ColossalAI

ColossalAI copied to clipboard
[BUG]: Op hook leads to memory leak
Describe the problem
In version 0.1.7, I found that Op hook leads to memory leak. If you use the hook on nn.module, even though it's a dummy hook, more CUDA memory will be used. The max memory allocated for the first step and that of the second step have a huge gap. In my experiment, it's about 10GB.
What we can do now is to avoid applying hooks on nn.Module. We have successfully resolved this issue in the next release
To Reproduce
import colossalai
import psutil
import torch
import torch.nn as nn
from torch.optim import Adam
from colossalai.logging import disable_existing_loggers, get_dist_logger
from transformers import GPT2Config, GPT2LMHeadModel
from colossalai.engine.ophooks import BaseOpHook, register_ophooks_recursively
class DummyHook(BaseOpHook):
def __init__(self):
super().__init__()
def pre_fwd_exec(self, module: torch.nn.Module, *args):
pass
def post_fwd_exec(self, module: torch.nn.Module, *args):
pass
def pre_bwd_exec(self, module: torch.nn.Module, input, output):
pass
def post_bwd_exec(self, module: torch.nn.Module, input):
pass
def post_iter(self):
pass
class GPTLMModel(nn.Module):
def __init__(self, hidden_size=768, num_layers=12, num_attention_heads=12, max_seq_len=1024, vocab_size=50257, checkpoint=False):
super().__init__()
self.checkpoint = checkpoint
self.model = GPT2LMHeadModel(GPT2Config(n_embd=hidden_size, n_layer=num_layers,
n_head=num_attention_heads, n_positions=max_seq_len, n_ctx=max_seq_len, vocab_size=vocab_size))
if checkpoint:
self.model.gradient_checkpointing_enable()
def forward(self, input_ids, attention_mask):
# Only return lm_logits
return self.model(input_ids=input_ids, attention_mask=attention_mask, use_cache=not self.checkpoint)[0]
class GPTLMLoss(nn.Module):
def __init__(self):
super().__init__()
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, logits, labels):
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
return self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
def get_data(batch_size, seq_len, vocab_size):
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len), device=torch.cuda.current_device())
attention_mask = torch.ones_like(input_ids)
return input_ids, attention_mask
def gpt2_medium(checkpoint=False):
return GPTLMModel(hidden_size=1024, num_layers=24, num_attention_heads=16, checkpoint=checkpoint)
def get_cpu_mem():
return psutil.Process().memory_info().rss / 1024**2
def get_gpu_mem():
return torch.cuda.max_memory_allocated() / 1024**2
def get_mem_info(prefix=''):
return f'{prefix}GPU memory usage: {get_gpu_mem():.2f} MB, CPU memory usage: {get_cpu_mem():.2f} MB'
def main():
BATCH_SIZE = 4
SEQ_LEN = 1024
VOCAB_SIZE = 50257
NUM_STEPS = 3
disable_existing_loggers()
colossalai.launch_from_torch(config={})
logger = get_dist_logger()
logger.info(get_mem_info(), ranks=[0])
# build GPT model
model = gpt2_medium(checkpoint=False).cuda()
register_ophooks_recursively(model, [DummyHook()])
logger.info(get_mem_info(prefix='After init model, '), ranks=[0])
# build criterion
criterion = GPTLMLoss()
# optimizer
optimizer = Adam(model.parameters(), lr=1e-3)
logger.info(get_mem_info(prefix='After init optim, '), ranks=[0])
model.train()
for n in range(NUM_STEPS):
input_ids, attn_mask = get_data(BATCH_SIZE, SEQ_LEN, VOCAB_SIZE)
optimizer.zero_grad()
outputs = model(input_ids, attn_mask)
loss = criterion(outputs, input_ids)
logger.info(get_mem_info(prefix=f'[{n+1}/{NUM_STEPS}] Forward '), ranks=[0])
loss.backward()
logger.info(get_mem_info(prefix=f'[{n+1}/{NUM_STEPS}] Backward '), ranks=[0])
optimizer.step()
logger.info(get_mem_info(prefix=f'[{n+1}/{NUM_STEPS}] Optimizer step '), ranks=[0])
if __name__ == '__main__':
main()
Save this code and run:
torchrun --standalone --nproc_per_node=1 this_file.py
Screenshots
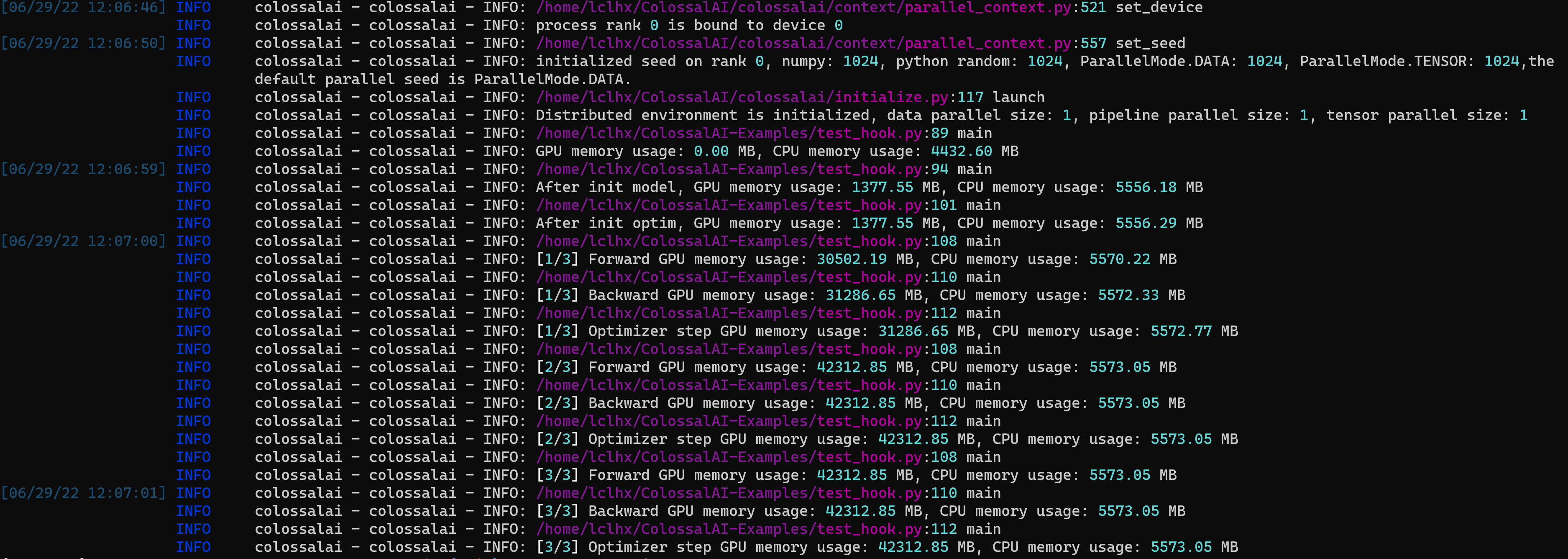
Then I don't use op hook by commenting register_ophooks_recursively(model, [DummyHook()]):
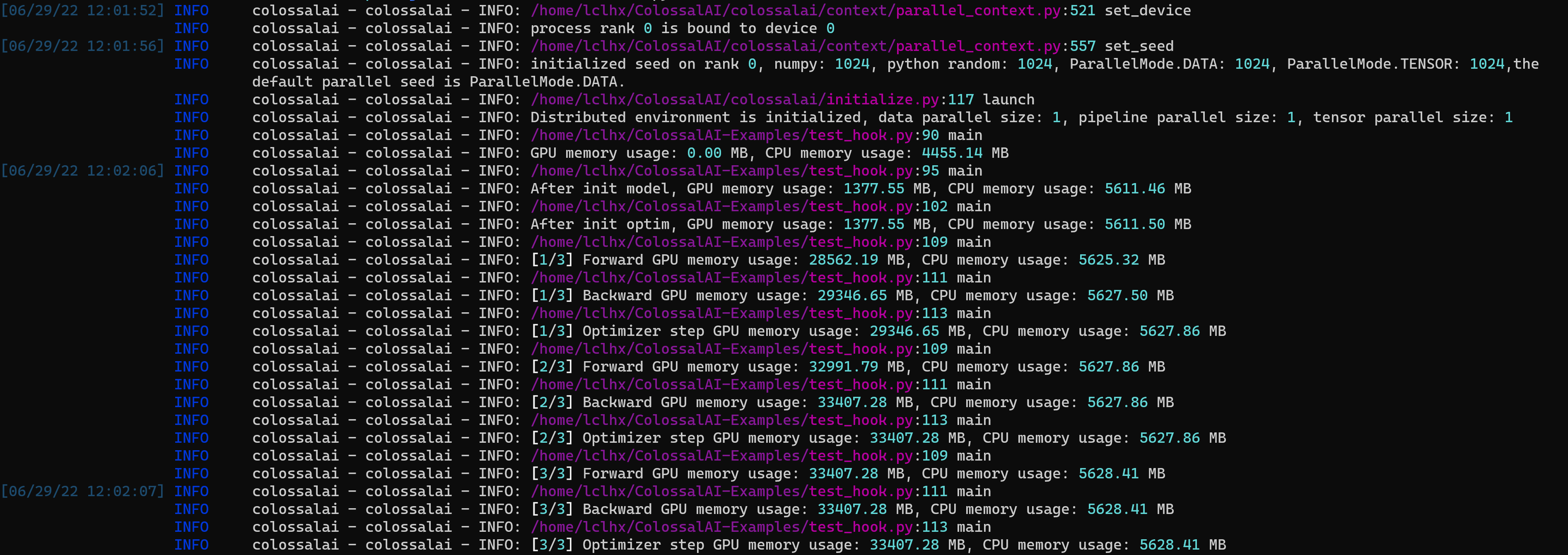
In conclusion, op hook leads to extreme memory leak.
Environment
GPU: 1x A100 CUDA: 11.3 Python: 3.9.7 PyTorch: 1.11.0