diffusers
 diffusers copied to clipboard
diffusers copied to clipboard
How to - Image2Image with (Image + Text) Guided!
I've an image with target object. And I like to generate new image with text-guided background with the target object in a natural view. In short
- An image with target object (i.e. car).
- Complex backgrouond removed by Model A.
- Then pass it to Model B with text / prompt.
- Generate new images with different poses of the target object with new background defined by prompt.
Here, I'm looking for Model B. Can it be achieved with diffusers? Any pointer?
Interesting! Maybe this could work: https://github.com/huggingface/diffusers/issues/1305 -> we should have it somewhat soon :-)
Wow, you're right. Though the pose of the target object is fixed but this is pretty close.
https://arxiv.org/pdf/2211.07825.pdf

This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the contributing guidelines are likely to be ignored.
Still open for any suggestion and recommendation. ( no github-action bot please, 🔕 )
BTW, Stable Diffusion Depth Estimation should work quite well for this: https://huggingface.co/stabilityai/stable-diffusion-2-depth
@patrickvonplaten https://twitter.com/matthieurouif/status/1589539286814461953
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the contributing guidelines are likely to be ignored.
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the contributing guidelines are likely to be ignored.
Candidates: https://huggingface.co/docs/diffusers/using-diffusers/controlling_generation
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the contributing guidelines are likely to be ignored.
CC @patrickvonplaten
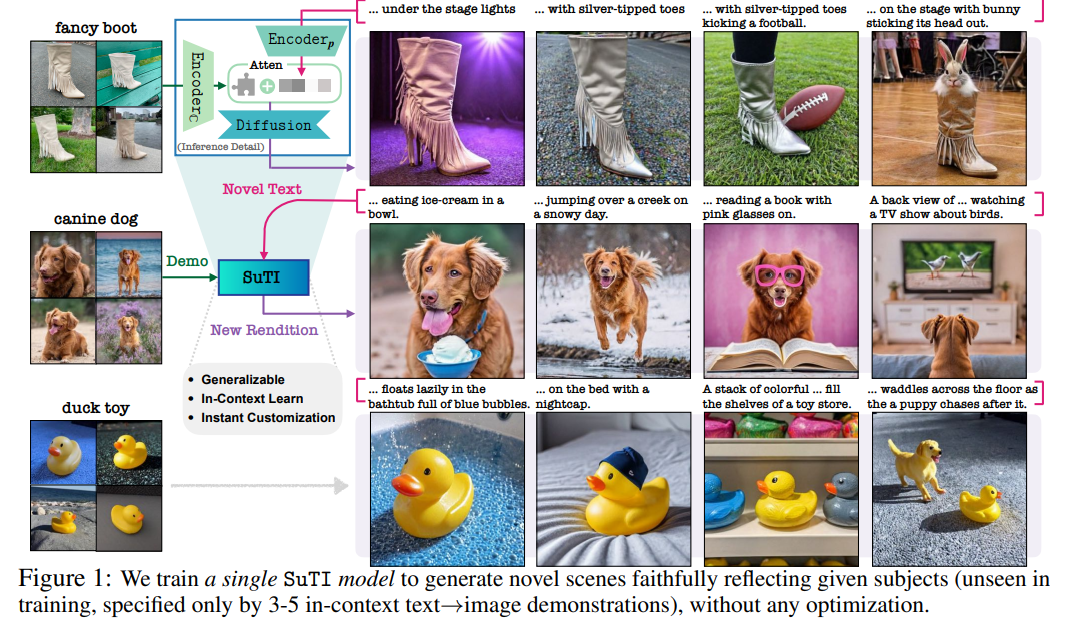
Subject-driven Text-to-Image Generation via Apprenticeship Learning https://arxiv.org/abs/2304.00186#
This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.
Please note that issues that do not follow the contributing guidelines are likely to be ignored.