[RFC] Unified Tensor Structure
Background
Colossalai integrates a variety of parallel modes, and the tensor data structure of each parallel mode is different. Specifically.
ZeRO:Wrap the data and grad of torch.nn.Parameter as a StatefulTensor. And data is ShardedTensor. (2022.3.31)
Tensor Parallel (TP) and Pipeline Parallel (PP): Still use torch tensor. But we specified the tensor shape, which is inferred by developers.
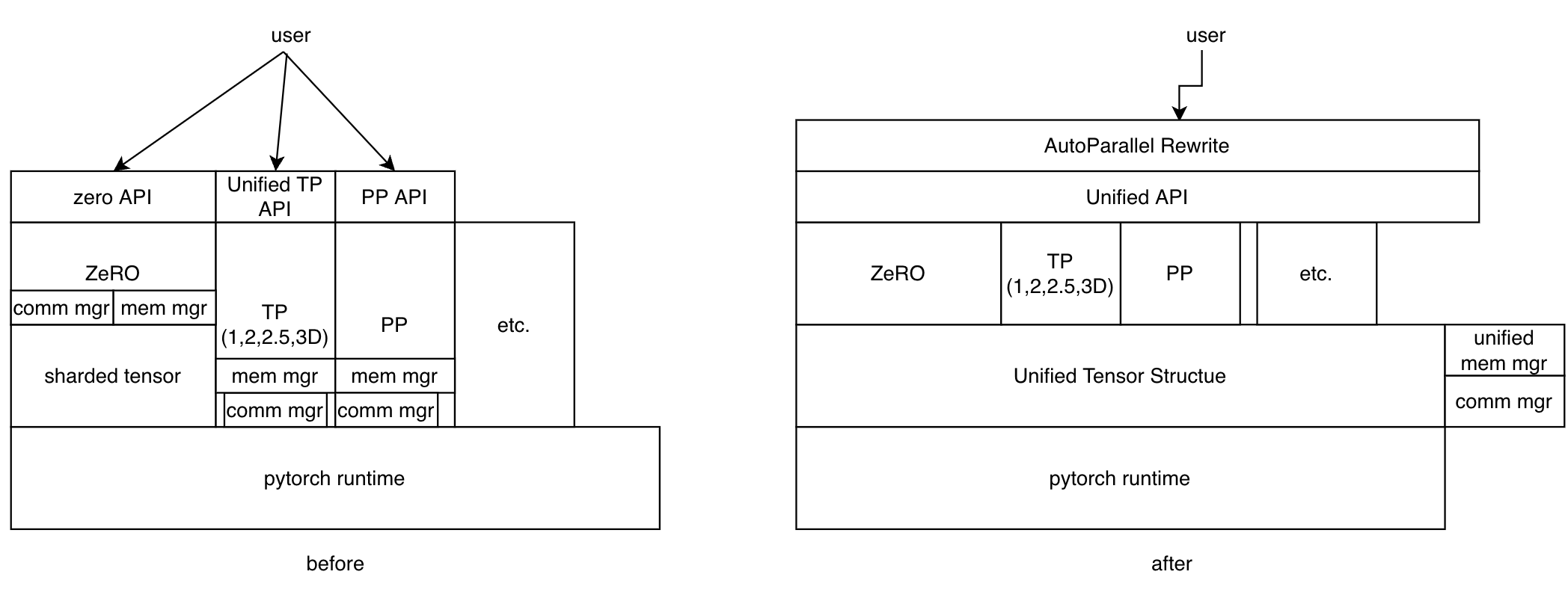
This RFC discusses designing a unified tensor data structure for colossalai, so that different parallel mode can be developed with the same data structure. By applying a unified adaptation to PyTorch nn.Tensor, we can better improve storage efficiency optimization and implement automatic parallelism. The change is illustrated in the following picture.
Terminology
- Heterogeneous memory (HM): storage space composed of multiple CPUs and multiple GPUs
- DDP: We use PyTorch DDP to implement multi-process parallelism, and each process manages an individual GPU and 1/N CPU resources. Resources include storage and computing resources.
Stateful Tensor
The period that a Tensor is used for computing is short compared with its lifetime. As shown in the figure below, only the model data and activation needed by the operators are used during computing. Most of the time, they are idle. In the traditional deep learning framework, the storage space of Tensor does not change during computing and non-computing.
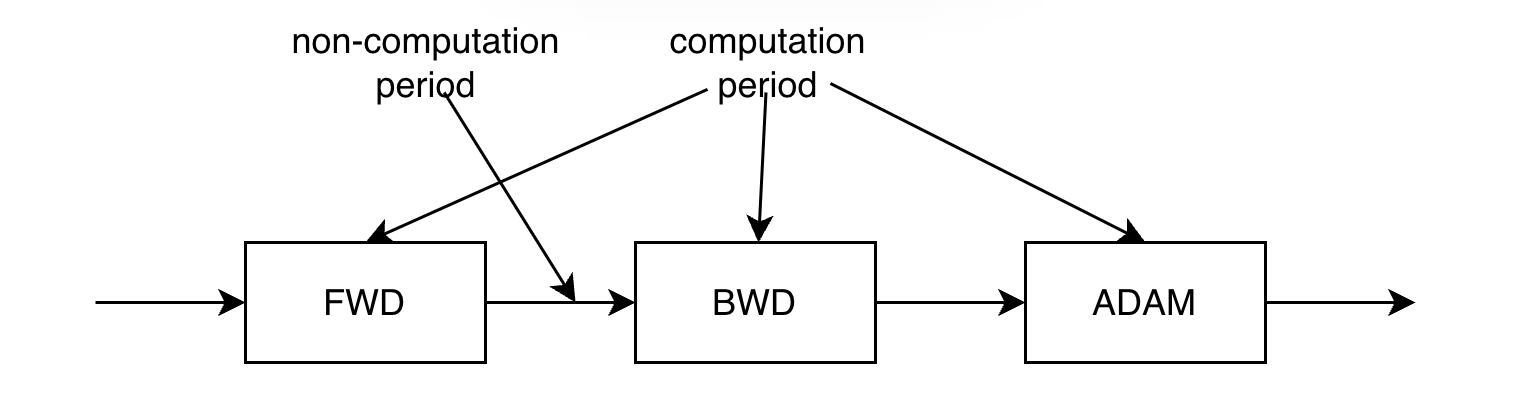
The tensor storage space can be changed during non-computation time. As long as it is restored before computing, the training process of deep learning will not be affected. A simple optimization is to reduce CUDA memory requirements when not computing. The core calculation of deep learning is matrix multiplication. The characteristics of matrix multiplication determine that in distributed computing, the data of the matrix must be redundant among processes. This results in data redundancy in different computing nodes during computation. During the non-computation period, we can remove this redundancy and restore it the next time before computation.
Example 1: ZeRO bcast param before calculation, and release it after calculation. Example 2: 1D Tensor Parallel, although splitting of the model data eliminates redundancy, it requires each process to have a global activation tensor during calculation, which brings redundancy. But we can also shard activations to eliminate redundancy during non-computation.
Since we need to distinguish between the computation period and the non-computation period of Tensor, I proposed to use the stateful tensor, inspired by PatrickStar, as the unified tensor data structure. The state is presented in two aspects:
- Spatial Property:(Inter-process state + intra-process state) 1.1 Intra-process a) CPU/GPU/NVMe 1.2 inter-process a) Shard b) Duplicated c) Partial
- Temporal Property: a) COMPUTE b) HOLD c) HOLD_AFTER_FWD d) HOLD_AFTER_BWD
When a Tensor has a state, we can decide its memory layout in HW based on its state.
Spatial property
Inter-process
Tensor data is stored in the following ways in multiple processes
- Shard (S in short):a.k.a split, Each process stores a shard of a tensor.
- Duplicated (D):a.k.a Broadcast, Each process stores the same tensor replica
- Partial (P): Each process stores a tensor of the same shape as the global tensor, however, the values of the global tensor are derived by a global reduction operation on the partial tensors of all processes.
Intra-process
In the process, the Tensor can exist on the CPU, or on the GPU. In the future, it can also be extended to SSD and disk.
The spatial state of a tensor is the Cartesian product of the inter-process state and the intra-process state.
Tensor state = {inter-proc state} x {intra-proc state} = {B, S, P} x {cpu, cuda}
Temporal property
The same as PatrickStar.
Parallel Mode
For each Linear operator, we have 1D, 2D, 2.5D, 3D, seq parallel, and other parallel modes. The state of the tensor in each parallel strategy can be represented by a stateful tensor. Here are a few examples.
y = xA+b, X input activations (m, k); A weight (k, n),y output activations. X's state x A's state -> y's S(X) is split on X dim.
- Colossal 1D_col B x S(1)-> S(1)
- Colossal 1D_row S(1) x S(0) -> P
- Colossal 2D
for i in 0-P-1
for j in 0-P-1
fetch remote A_ij
Sij(0,1) x S_ij(0,1) -> accumlate on S_ij(0,1)
-
ZeRO,using tensor shard S(0) x S(0) -> S(0) gather A,split y
-
ZeRO offload S(0) x {S(0), cpu} -> S(0)
Relation of parallel strategy and tensor state
I think that the spatial property of the tensor state can be deduced by defining the parallel strategy of each operator. Conversely, the former can also be deduced by the latter.
We can let users use the Stateful Tensor in the following way:
- We can specify the configuration of the inter-proc property of each operator in the model, and the intra-proc property can be guided by the memory tracer at runtime (see PatrickStar). After the inter-proc property + intra-proc property is determined, we can derive the parallel strategy.
- We assign a parallel strategy to operators, and derive the tensor inter-proc prop. The intra-proc property also is guided by the memory tracer at runtime (see PatrickStar).
An idea to implement stateful tensor in terms of tensor parallelism:
For a tensor partitioned across a group, we can bind the dim to partition, as well as the corresponding parallel mode to communicate in, to the tensor.
E.g., we have a 2d parallel matrix x of shape [M,N]. Its first dim is partitioned across parallel_2d_col, while the second dim is partitioned across parallel_2d_row. Then x.parallel_modes = [(parallel_2d_col), (parallel_2d_row)] (each tuple is because some dim can be partitioned across multiple modes). If x.parallel_modes = [None, None], it is duplicated across tensor parallel group.
There may be 3 benefits:
- It can be more convenient to do reduce operations. E.g., for mean, norm, gather, etc., we no longer need to specify modes, so as to alleviate users' pre-knowledge requirement of parallelism.
- Improve the initialization of tp layers.
- Also helpful to know how to partition optimizer states