diffusers
 diffusers copied to clipboard
diffusers copied to clipboard
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX.
**Is your feature request related to a problem? Please describe.** The currently the AUTOMATIC1111/stable-diffusion-web-ui support to increase or decrease the weight of an prompt with () & [] which is...
### Describe the bug I'm trying to do inference with `StableDiffusionImg2ImgPipeline` using prompt embeddings rather than prompt as a string. I am using the [Compel](https://github.com/damian0815/compel) library to create the embeddings....
Since [Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation](https://arxiv.org/abs/2212.11565) has been there for sometime now, it'd be cool to officially have it supported from Diffusers 🧨 The best...
Thank you for your great job. It is really useful for me. I want to inference with resolution of 512x768. I know I could do that with the model trained...
### Model/Pipeline/Scheduler description From the official repository, [T2I-Adapter](https://github.com/TencentARC/T2I-Adapter) by @TencentARC is > ... a simple and small (~70M parameters, ~300M storage space) network that can provide extra guidance to pre-trained...
I want to use pyinstaller to package as exe without cmd command line 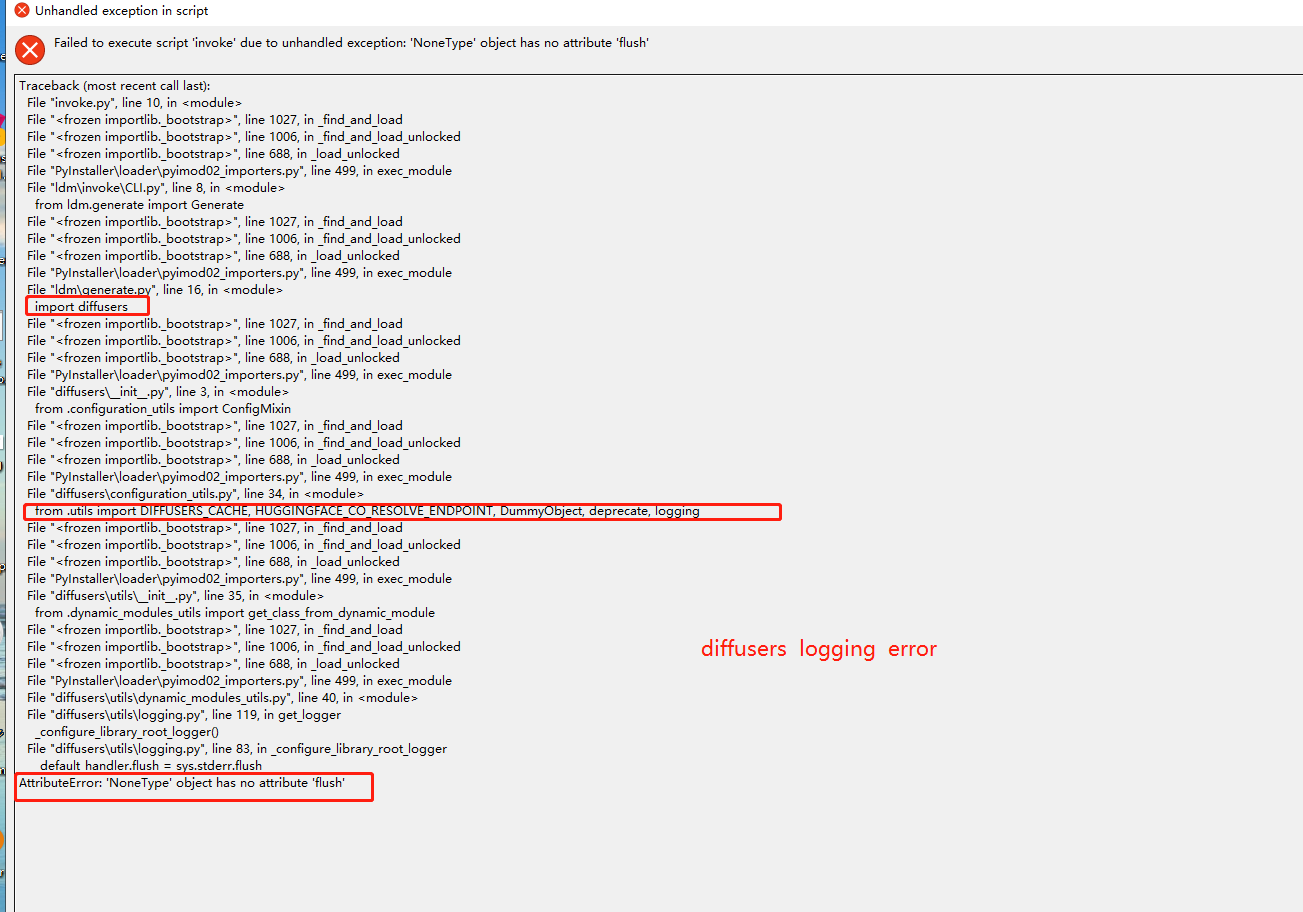
hi , I'm trying to generate an image from a prompt using the Stable-Diffusion-v1-5 model,and I'm using NVidia GeForce GTX 1650 , to create an image it's taking 4 min,...
### Describe the bug The train text to image is slower when xformers 0.0.16 is enabled (6 hours and 4 mins) vs when x formers is not used (5 hours...
train_text_to_image_lora.py faces a problem when enable_xformers_memory_efficient_attention is True

### Describe the bug Hello, When I fine tune the model using this [code](https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image_lora.py) and I enable enable_xformers_memory_efficient_attention, I face the following bug: ``` accelerator.backward(loss) File "C:\Users\Environments\StableDiffusion\lib\site-packages\accelerate\accelerator.py", line 1316, in...
### Describe the bug Following the tutorial in notebook: https://github.com/huggingface/diffusers/tree/main/examples/dreambooth with latest version of code I have follow error: ImportError: cannot import name 'ProjectConfiguration' from 'accelerate.utils' With a previous commit...
Metadata
Owner
Metadata
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX.