Multi-step predictions with TM
I think for higher prediction and robuster anomaly detection, we need something like a chain of 10 TMs for 10 steps prediction: TM0->TM1->TM2->...-->TM9, where the predicted cells of the previous TM (e.g. TM1) will be inputed into the next TM (e.g. TM2) and so on. It can be realized by using an array of TM with fixed size, I say variant 1, But it can be also by using only 2 TMs: TM0 and TMworker, where at every time instance, TMworker is cloned from TM0 and run multiple time (here 9 times) (I say variant 2)
As the 3rd variant, I think we can use SDRClassifier for all steps from 1 to 10. At each time instance, we have 10 concurrent suggestions of the predicted buckets (one at the current time and 9 from the last). The best bucket is a bucket with most score within 10 suggestions.
My questions:
- Which variant do you think better?
- Is the clone-algorithm time-consuming? How can we do it efficiently in C++?
Best thanks
So the task is to do multi-step predictions? (predict Nth step, instead of the current next).
TMs for 10 steps prediction: TM0->TM1->TM2->...-->TM9, where the predicted cells of the previous
this is the hierarchical in HTM, and I think it's the correct approach. Note you should also use SP at each (middle) layer, because the output of a TM is not a valid SDR.
But it can be also by using only 2 TMs: TM0 and TMworker, where at every time instance, TMworker
if I understand this approach, TMworker would be like a short-term memory, but for planning. I don't know if that's biological, but it could work quite nice (short term mem works that way).
Is the clone-algorithm time-consuming?
what do you mean by a "clone algorithm"? It could be realised with serialization, that would slow-down the TM, but depends what speeds do you need to achieve?
Also, you could only temporarily disable learning in TM, run the N steps and get the 10th prediction.
PS: I'm glad to discuss it here, but you might get more views on HTM forums on discourse.
@breznak thanks for your comments: In all experiments of Mine, i do not use SP for data prediction due to very bad prediction performance. I like to hear other experience from community!
If we turn off learning and run TM 10 Times for 10 steps prediction. After that turn learning on. I am not sure that TM has the same states as before turn-off learning? Do you have any experiment on it?
For that reason, I clone the current TM into TMworker, and run TMworker 10times in prediction mode! Is my thinking more complicate than your simple proposal of yours?
I have some tests on each solution and want to share with you:
- Using TMworker and clone TM in every step is to slowly and bad performance
- Array of TM is the best
- Current version of SDRClassifier uses soft max and select one bucket with highest likelihood. Even for one-step prediction with sinus waves it does not provide a good result for all my tests (different frequencies and amplitudes)
If we turn off learning and run TM 10 Times for 10 steps prediction. After that turn learning on. I am not sure that TM has the same states as before turn-off learning?
this is a good point! I am not sure, TM will not learn (that we want) but the context will be likely different.
Array of TM is the best
so TM->TM->TM->Classifier for 3-step prediction? Could you share some results how much better it is to the current Predictor?
This is also the most biological approach, using hierarchy. I'd expect it to perform the best.
I'll do similar experiments in #683
@breznak current SDRclassifier is also good ONLY for 1-step prediction, but not so robust. I even test it for bucket 1-step-prediction, but does not provide good results.
For that reason, I use my old encoder with bucket outputs for analysing.
Using TM-chain TM->TM->TM....you can do better high-order prediction (see below for 4-step prediction)
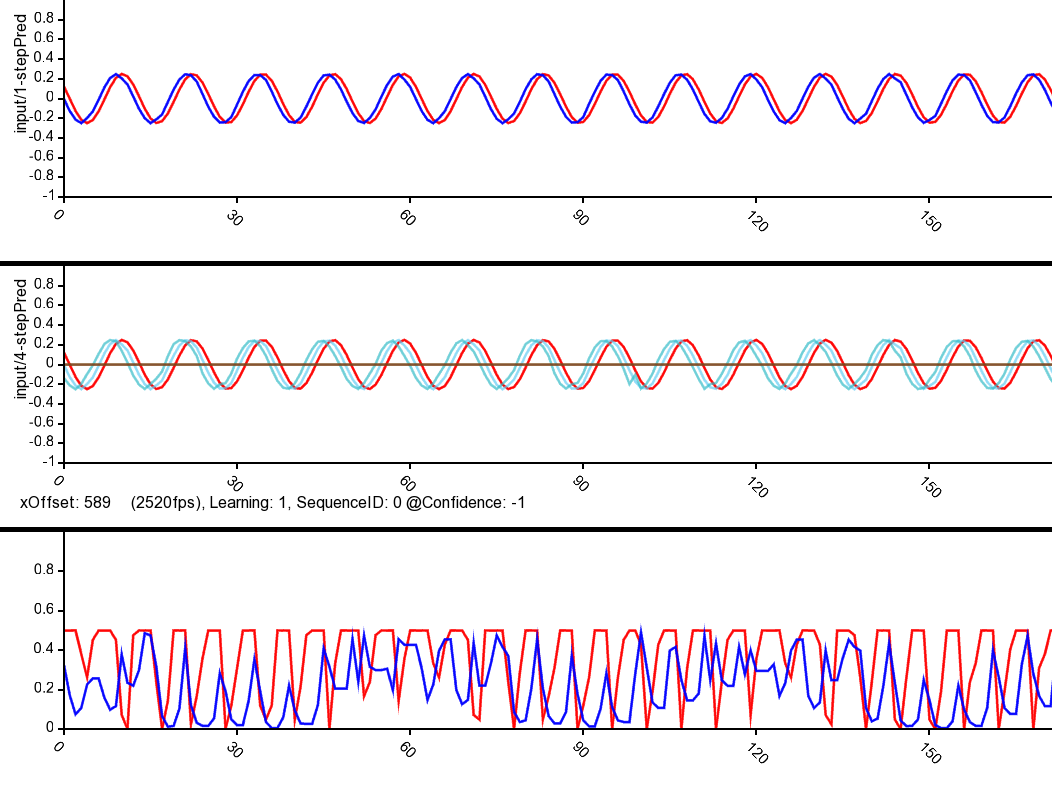
Thanks Binh! What is the 3rd plot?
For that reason, I use my old encoder with bucket outputs for analysing.
you are using that instead of the Classifier? Or how?
- one more thing to try would be a feedback loop:
TM(input(t), TM(t-1))
@breznak the 3rd plot is experimental result of current anomaly score, calculated by all TMs: that means overlapping score of SDR, provided by each TM 4-step, Tm3-step,tm2-step and tm1-step at each time instance t
No I do not use sdrclassifier. But results look like the same if for each TM you use SDRClassifier with 1-step prediction