spnas: FileNotFoundError: 'workers/serial/1/model_1.pth'
hi, I'm running:
vega ~/v/examples/nas/sp_nas/wf_spnas.yml --modify --batch_size 2
but during each experiment, I got:
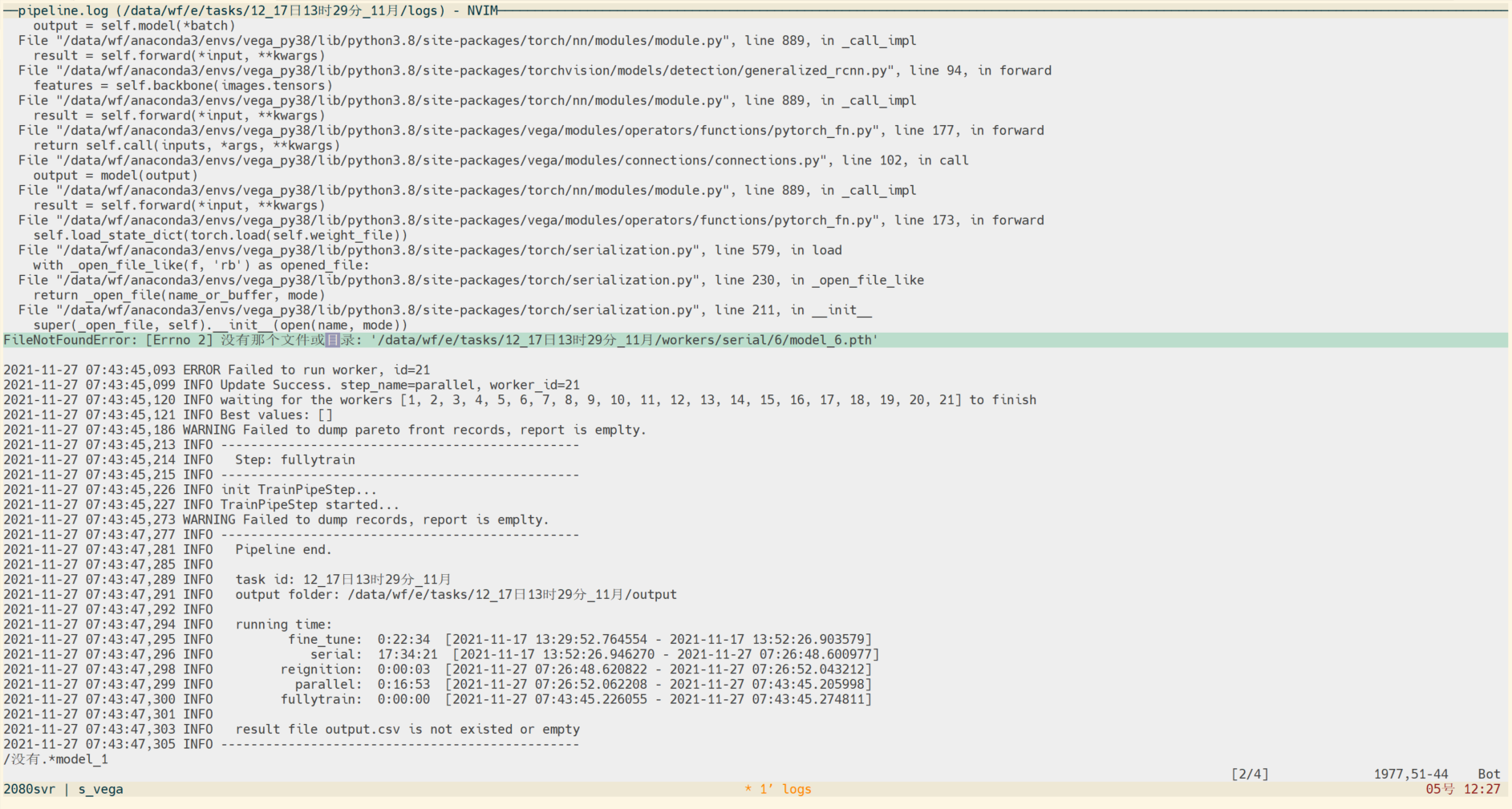
FileNotFoundError: [Errno 2] 没有那个文件或目录: '/data/wf/e/tasks/12_17日13时29分_11月/workers/serial/1/model_1.pth'
How to fix it?
Thx!
请问这个错误是因为imageNet数据集的结构不对吗?
数据集从这里下载的:
https://www.kaggle.com/c/imagenet-object-localization-challenge/data?select=imagenet_object_localization_patched2019.tar.gz
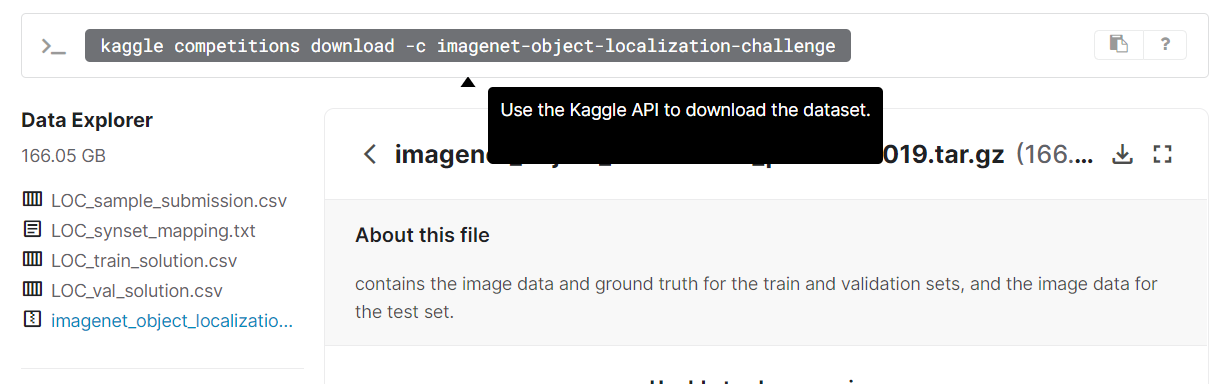
结构:
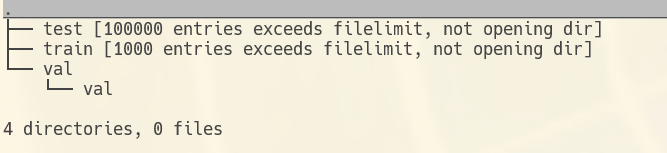
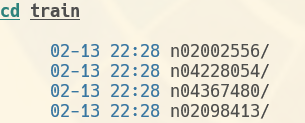
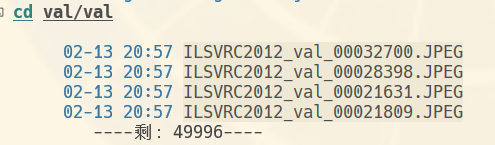
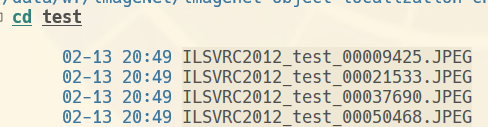
(如果val下不多建一级val, 会报错, 说找不到图片啥的)
这几个文件, 除了pipeline.log, 都是空的

@sisrfeng 这是没有找到serial阶段生成的模型,你看下这个目录下有没有model_1.pth,另外,为什么你的task目录下的子目录名称是中文?时区有关?

这个问题解决了, FileNotFoundError: [Errno 2] 没有那个文件或目录: '/data/wf/e/tasks/12_17日13时29分_11月/workers/serial/1/model_1.pth'
没记错的话, 解决方法是:
在val下多建一级val,
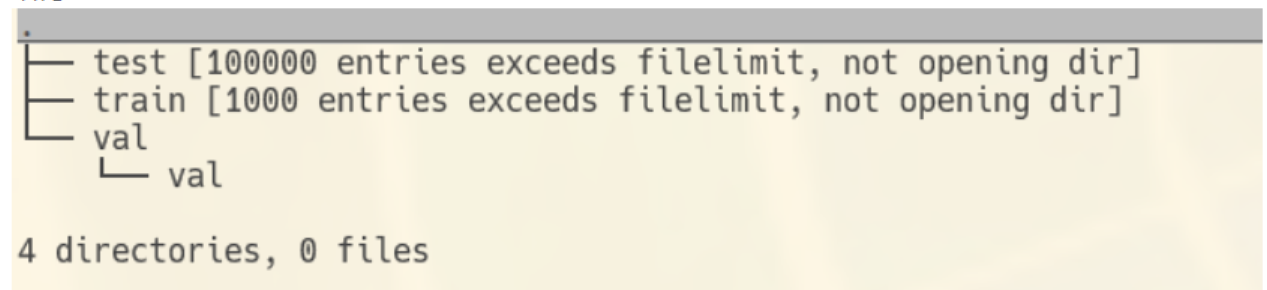
现在能找到serial下的model1.pth等
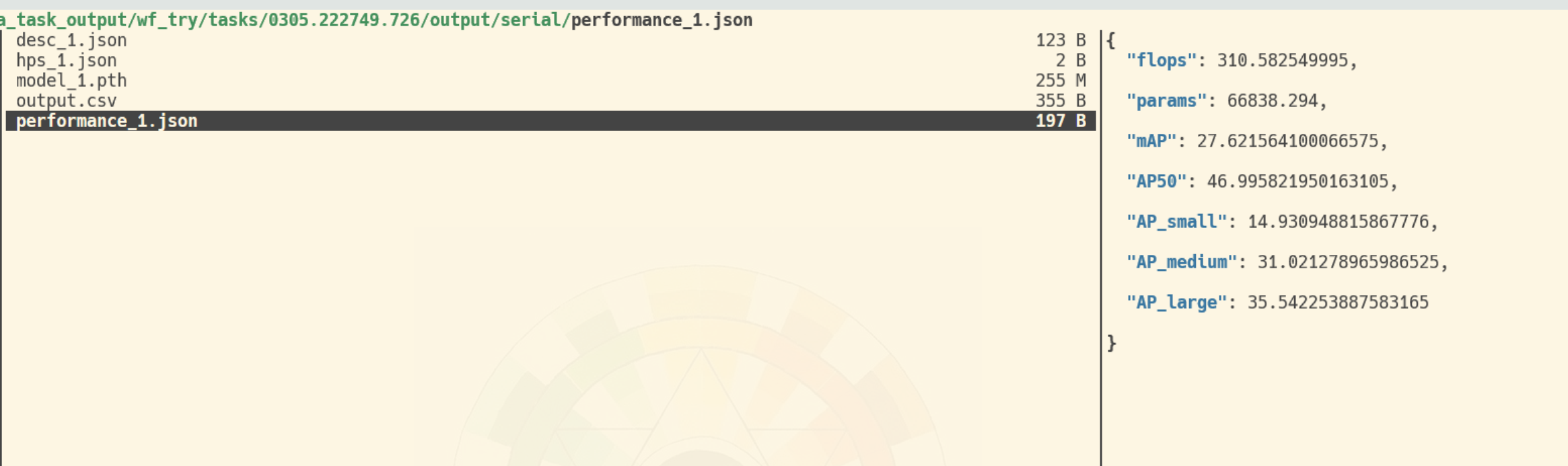
中文目录: 这是因为我改过conda环境里的源码, ( 原来的日期, 一堆数字, 不好辨认)

现在这个问题怎么搞呢?
由于torchvision版本更新的原因,最新版本的torchvision中的fasterRCNN需要手动转换下roi_pooler,如果你的torchvision版本较低,可以删除 vega.networks.faster_rcnn下的如下部分,使用 super(FasterRCNN, self).__init__(backbone_neck, num_classes, **kwargs)即可:
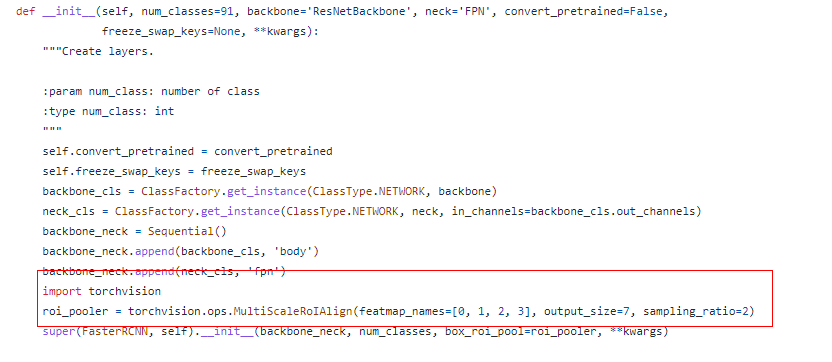
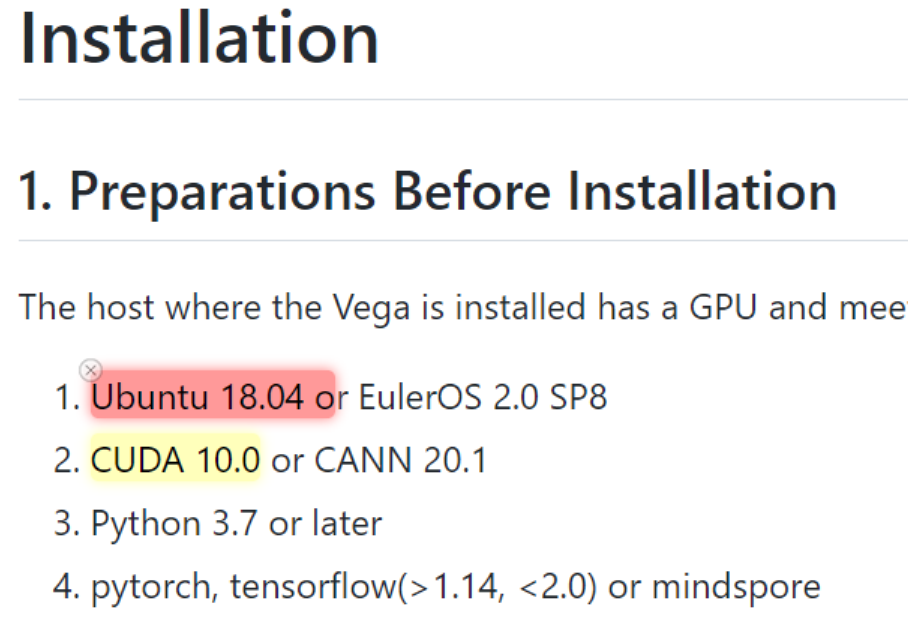
我用python3.9.7 装的是最新的stable版: conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
无论是否修改这里: anaconda3/envs/py39_torch111/lib/python3.9/site-packages/vega/networks/faster_rcnn.py
都是一样的错误.

请问怎么解决呢?
conda create --name py39_torch1_8_0 python==3.9
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forge
没改vega代码, 还是出错:

跟ImageNet的目录结构有关吗?
请问这个错误是因为imageNet数据集的结构不对吗?
数据集从这里下载的: https://www.kaggle.com/c/imagenet-object-localization-challenge/data?select=imagenet_object_localization_patched2019.tar.gz
结构:
(如果val下不多建一级val, 会报错, 说找不到图片啥的)
这几个文件, 除了pipeline.log, 都是空的
这是检测网络,用的数据集是COCO2017:https://cocodataset.org/#download vega暂不支持VOC格式的数据集。 第三阶段用ImageNet数据集做重燃,防止backbone的精度丢失过大,用标准的ImagneNet数据集:https://image-net.org/challenges/LSVRC/index.php
谢谢~
- 我用的确实是coco2017, 之前跑过CenterNet等模型, 没有出现问题
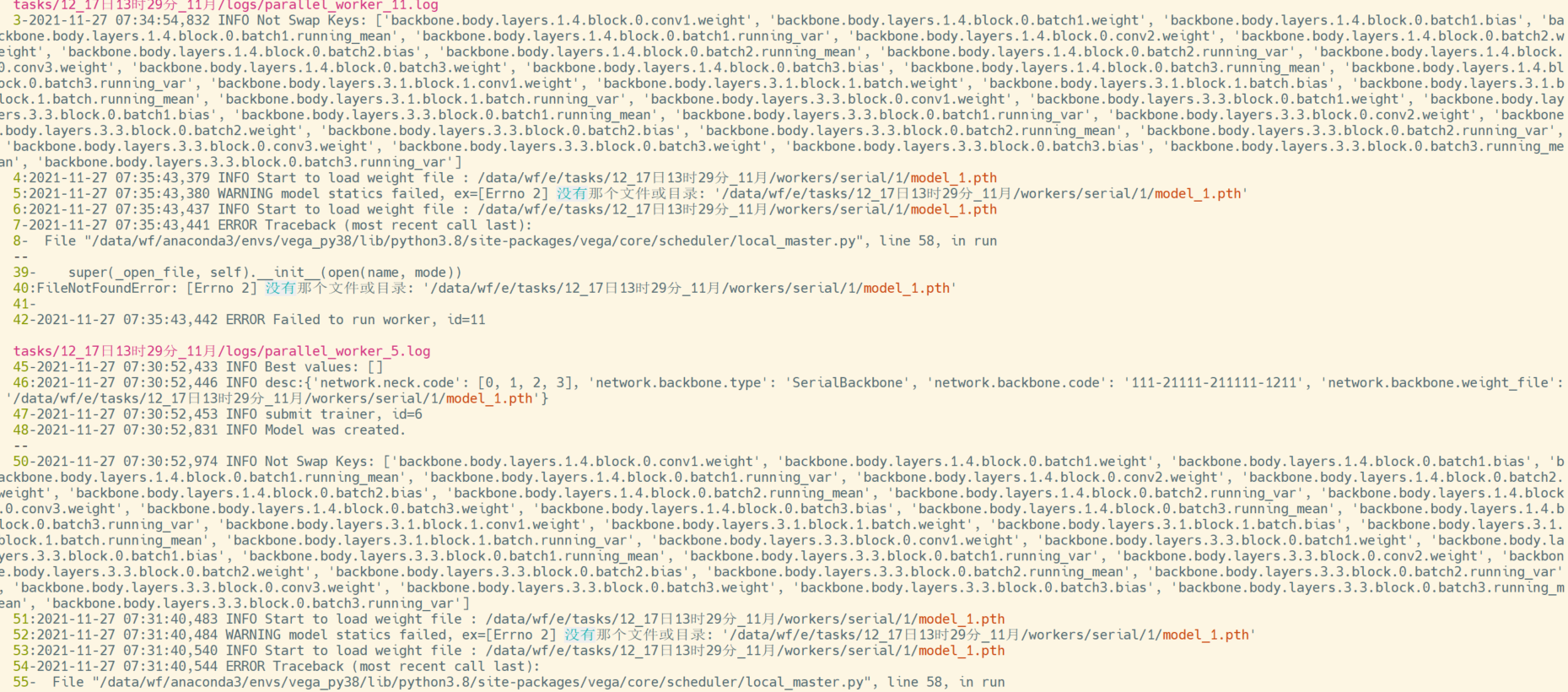
- ImageNet现在应该是把数据放到Kaggle托管了, 我从ImageNet官网的链接跳过去的. 下载的文件, 有val和train目录. train目录下还有目录, val下却没有再分目录, 所有图片混在一起. 应该是这原因 导致了下面这个问题: FileNotFoundError: [Errno 2] 没有那个文件或目录: '/data/wf/e/tasks/12_17日13时29分_11月/workers/serial/1/model_1.pth'
我的解决方法是: 在val下多建一级val 请问你们在实验时, 有这么处理吗?
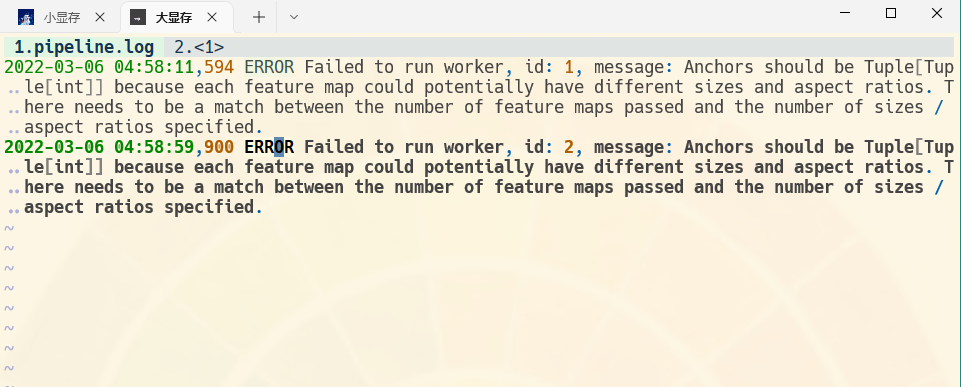
关于这个错误:

我找到的线索:



但还是不知道怎么解决, 可以再帮忙看看吗?
我们的imagenet数据集下分了val和val_unsorted两个目录,结构如下: val/n01797xxx/xxx.jpeg, val_unsorted/val/xxx.jpeg.
至于你的错误,我们还未重现过,你方便的话可以把日志级别调成debug级别,然后把pipeline.log发给我们。
调整日志级别,修改yml配置:
general:
logger:
level: debug
再请教下log的问题:
log的level还没到debug, 就已经这么多记录了:
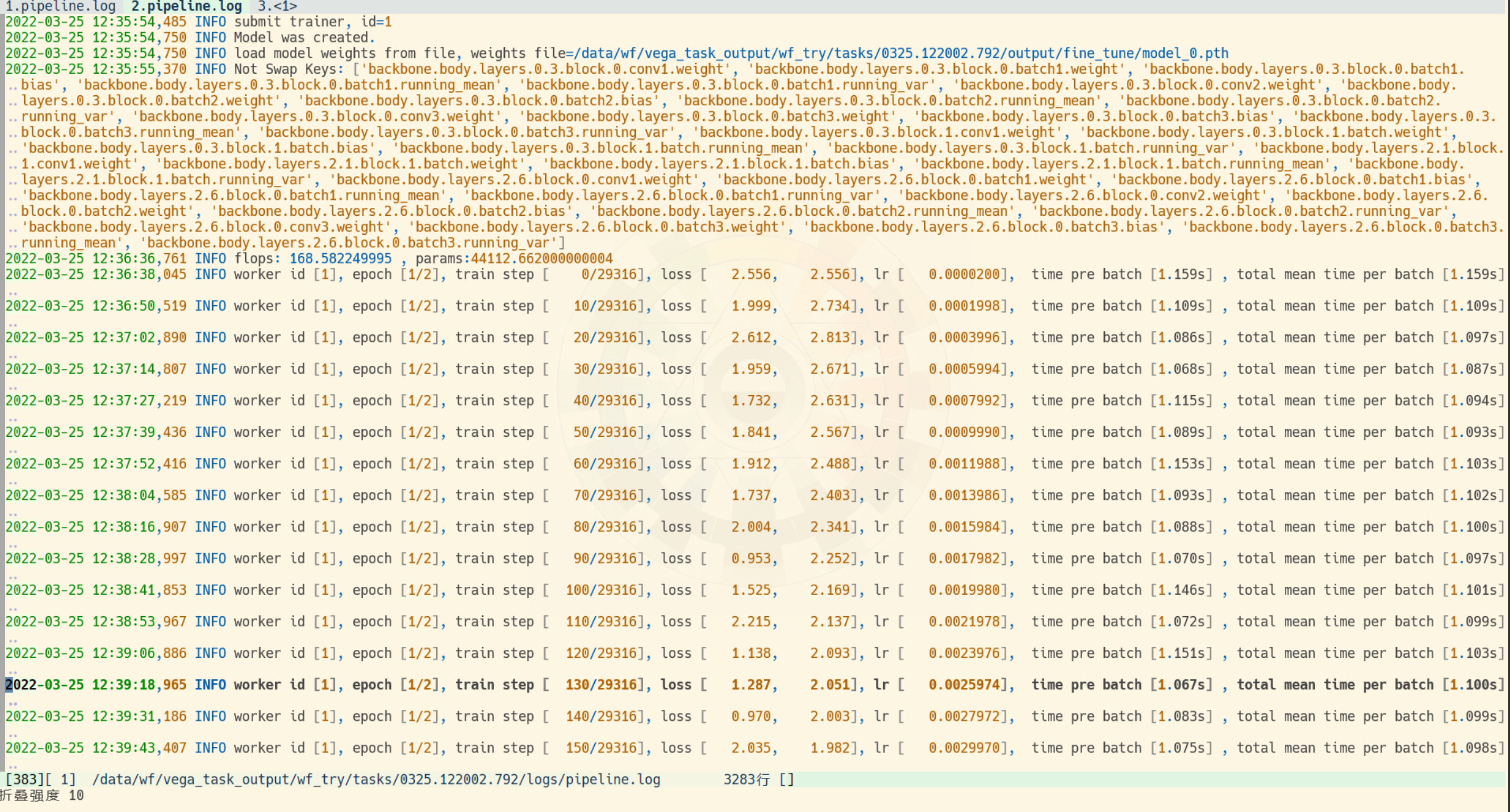 你们是怎么从中找到有用的信息的呢?
你们是怎么从中找到有用的信息的呢?
训练时每次迭代的记录太多了, 没有缩进, 不能在vim或者vscode里按缩进折叠, 太难翻了.
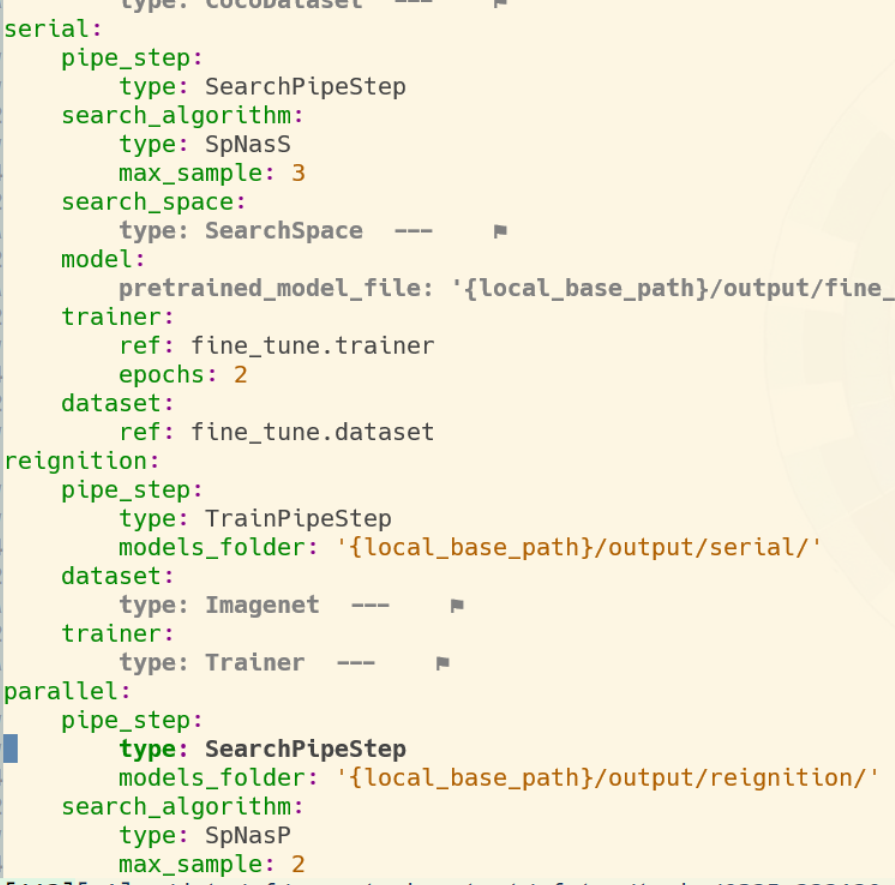
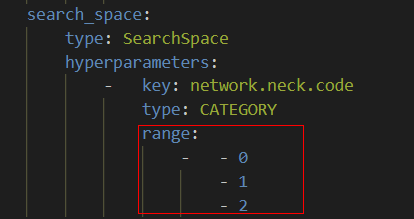
@sisrfeng 你的配置文件要修改一下,parallel阶段的searchspace定义应该为[0,1,2,3],这是一个长度为4的数组,对应的是fasterRcnn的4个特征图。搜索算法会打断其顺序和组合,但是总长度不变。