papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
Synthesizing Programs for Images using Reinforced Adversarial Learning
Metadata
Authors: Yaroslav Ganin, Tejas Kulkarni, Igor Babuschkin, S. M. Ali Eslami, Oriol Vinyals Organization: DeepMind Release Date: Arxiv 2018 Paper: https://arxiv.org/pdf/1804.01118.pdf Video: https://youtu.be/iSyvwAwa7vk
Summary
This paper presents SPIRAL, an adversarially trained RL agent that generates a program which is executed by a graphics engine to interpret and sample images in order to mitigate the need for large amounts of supervision and difficulties in scaling inference algorithms to richer dataset.
The agent is rewarded by fooling a discriminator network, and is trained with distributed reinforcement learning without any extra supervision. The discriminator network itself is trained to distinguish between rendered and real images.
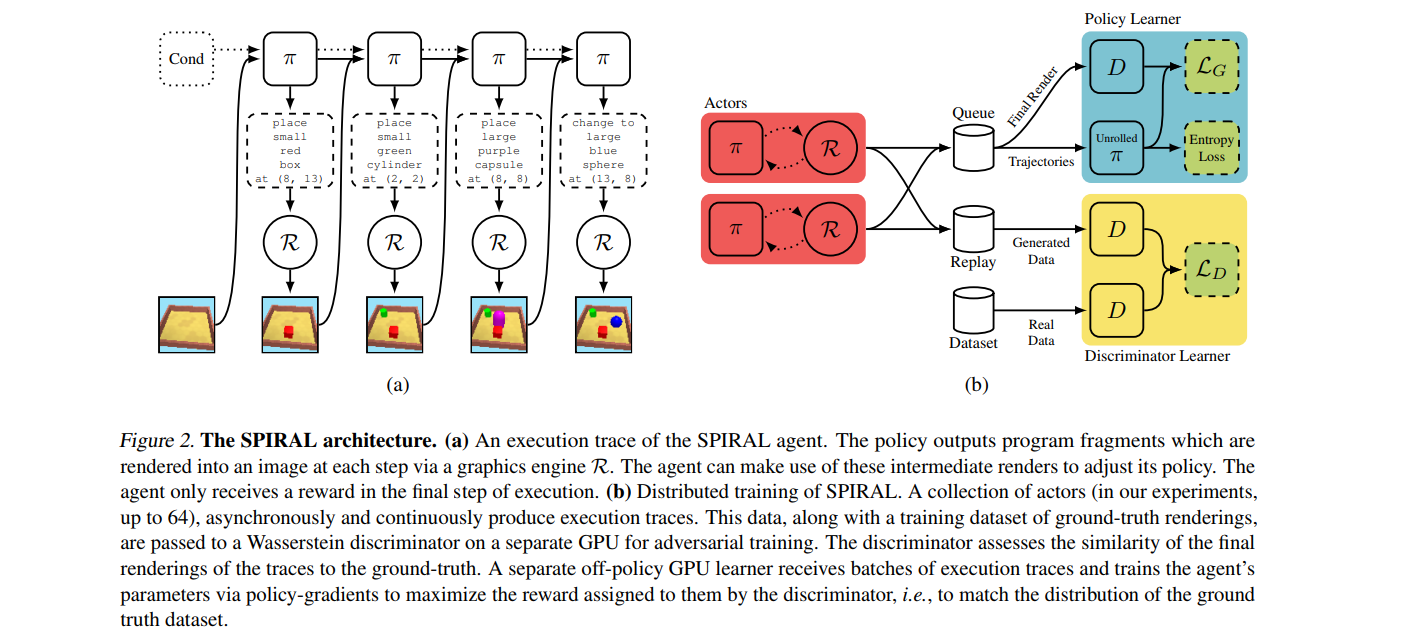
Findings
Utilizing a discriminator's output as the reward signal for RL is significantly better than directly optimizing the pixel error between rendered image and real image.
Details
- They use WGAN objective instead of the vanilla GAN objective for discriminator, where R is a regularization term softly constraining D to stay in the set of Lipschitz continuous functions (for some fixed Lipschitz constant).
- Generator predicts a distribution over all possible commends.
- The generator is trained by A2C (Advantage Actor-Critic), a variant of the REINFORCE algorithm.
- They incorporate replay buffer technique to update model parameters and it works well in practice.
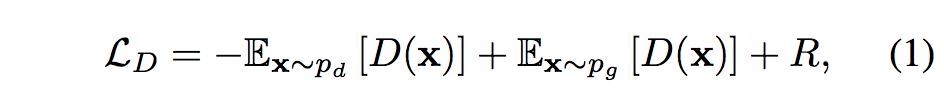

Experiment Settings
- Images are 64x64 from:
- MNIST & OMNIGLOT: Restricted line drawing domain.
- CELEBA: 200,000 color headshots of celebrities with large variation in poses, backgrounds and lighting conditions.
- MUJOCO SCENES: 3D scene contained up to 5 objects.
- Environments of MNIST, OMNIGLOT and CELEBA:
- An open-source painting library libmypaint.
- State: Contents of the current canvas and the brush location (start point).
- Action: A tuple of 8 discrete decisions, control point, end point, pressure, brush size, color-R, color-G, color-B. (20 bins for each color component) and a binary decision that decides whether directly jump to the end point or produce a stroke.
- Reward for unconditional generation: The discriminator score + small negative reward for starting each continuous sequence of strokes (encourage the agent to draw a digit in a single continuous motion of the brush) + negative reward for not producing any visible strokes at all.
- Reward for conditional generation: Fixed L2 distance or the discriminator score.
- Environment of MUJOCO:
- MuJoCo-based environment.
- Action: The object type (4 options), its location on a 16 × 16 grid, its size (3 options) and the color (3 color components with 4 bins each).
- Reward for conditional generation: Same as the above setting.
Network Architecture of GANs
- Discriminator is a DCGAN
- Generator (policy network) is shown as bellow:
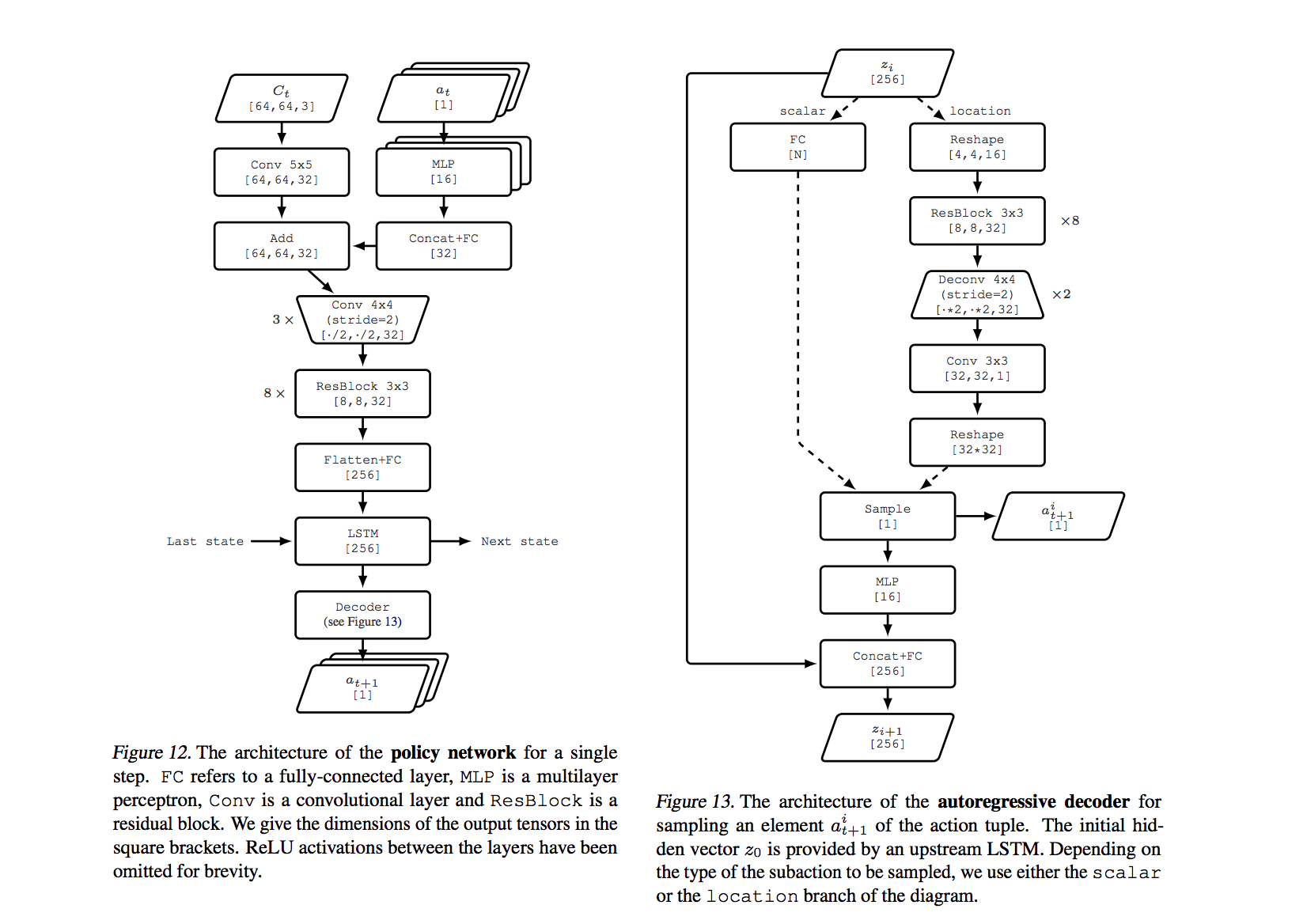
Training Details
- Adam optimizer with a learning rate of 10−4 and β1 set to 0.5 for the discriminator.
- Population-based exploration of hyperparameters (PBT) (Jaderberg et al., 2017) to find values for the entropy loss coefficient and learning rate of the generator (policy network).
- A population contains 12 training instances with each instance running 64 CPU actor jobs and 2 GPU jobs (1 for the discriminator and 1 for the generator)
- The batch size is set to 64 on both the policy learner and discriminator learner.
- The generated data is sampled uniformly from a replay buffer with a capacity of 20 batches.
Experiment Results
- They also trained a “blind” version of the agent, i.e., we do not feed intermediate canvas states as an input to the policy network. Though the result does not reach the level of performance of the full model, it can still produce sensible reconstructions which suggests that their approach could be used in the more general setting of program synthesis, where access to intermediate states of the execution pipeline is not assumed.
- They use Blocked Metropolis-Hastings (MCMC) as baseline in MUJOCO.
- There are reconstruction results for MNIST, OMNIGLOT and MUJOCO in the paper (Due to the large image and importance, I did not show here.)
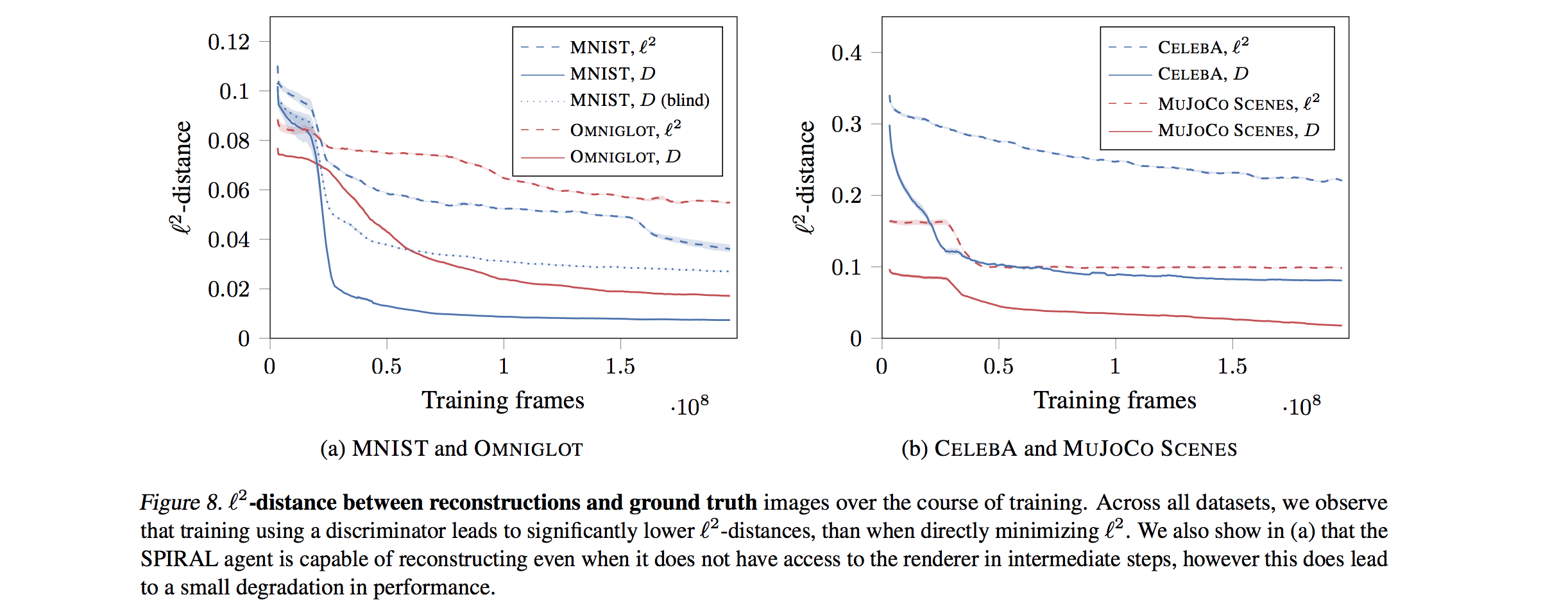
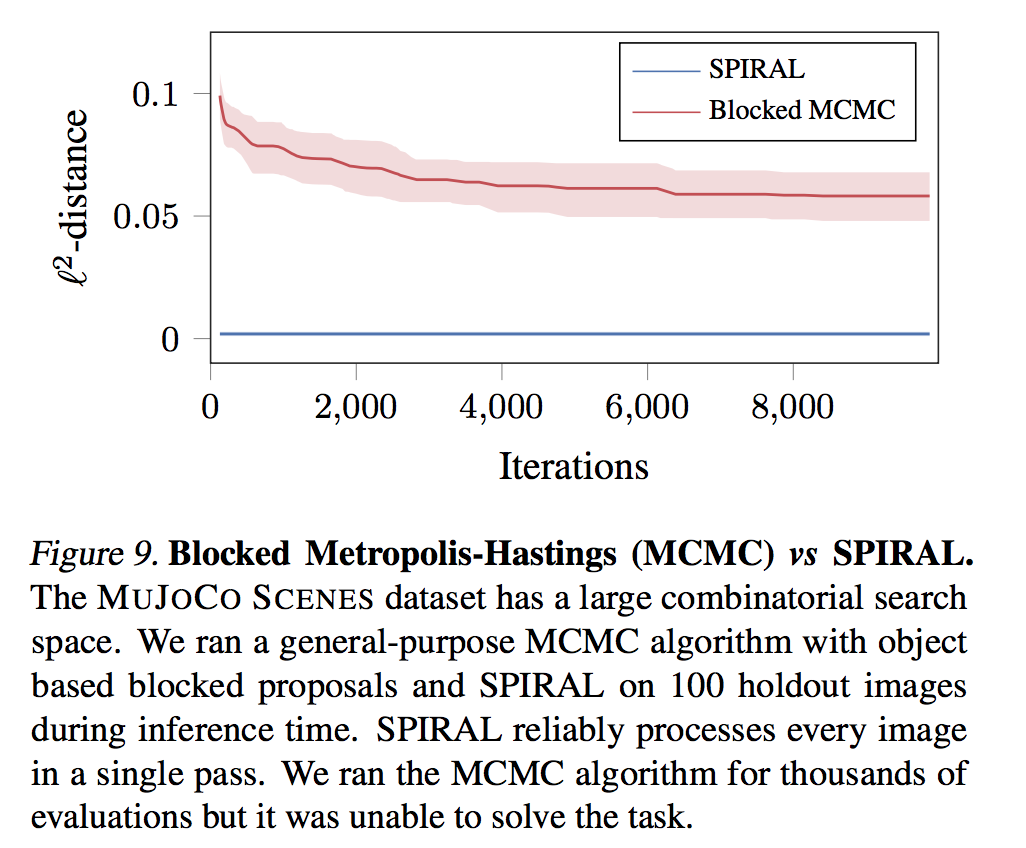
Insights
In practice for conditional generation of 2D images, they use the discriminator score as the reward for generator instead of L2 distance. The reason can be illustrated below:

Future Work for Improvement
- Better exploration: The current exploration strategy used in the agent is entropy-based, but future work should address this limitation by employing sophisticated search algorithms for policy improvement. For instance, Monte Carlo Tree Search can be used.
- Better representation for action spaces of stroke, 3D surfaces, planes and learned texture models to invert richer visual scenes.
- Better reward: A joint image-action discriminator similar to BiGAN/ALI (Donahue et al., 2016; Dumoulin et al., 2016) (in this case, the policy can viewed as an encoder, while the renderer becomes a decoder) could result in a more meaningful learning signal, since the discriminator will be forced to focus on the semantics of the image.
Related Work
- Neural Scene De-rendering by Jiajun Wu et al., CVPR 2017
- Learning to See Physics via Visual De-animation by Jiajun Wu et al, NIPS 2017 (spotlight)
- Population based training of neural networks by Jaderberg et al., 2017. See blog.
- Adversarial Feature Learning by Donahue et al., 2016.
- Adversarially Learned Inference by Dumoulin et al., 2016.