Wishlist: example/documentation for fine-tuning or continuing training of a model
This is more of a newby issue, but I would find it helpful if there was an example showing how to continue training from an existing checkpoint and/or start training a new model from an existing pre-trained model. I guess it is straightforward by loading the state dict of the old model, but maybe there are certain tricks or techniques that involve the scheduler settings or other issues to watch out for.
Hi @Quasimondo! You're right, simply loading the model as model.from_pretrained("path") is enough to start, but we're also working on a fine-tuning tutorial for the new Latent Diffusion models in the next release :)
Hi @anton-l, does the next release contain example training scripts for text-to-image and image-to-text similar to unconditional image generation one?
I think so too. exaple is for unconditional model(UNet2DModel) UNet2DModel doesn't seem to have a channel to receive text encoder input
I want to build pretrained UNet2DConditionModel or entire StableDiffusionPipeline. (I think text encoder is perfect, I want to control the taste of the output, For example, output an image specialized for Pokemon images.) I'm looking forward to the next release.
@sameeravithana @maito1201 the conditional scripts are still on our TODO, but feel free to contribute a PR if you've started working on it!
@anton-l thank you for the advice. Unfortunately I don't understand all the things TODO to train. If you welcome a broken code snippet with FIXME comment, I will create a pull request.
Hi @anton-l @maito1201, happy to help too if there are any FIXME, on my side I would like to further train on a custom dataset !
@PierreChambon thanks for your comment.
I've wrote it. https://github.com/huggingface/diffusers/pull/342
Pinging @patil-suraj here - do we have good docs for the fine-tuning example?
We have a working fine-tuning exampe here https://github.com/huggingface/diffusers/tree/main/examples/text_to_image#stable-diffusion-text-to-image-fine-tuning which shows how to fine-tune text conditioned models. The readme has command which shows how to run the example but it's not very detailed.
I would be happy to write a detailed post/doc if there's a interest in it :) Also if anyone is interested in doing this or collaborating in this let me know, happy to help :)
@patil-suraj
Thank you for the awesome fine-tuning example https://github.com/huggingface/diffusers/tree/main/examples/text_to_image
I tried the u-net fine-tuning on our dataset, but weirdly the training loss went up.
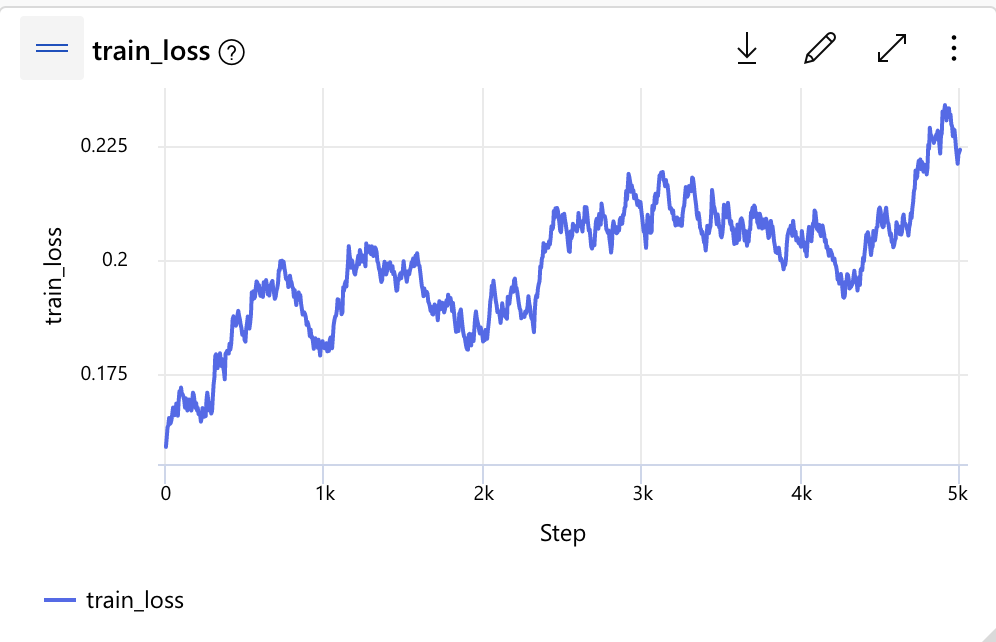
Do you have the training loss curve from your training? Curious to hear your experience.