papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error Correction
Metadata
Authors: Shamil Chollampatt and Hwee Tou Ng1 Organization: National University of Singapore Release Date: 2018 on Arxiv Link: https://arxiv.org/pdf/1801.08831.pdf
Summary
This paper is the first group to successfully employ a fully convolutional Seq2Seq (Conv Seq2Seq) model (Gehring et al., 2017) on grammatical error correction (GEC) with some improvements: BPE tokenization, pre-training fastText on large native English corpora, pre-training auxiliary N-gram language model as re-scorer and incorporating task-specific features. The experiment results outperform strong statistical machine translation baseline and all previous neural-based approaches on this case in terms of CoNLL-2014 (grammaticality) and JFLEG dataset (fluency). Additionally, the attention visualization of LSTM-based and Conv-based model shows that LSTM-based model tends to focus on matching source words as opposed to Conv-based model which tends to focus on surrounding context words.
Highlights of Technical Detail
- Pre-training of word embeddings: Initialize the word embeddings for the source and target words with pre-trained fastText embeddings.
- Subword-level: BPE tokenization is performed on both parallel corpus (for training networks) and monolingual corpus (for training embeddings).
- Training: The networks is trained with Nesterov’s Accelerated Gradient Descent (NAG) with a simplified formulation for Nesterov’s momentum.
- Decoding and Rescoring: Use beam search with log-linear feature scoring function. Feature weights are computed by minimum error rate training (MERT) on the dev set. Features are: Edit operation (EO) (i.e., the number of token-level substitution, deletions and insertions between the source and the hypothesis sentence) and 5-gram language model score (i.e., the sum of log-probabilities of hypothesis sentence, the number of words in hypothesis sentence)
Experiment Settings
- Parallel training data: Lang-8 and NUCLE (5.4K is taken out to train re-scorer), resulting in 1.3M sentence pairs for training networks.
- Monolingual data for pre-training fastText word embeddings: Wikipedia (1.78B words)
- Monolingual data for pre-training 5-gram language model: Common Crawl corpus (94B words)
- Testing data:
- CoNLL-2014 test set with F_{0.5} score computed using the MaxMatch scorer.
- JFLEG with GLEU score.
- Model is from publicly available PyTorch-based implementation - FairSeq:
- Both source and target embeddings are 500 dimensions.
- Each of source and target vocabularies consists of 30K most frequent BPE tokens from parallel data.
- FastText embeddings is trained using skip-gram model and window size of 5.
- Character N-gram sequences of size between 3-6 (both inclusive).
- The embeddings are not fixed during training the networks.
- Both encoder and decoder are made up with 7 convolution layers with window width 3.
- Output if each encoder and decoder layer is 1024 dimensions.
- Dropout: 0.2.
- Trained on 3 NVIDIA Titan X GPUs with a batch size of 32 on each GPU and perform validation after every epoch concurrently on another NVIDIA Titan X GPU.
- Learning rate: 0.25 with a annealing factor of 0.1 and a momentum value of 0.99.
- Training a single model takes ~18 hours.
- Beam size for decoding: 12.
Experiment Results
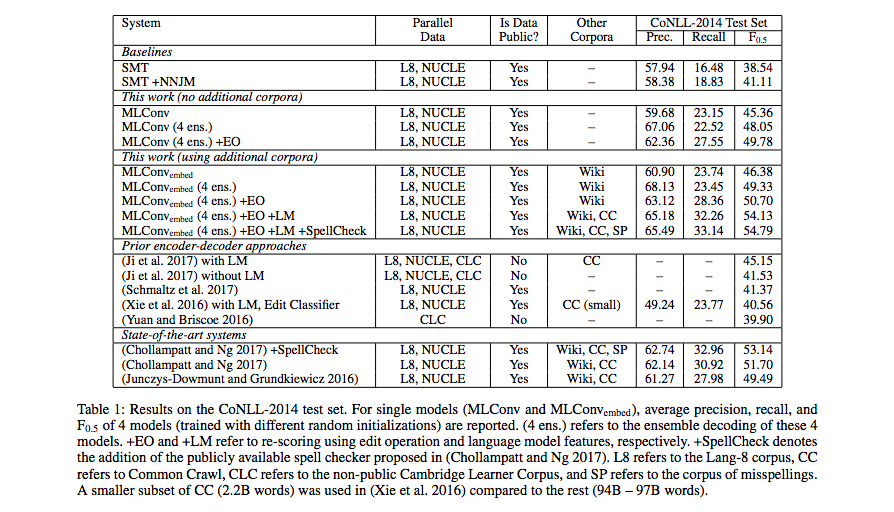
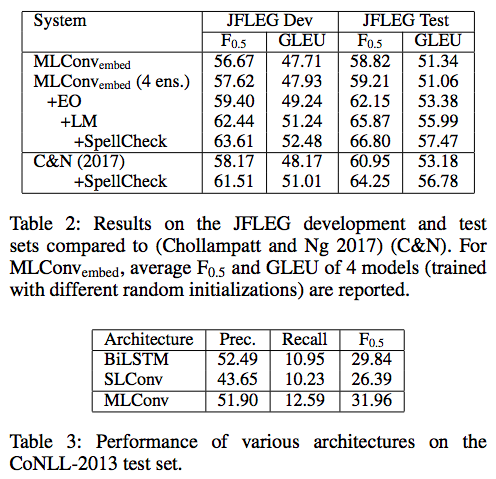
Notes on Table 3:
- Models evaluated without using pre-trained word embeddings.
- SLConv: Single-layer convolutional Seq2Seq model
- MLConv: Multi-layer convolutional Seq2Seq model
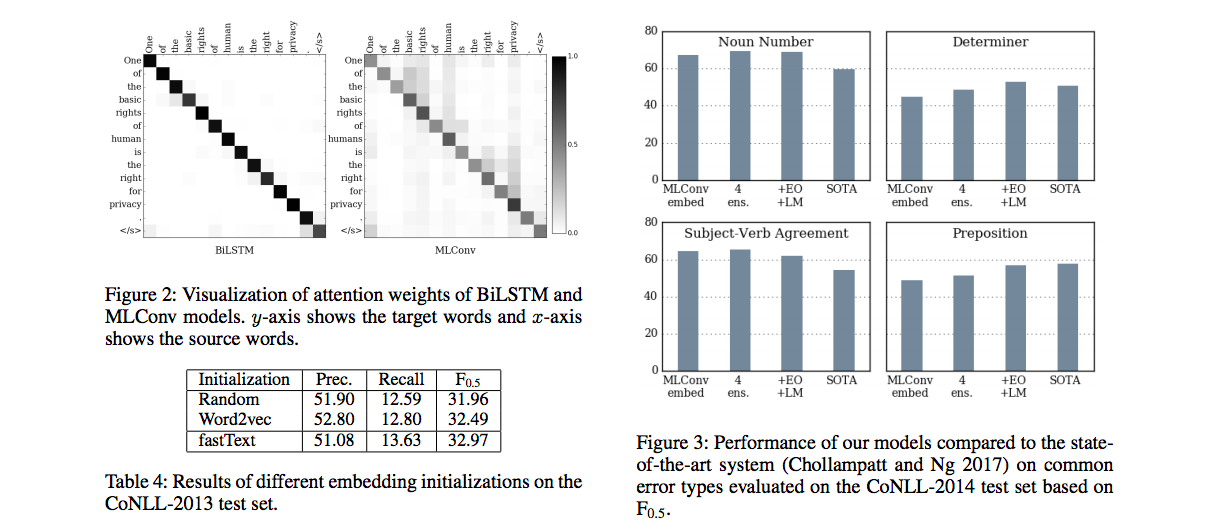
Notes on attention visualization:
- The attention weights shown for the MLConv model is the averaged attention weights of all decoder layers.
Insights
- Table 3 shows that Bi-LSTM has a higher precision than the MLConv, but a lower recall.
- Interestingly, the attention visualization may have some correlation to the precision & recall.
- It demonstrates the ability of MLConv in capturing the context better, thereby favoring more corrections than copying of the source words.
Future Work
- Integration of LSTM-based and Conv-based models.
- Integration of web-scale LMs during beam-search and the fusion of neural LMs into the network.
References
- Convolutional sequence to sequence learning by Gehring et al. (ICML 2017)