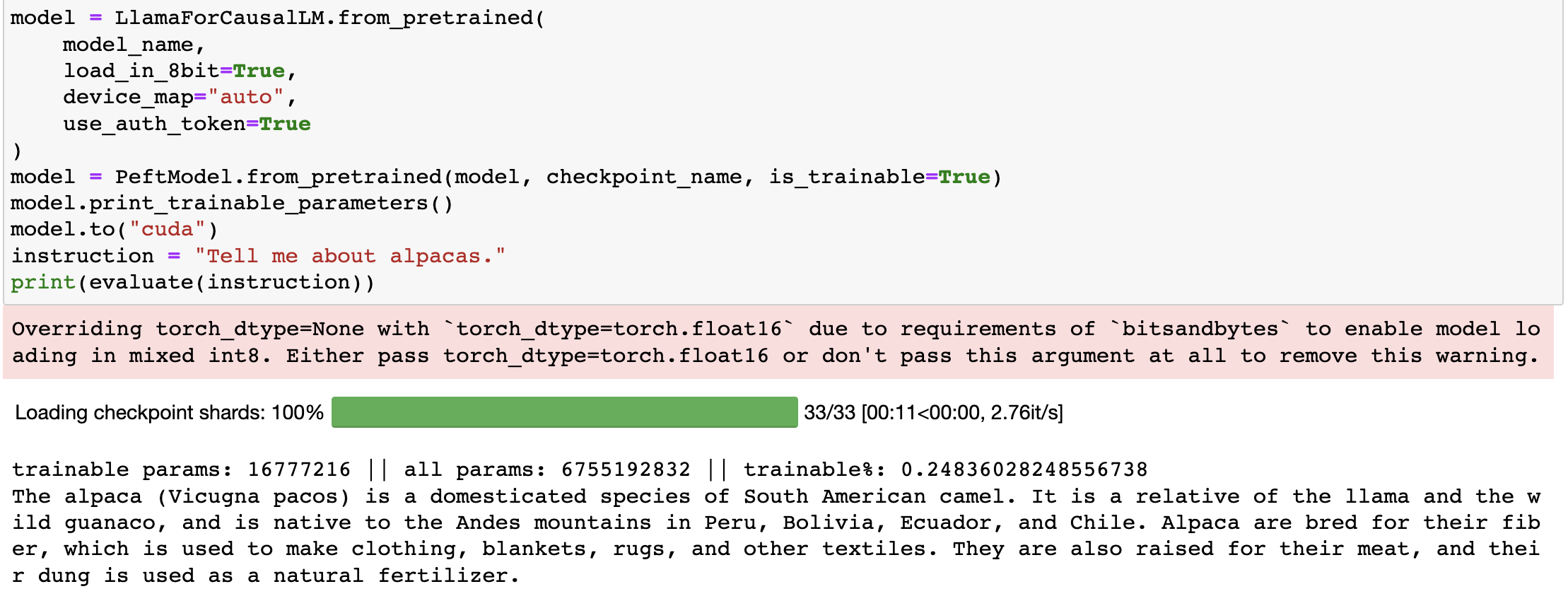
Please provide us with minimal reproducible scripts that we can execute to further deep dive and resolve the issues, if any.
@ElleLeonne, we have tried our best to not have any breaking changes, although it might be the case that some changes are breaking ones, e.g., the set_peft_model_state_dict being a mutator.
@pacman100
Alright, I've managed to reproduce it in slim form. Code is here. It's a problem with attempting to resume training from checkpoint weights, rather than from just the adapter, and it's a functionality that used to work before.
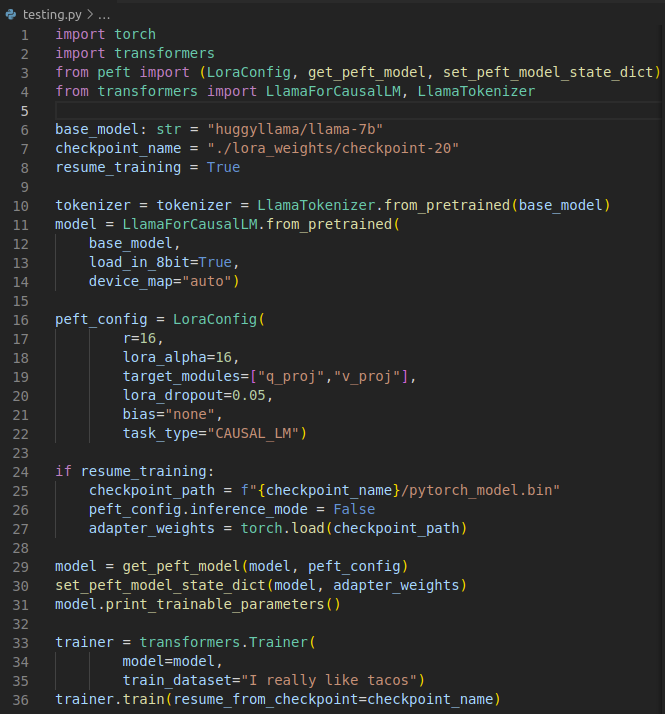 I trained a generic adapter just to produce something, then attempted to load the weights of the checkpoint file to resume training.
I trained a generic adapter just to produce something, then attempted to load the weights of the checkpoint file to resume training.
And here's your PeftModel version.
Both result in the weights issue.


The main repo also has this line of code, to rebind calls to model.state_dict to return the peft_model state_dict, but it encounters the issue either way. My pytorch_model.bin is about 37mb in size.

I'm going to work on trying to find a way to merge the weights, but if I don't provide an update, assume I haven't figured anything out yet.
Also gonna rope in @AngainorDev who made the original continue from checkpoint script.
I realize you said to ignore a "missing keys" error, but the "unexpected keys" thing seems to be a product of the recent update, and the weights don't appear to be merging right as a result.
@ElleLeonne Did you try with set inference_mode=False in the PeftConfig ? line 25 of your minimal code, try adding add peft_config.inference_mode=False
I just got home and tried it, same issue with unexpected keys. Both on my minimal script, and my live implementation
I just got home and tried it, same issue with unexpected keys. Both on my minimal script, and my live implementation
The "def get_peft_model_state_dict" is not updating as well, because the last line to_return = {k: v for k, v in to_return.items() if (("lora_" in k and adapter_name in k) or ("bias" in k))} in /peft/utils/save_and_load.py overwrites our state_dict to empty, so adapter_model.bin is also empty. Comment it, then it works fine.
@ElleLeonne Did you try with set inference_mode=False in the PeftConfig ? line 25 of your minimal code, try adding add peft_config.inference_mode=False
I tried it, it doesn't work at all.
Let me know if this PR fixes the issues: https://github.com/tloen/alpaca-lora/pull/359
https://github.com/tloen/alpaca-lora/pull/359#issuecomment-1517859182 @lywinged
I don't think so. My impression is that my use-case was misinterpreted. This allows us to load an adapter, and then train a new second adapter, rather than continuing from an old adapter. My use-case was continuing training from an old adapter, so that I didn't need to retrain a new adapter on the entire dataset every single time I acquired new data.
Loading the old adapter, and training a new adapter on a tiny amount of data breaks the new adapter.
Code is here
how to work? i mean how to predict with the new lora model.
i trained a new lora model, from llama-7b and tloen/alpaca-lora-7b, and i get a new lora model, how to add tloen/alpaca-lora-7b and my own lora model.
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.