papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
Cold Fusion: Training Seq2Seq Models Together with Language Models
Metadata
- Authors: Anuroop Sriram, Heewoo Jun, Sanjeev Satheesh and Adam Coates
- Organization: Baidu Research, Sunnyvale, CA, USA.
- Release Date: 2017 on Arxiv
- Link: https://arxiv.org/pdf/1708.06426.pdf
Summary
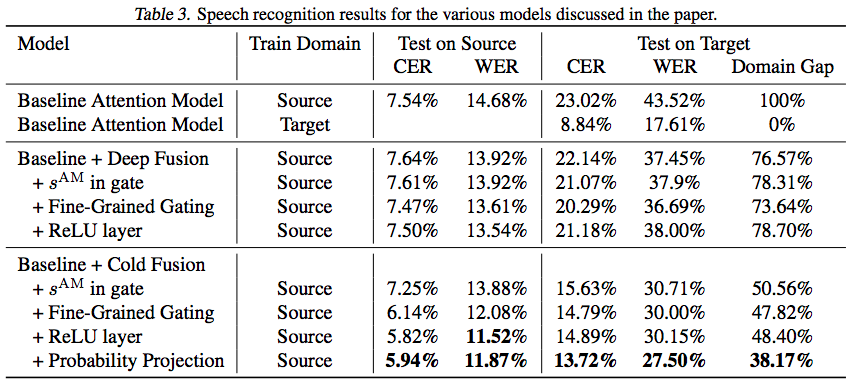
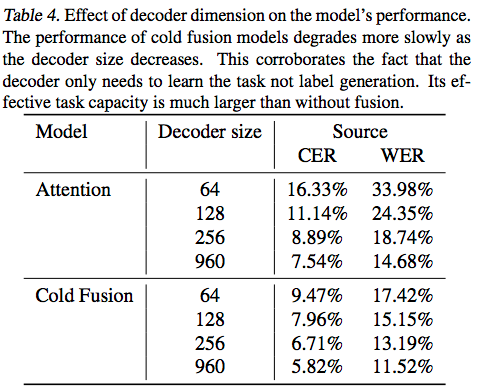
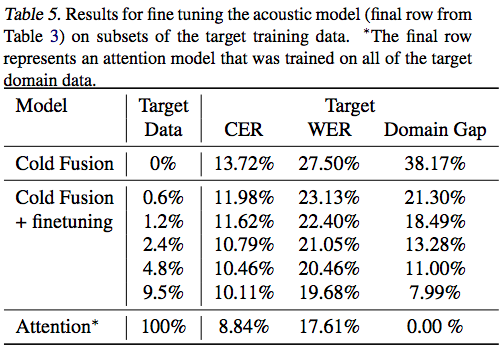
This paper purposes an approach "Cold Fusion" for leveraging a pre-trained language model during training a neural sequence-to-sequence (Seq2Seq) model. In Cold Fusion, the Seq2Seq model is trained from scratch together with a fixed pre-trained language model by using a fine-grained gating mechanism to fuse the hidden state of Seq2Seq's hidden state and the logit output of language model. They show that by leveraging the RNN language model, Cold Fusion reduces word error rates by up to 18% compared to Deep Fusion in speech recognition. They also show that Cold Fusion models can transfer more easily to new domains, and with only 10% of labeled data nearly fully transfer to the new domain.
This paper's direction is similar to #5 but #5 's language model is trained from scratch.
Related Work
Language Model Integration
- Shallow Fusion: A pre-trained language model serves as an auxiliary component to guide beam search process. (Chorowski & Jaitly, 2017; Wu et al., 2016) describe several heuristics that can be used to improve this basic algorithm.
-
Deep Fusion purposed by Gulcehre et al., 2015: Learns to fuse the hidden states of the Seq2Seq decoder and a neural language model with a gating mechanism, after the two models are trained independently. Few limitations are mentioned in this paper:
- Because the decoder in Seq2Seq already learns an implicit language model from the main translation task, taking up a significant portion of the decoder capacity to learn redundant information.
- The auxiliary language model is biased towards the main translation task. For example, if a Seq2Seq model fully trained on legal documents is later fused with a medical language model, the decoder still has an inherent tendency to follow the linguistic structure found in legal text. Thus, in order to adapt to novel domains, Deep Fusion must first learn to discount the implicit knowledge of the language.
Semi-supervised Learning in Seq2Seq
- Back-Translation purposed by Sennrich et al. (2016): Does not apply well to other tasks where back-translation is infeasible or of very low quality (like image captioning or speech recogIntion).
- Unsupervised Pre-training purposed by Ramachandran et al. (2017): Potentially difficult to leverage for the transfer task since training on the parallel corpus could end up effectively erasing the knowledge of the language models
Both back-translation and unsupervised pre-training are simple methods that require no change in the architecture.
Cold Fusion
They use a fine-grained gated mechanism (Yang et al. 2017) to fuse the hidden states of Seq2Seq and the probability (logits, different from Deep Fusion) of language model, learning when to pay attention to Seq2Seq or language model.

- l^{LM}_t: Logit output of the language model. Since logits can have arbitrary offsets, the maximum value is subtracted off before feeding into DNN.
Why not use a normalized probability?
- s_t: Seq2Seq's hidden state
- s_t^{CF}: Final fused state
Note that the fusion in this paper is different from Yang et al. (2017), where Yang et al. uses this way:
h = f(v1, v2) = g ⊙ v1 + (1 − g) ⊙ v2 (Fusing two representations/vectors v1 and v2 )
Experiments
Settings
- Tested on the speech recognition task.
- Metrics: Performance is evaluated with Character error rate (CER) and word error rate (WER)
- In-domain performance: Train and test on the data from the same source domain.
- Out-of-domain performance: Train on the data from source domain and test on the data from target domain.
- Data
- Source domain: Search queries (411000 utterances; 650 hours of audio)
- Target domain: Movie transcripts (345000 utterances; 676 hours of audio)
- Held-out set: 2048 utterances from each domain.
- Language model
- 3-layer GRU with hidden size of 1024.
- Adam optimizer and batch size of 512.
- Acoustic model (Seq2Seq)
- Encoder: 6-layer bi-LSTM with hidden size of 480, residual connections and max pooling layers with a stride of 2 along the time dimension after the first two bi-LSTM layers.
- Decoder: Single layer GRU with hidden size of 960.
- DNN in final fusion layer: Single layer Feed-forward net with hidden size of 256 and ReLU activation function.
- Training the final system (Seq2Seq + language model)
- Adam optimizer and batch size of 64.
- Learning rates are different in Seq2Seq and language model.
- Trained with scheduled sampling with a sample rate of 0.2.
- Inference with beam size of 128.
Results
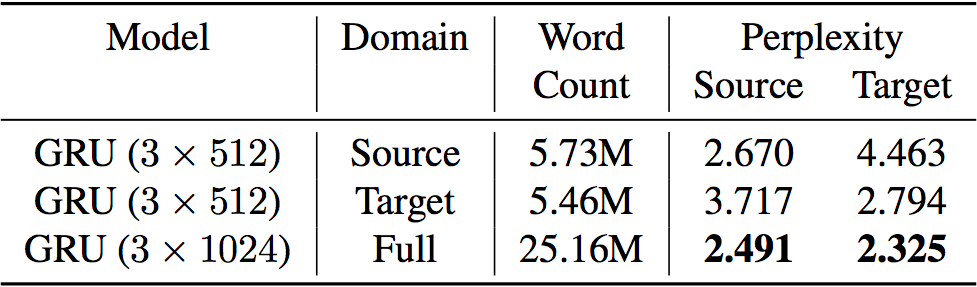
The following table shows the dev set perplexity for char-RNN language models trained on different datasets on source and target domain. This experiment shows that language models are easily overfitted on training distribution, so models trained on one corpus will perform poorly on a different distribution. Thus, they use the model trained on the full dataset (which contains the source and target datasets along with some additional text) for all of the LM integration experiments.
References
- Towards Better Decoding and Language Model Integration in Sequence to Sequence Models by Chorowski & Jaitly. (INTERSPEECH 2017)
- Google’s neural machine translation system: Bridging the gap between human and machine translation by Wu et al. (2016)
- On Using Monolingual Corpora in Neural Machine Translation by Gulcehre et al. (2015)
- Improving Neural Machine Translation Models with Monolingual Data by Sennrich et al. (ACL 2016)
- Unsupervised Pretraining for Sequence to Sequence Learning by Ramachandran et al. (EMNLP 2017)
- Words or Characters? Fine-grained Gating for Reading Comprehension by Yang et al. (ICLR 2017)
Hi Howard, Nice explanation on cold fusion approach. I would like to replicate the same experiment for my seq2seq model. If you have the code in Github repository could you please share with me.
Thanks Naresh
@ellurunaresh Hi, I am not the author of this paper, so I do not have the code. Please implement by yourself (it seems to be easy by just follow the equation...) or search whether there is other implementation available online or not.
@ellurunaresh Hi. Have you managed to implement Cold Fusion or find any resource? I will begin to experiment it with BERT and ULMFIT.
Can you describe what the (tensorflow) operations would be to implement (4c)? I'm not sure what that line's syntax means...? (specifically the [ ] and ◦)