papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels
Metadata
- Author: Sangdoo Yun, Seong Joon Oh, +3, Sanghyuk Chun
- Organization: NAVER AI LAB
- Paper: https://arxiv.org/abs/2101.05022
- Code: https://github.com/naver-ai/relabel_imagenet
Highlights
-
Motivation. ImageNet label is noisy: An image may contain multiple objects but is annotated with image-level single class label.
-
Intuition. A model trained with the single-label cross-entropy loss tends to predict multi-label outputs when training label is noisy.
-
Relabel. They propose to use a strong image classifier that trained on extra data (super-ImageNet scale, JFT-300M, InstagramNet-1B) + fine-tuned on ImageNet, to generate multi-labels for ImageNet images. Obtain pixel-wise multi-label predictions before the final global pooling layer (offline preprocessing once).
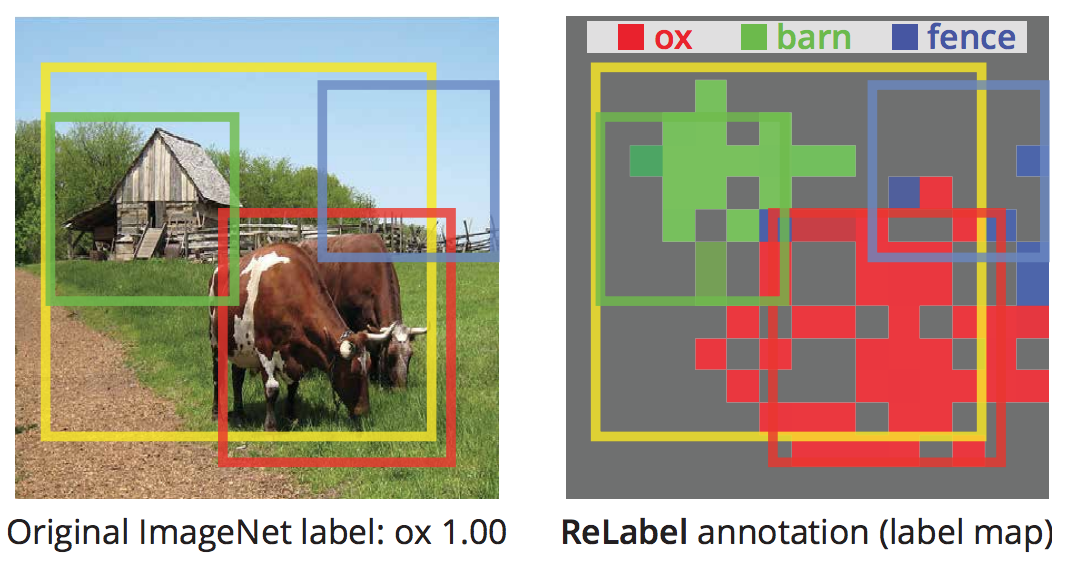
-
Novel training scheme -- LabelPooling. Given a random crop during training, pool multi-labels and their corresponding probability scores from the crop region of the relabeled image.

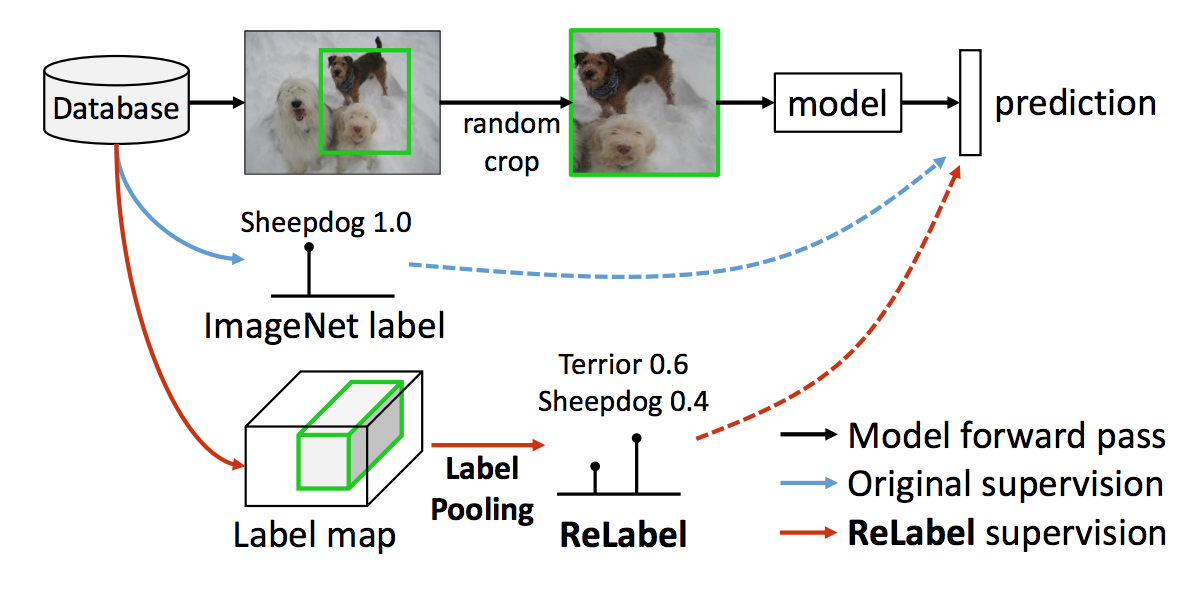
-
Results. Trained on relabeled images with multi-and-localized labels can obtains 78.9% accuracy with ResNet-50 (+1.4% improvement over baseline trained with original labels), and can be boosted to 80.2% with CutMix, new SoTA on ImageNet of ResNet-50.
Related work: Better evaluation protocol for ImageNet
- ImageNetV2: Do ImageNet Classifiers Generalize to ImageNet?
- Are we done with imagenet?
- Evaluating machine accuracy on imagenet. ICML 2020.
- (Not on ImageNet but related) Evaluating Weakly Supervised Object Localization Methods Right. CVPR 2020
The above works have identified 3 categories for the erroneous single labels
- An image contains multiple objects
- Exists multiple labels that are synonymous or hierarchically including the other
- Inherent ambiguity in an image makes multiple labels plausible.
Difference from this work
- This work also refines training set while previous work only refine validation set.
- This work correct labels while previous work remove erroneous labels.
Related work: Distillation (I hand-picked some by their practical usefulness in my opinion)
- [Ensemble distillation] Knowledge distillation by on-the-fly native ensemble. NIPS 2018.
- [Self-distillation] Snapshot distillation: Teacher-student optimization in one generation. CVPR 2019.
- [Self-distillation] Self-training with noisy student improves imagenet classification. CVPR 2020.
Difference from this work
- Previous work did not consider a strong, SoTA network as a teacher.
- Distillation approach requires forwarding teacher on-the-fly, leading to heavy computation.
Relabeling Details
Network architecture modification for generating label map
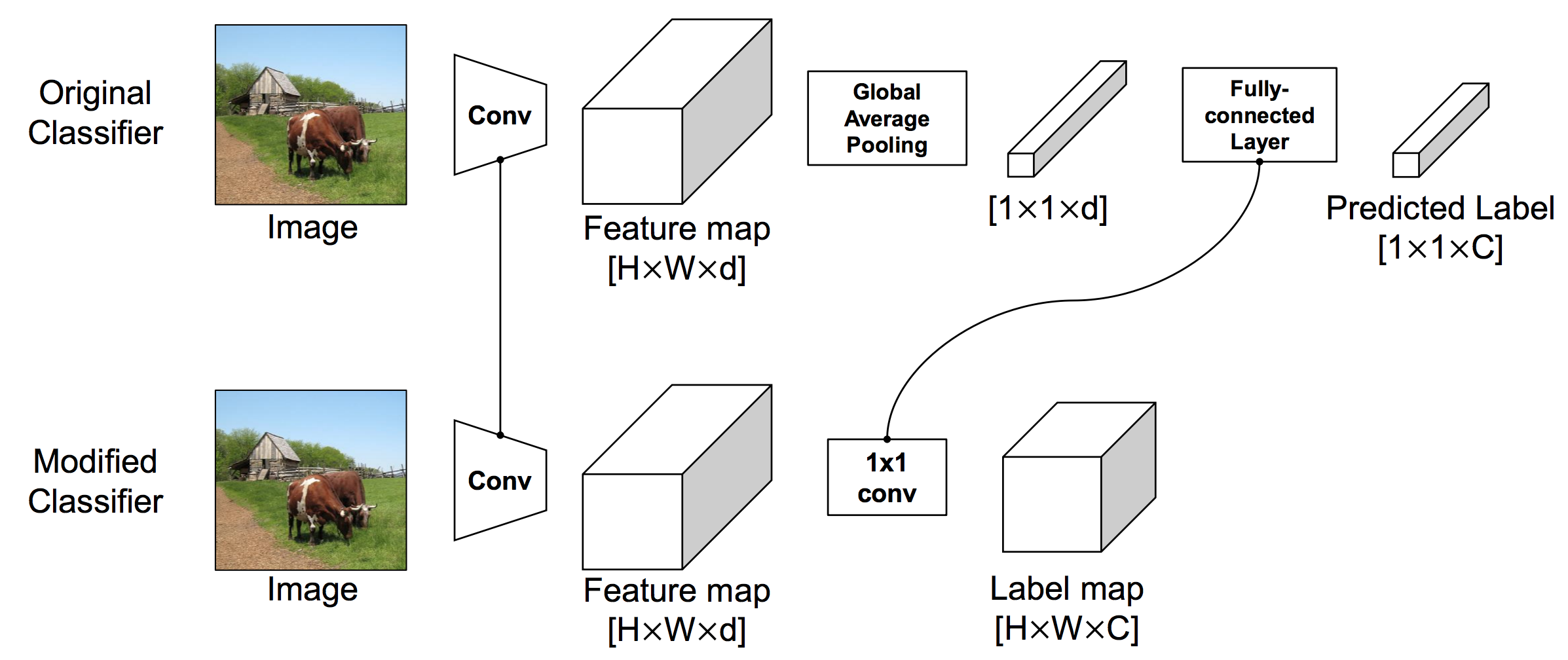
- Original: Feature map [H, W, d] => Global Pooling [1, 1, d] => Predicted label [1, 1, C] with FC.
- Modified: Feature map [H, W, d] => Predicted label map [H, W, C] with 1x1 Conv.
- FC and 1x1 Conv is identical.
- Use EfficientNet-L2, input size 475x475, training image is resized to 475x475 without cropping.
- Label map's spatial size [H, W] = [15, 15], d=5504, C=Top-5 predictions among 1000 (storing 15x15x1000 is expensive)
Generating label map using different architectures
They tried diverse architectures:
- SoTA EfficientNet-{B1,B3,B5,B7,B8}
- EfficientNet-L2 trained with JFT-300M
- ResNeXT-101_32x{32d, 48d} trained with InstagramNet-1B And train ResNet-50 with the above label maps from diverse classifiers. Finally label map generated from EfficientNet-L2 is chosen due to its best quality for obtaining the final best accuracy. (Can we ensemble these label maps?)
Important Findings
- When the teacher is not sufficiently strong, the performance will not be better than baseline.
- Local multi-label > global multi-label > local single-label > global single label (original one).
- Combining with original label decreases performance, but yet better than only original label.
- Evaluating on new multi-label ImageNet benchmark, the performance gain is larger.
- Knowledge distillation can still get comparable or better performance but training time is longer.
- Label smoothing on original label obtains surprisingly strong performance, since label smoothing can be as a kind of knowledge distillation.
- Why label map is 15x15? Besides saving storage, I think there's a paper An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale related to this design choice.
Training with LabelPooling
Once label map is pre-computed, we can train a new network by the following procedure:
- Load image & label map (15x15xC)
- Augmented image = Random crop image (with a bounding box [x, y, w, h]) and resize to (224x224)
- New target = ROIAlign(label map, bounding box) [h, w, C] + global pooling [1, 1, C] + softmax
- Train model with <Augmented image, New target> with cross-entropy loss
Discussion on Design Choices
- Isn't 15x15 label map too small? Due to expensive storage consumption for ImageNet.
- Why not use knowledge distillation? Due to expensive training time for ImageNet.
- Can new network also be trained with local labels instead of global ones (same as FCN in relabeling)?