optimum
 optimum copied to clipboard
optimum copied to clipboard
How can i set number of threads for Optimum exported model?
System Info
optimum==1.2.3
onnxruntime==1.11.1
onnx==1.12.0
transformers==4.20.1
python version 3.7.13
Who can help?
@JingyaHuang @echarlaix
Information
- [ ] The official example scripts
- [X] My own modified scripts
Tasks
- [ ] An officially supported task in the
examplesfolder (such as GLUE/SQuAD, ...) - [X] My own task or dataset (give details below)
Reproduction
Hi!
I can't specify the number of threads for inferencing Optimum ONNX models. I didn't have such a problem with the default transformers model before. Is there any Configuration in Optimum?
Optimum doesn't have a config for assigning the number of threads
from onnxruntime import SessionOptions
SessionOptions().intra_op_num_threads = 1
also limiting on OS level doesn't work:
taskset -c 0-16 python inference_onnx.py
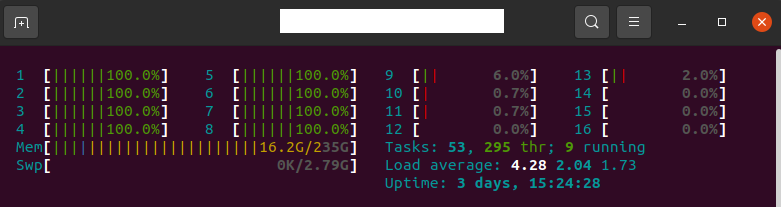
taskset -c 0 python inference_onnx.py
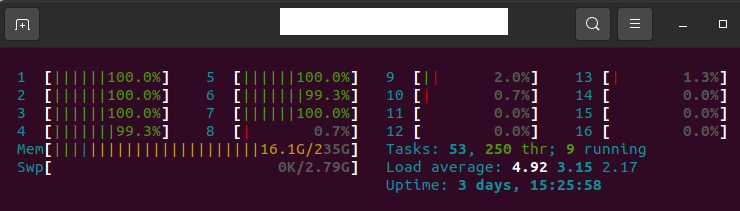
Hello @MiladMolazadeh , by coincidence I run into the same issue today!
Would https://github.com/huggingface/optimum/pull/271 solve your issue?
I propose the following workflow provided the above code is merged:
from functools import partial
from optimum.onnxruntime import ORTQuantizer
from optimum.onnxruntime.modeling_ort import ORTModelForSequenceClassification, ORTModel
from optimum.onnxruntime.configuration import AutoQuantizationConfig
import onnxruntime
import time
import torch
from tqdm import tqdm
model_name = "distilbert-base-uncased-finetuned-sst-2-english"
optimum_model_path = "/path/to/optimum_model.onnx"
optimum_quantized_model_path = "/path/to/optimum_quantized_model.onnx"
quantizer = ORTQuantizer.from_pretrained(model_name, feature="sequence-classification")
# Inference with Optimum
qconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=False)
quantizer.export(
onnx_model_path=optimum_model_path,
onnx_quantized_model_output_path=optimum_quantized_model_path,
quantization_config=qconfig,
)
options = onnxruntime.SessionOptions()
options.intra_op_num_threads = 1
ort_session = ORTModel.load_model(optimum_quantized_model_path, sess_options=options)
ort_model_eval = ORTModelForSequenceClassification(ort_session)
transformers_model_eval = AutoModelForSequenceClassification.from_pretrained(model_name)
inputs = {}
inputs["input_ids"] = torch.randint(high=1000, size=(8, 128))
inputs["attention_mask"] = torch.ones(8, 128, dtype=torch.int64)
print("Running ONNX Runtime.")
for i in tqdm(range(10)):
ort_model_eval(**inputs)
start = time.time()
for i in tqdm(range(20)):
ort_model_eval(**inputs)
print("Time using ONNX Runtime:", time.time() - start)
With this, you may use taskset to pin to specific core number, otherwise onnxruntime assigns freely intra_op_num_threads cores.
Note that this would not solve the issue in the example scripts, that make use of an older ORTModel class. If needed we could modify this one as well and add an arguments in the example scripts.