optimum
 optimum copied to clipboard
optimum copied to clipboard
Optimum model not using all available CPU threads
System Info
- python 3.8.13
- Ubuntu 22.04
- optimum 1.3.0
- torch 1.11.0 (cpu version)
- transformers 4.21.0
- datasets 2.4.0
- onnxruntime 1.12.0
Who can help?
@philschmid
Information
- [ ] The official example scripts
- [X] My own modified scripts
Tasks
- [ ] An officially supported task in the
examplesfolder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below)
Reproduction
Run the script below to make predictions on the IMDB dataset with a pipeline. Toggle between using an optimum model and a transformers model by switching which model=... line is commented.
The transformers pipeline utilizes all CPU threads:

The optimum model does not:
import datasets
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
from optimum.onnxruntime import ORTModelForSequenceClassification
model_arch="google/bigbird-roberta-base"
max_length=4096
id2label={0: 'NEGATIVE', 1: 'POSITIVE'}
# Toggle between optimum and transformers model here ----------------------------------------
#model=AutoModelForSequenceClassification.from_pretrained(model_arch)
model=ORTModelForSequenceClassification.from_pretrained(model_arch,from_transformers=True)
# -------------------------------------------------------------------------------------------
model.config.id2label=id2label
raw_data = datasets.load_dataset("imdb",split='test').shuffle(seed=42).select(range(500))
print(raw_data)
tokenizer=AutoTokenizer.from_pretrained(model_arch,truncation=True,padding='max_length',max_length=max_length)
pipe = pipeline('text-classification',model=model,tokenizer=tokenizer)
print("Running inference...")
model_outputs = pipe(raw_data["text"])
Expected behavior
The expected behavior would be for the optimum model to behave like the transformers model and use all available CPU threads.
Hello @jessecambon
We have a PR already open and almost done which allows you to provide the session option.
- #271 this should defining the correct values you want
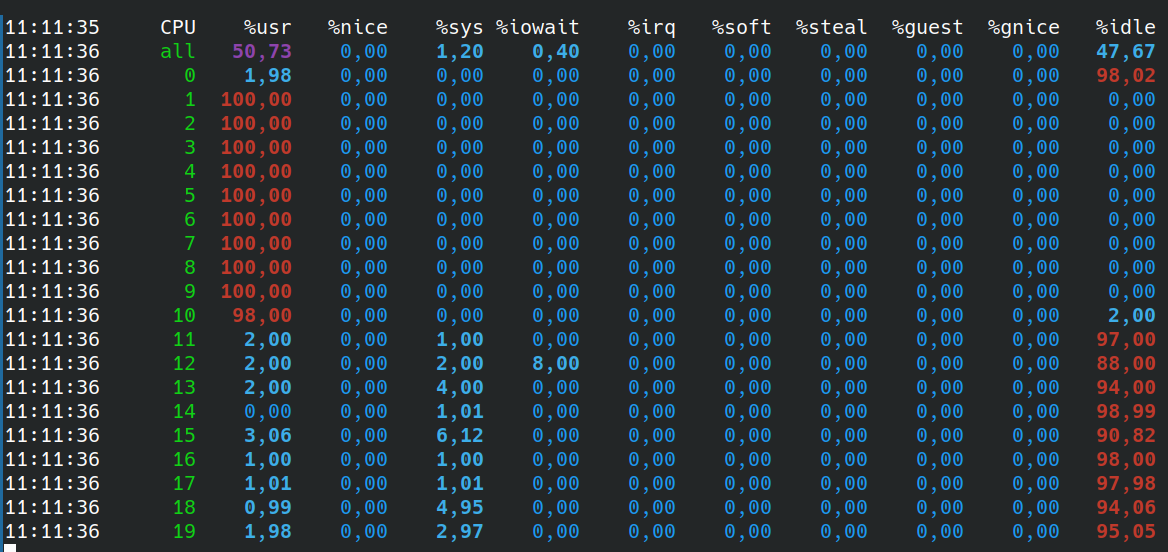
In my experience, by default onnxruntime use only physical cores, while PyTorch may use hyperthreading. For example, on my laptop with 10 physical cores (but 2 threads per core), torch.get_num_threads() gives 14 by default.
With ONNX Runtime:
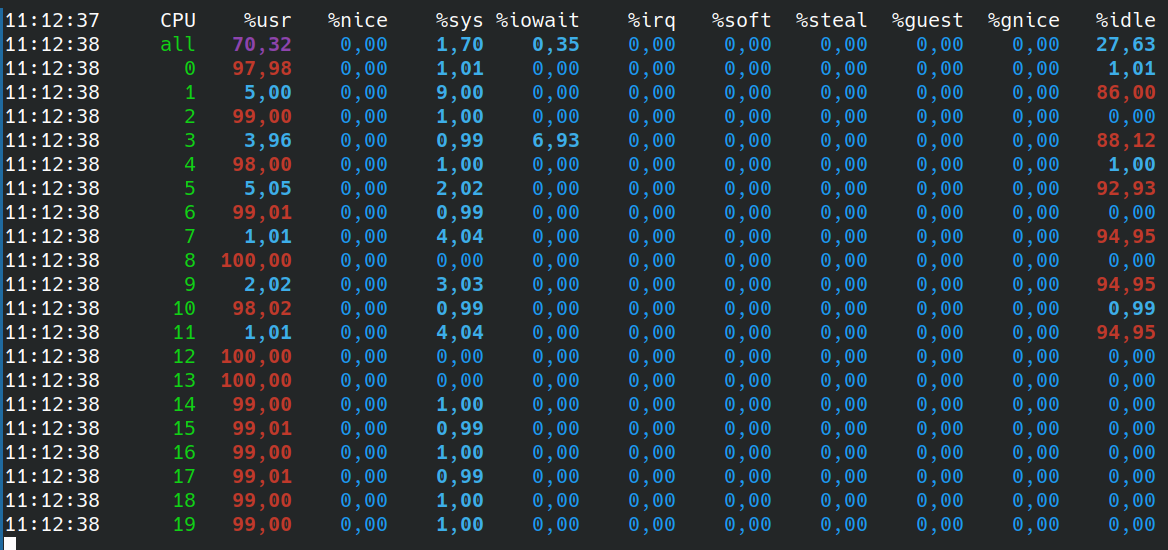
While with PyTorch:
Run with this ugly code and mpstat -P ALL 1:
from functools import partial
from optimum.onnxruntime import ORTQuantizer
from optimum.onnxruntime.modeling_ort import ORTModelForSequenceClassification, ORTModel
from optimum.onnxruntime.configuration import AutoQuantizationConfig
from transformers import AutoModelForSequenceClassification
import onnxruntime
import time
import torch
from tqdm import tqdm
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
optimum_model_path = "/path/to/model.onnx"
quantizer = ORTQuantizer.from_pretrained(model_name, feature="sequence-classification")
options = onnxruntime.SessionOptions()
ort_session = onnxruntime.InferenceSession(optimum_model_path, sess_options=options)
ort_model_eval = ORTModelForSequenceClassification(ort_session)
transformers_model_eval = AutoModelForSequenceClassification.from_pretrained(model_name)
inputs = {}
inputs["input_ids"] = torch.randint(high=1000, size=(8, 128))
inputs["attention_mask"] = torch.ones(8, 128, dtype=torch.int64)
print("Running ONNX Runtime.")
for i in tqdm(range(10)):
ort_model_eval(**inputs)
start = time.time()
for i in tqdm(range(20)):
ort_model_eval(**inputs)
print("Time using ONNX Runtime:", time.time() - start)
time.sleep(4)
print("Running ONNX Runtime.")
for i in tqdm(range(10)):
transformers_model_eval(**inputs)
start = time.time()
for i in tqdm(range(20)):
transformers_model_eval(**inputs)
print("Time using PyTorch:", time.time() - start)
Thanks for the code @fxmarty, I modified it a bit to compare a standard Onnx model to a transformers model and set the intra_op_num_threads Onnx session property. This looks like it makes Onnx use all CPU threads.
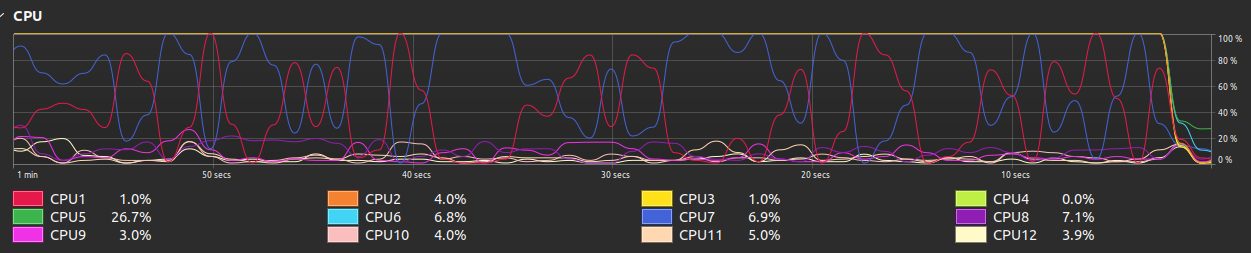
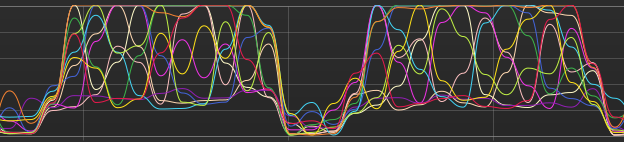
This is what the CPU utilization looked like before I set inter_op_num_threads (Onnx model is the first peak, transformers is second):
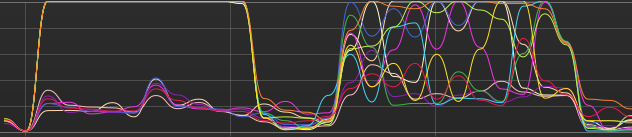
After setting intra_op_num_threads=torch.get_num_threads():
from optimum.onnxruntime.modeling_ort import ORTModelForSequenceClassification, ORTModel
from optimum.onnxruntime.configuration import AutoQuantizationConfig
from transformers import AutoModelForSequenceClassification
import onnxruntime, os, time, torch
from tqdm import tqdm
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
# where to save onnx model
onnx_dir="onnx"
optimum_model_path = f"{onnx_dir}/model.onnx"
num_threads=torch.get_num_threads()
print(f"num_threads: {num_threads}")
num_iterations = 40 # how many time to process the dummy data
# ------------------------------------------------------------------------------------------
# dummy data
inputs = {}
inputs["input_ids"] = torch.randint(high=1000, size=(8, 128))
inputs["attention_mask"] = torch.ones(8, 128, dtype=torch.int64)
# convert to onnx model and save
optimum_orig = ORTModelForSequenceClassification.from_pretrained(model_name,from_transformers=True)
optimum_orig.save_pretrained(onnx_dir)
# onnxruntime model
options = onnxruntime.SessionOptions()
options.intra_op_num_threads=num_threads
ort_session = onnxruntime.InferenceSession(optimum_model_path, sess_options=options)
ort_model_eval = ORTModelForSequenceClassification(ort_session)
# transformers model (pytorch)
transformers_model_eval = AutoModelForSequenceClassification.from_pretrained(model_name)
print('Preparing to run...')
time.sleep(4)
print("Running ONNX Runtime...")
start = time.time()
for i in tqdm(range(num_iterations)):
ort_model_eval(**inputs)
print("Time using ONNX Runtime:", time.time() - start)
time.sleep(4)
print("Running Transformers (pytorch)...")
start = time.time()
for i in tqdm(range(num_iterations)):
transformers_model_eval(**inputs)
print("Time using Transformers (pytorch):", time.time() - start)
https://github.com/huggingface/optimum/pull/271 merged, helps to fix the number of cores used