papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
Strategies for Training Large Vocabulary Neural Language Models
Metadata
- Authors: Wenlin Chen, David Grangier and Michael Auli
- Organization: Washington University and Facebook AI Research
- Conference: ACL 2016
- Paper: https://arxiv.org/pdf/1512.04906.pdf
Summary
This paper presents a systematic comparison of strategies to represent and train large vocabularies, including classical softmax, hierarchical softmax, target sampling, noise contrastive estimation and self normalization (infrequent normalization). They further extend self normalization to be a proper estimator of likelihood and introduce an efficient variant of softmax, differentiated softmax. They evaluated on 3 language modeling benchmark dataset: Penn Treebank, Gigaword and One Billion Word. They examine performance on rare words, speed/accuracy trade-off and complementarity to Kneser-Ney. Many insightful plots are presented in this paper (must read). Well written paper!
Problems of softmax
- Large vocabulary size makes softmax need more time to compute probability normalization over all the output class (vocabulary).
- Require more data to train in order to observe enough instances of rare words which increases training times.
- Regarding to the above problem, larger training data requires more training iterations.
Overview of Different Softmax Approximation Methods
- Softmax: Over all output classes.
- Hierarchical Softmax: Introduces latent variables, or clusters, to simplify normalization.
- Differentiated Softmax: Adjusting capacity based on token frequency (a novel variation of softmax which assigns more capacity to frequent words and which we show to be faster and more accurate than softmax).
- Target Sampling: Only considers a random subset of classes for normalization.
- Noise Contrastive Estimation: Discriminates between genuine data points and samples from a noise distribution.
- Infrequent Normalization (Self Normalization): Computes the partition function at an infrequent rate.
Findings
- Hierarchical softmax is less accurate than softmax on the small vocabulary Penn Treebank task but performs best on the very large vocabulary One Billion Word benchmark.
- Hierarchical softmax is faster and can perform more updates in the same amount of time comparing to others.
- Differentiated softmax can train better model in either small or large vocabulary, but need more time than Hierarchical softmax.
- Differentiated softmax can greatly speed up both training and inference. This is in contrast to Hierarchical softmax which is fast during training but requires more effort than softmax for computing the most likely next word.
- Training neural language models over large corpora highlights that training time, not training data, is the main factor limiting performance.
- Hierarchical softmax is the best neural technique for rare words since it is very fast.
- Differentiated softmax and hierarchical softmax are the best strategies for large vocabularies. Compared to classical Kneser-Ney models (using 5-gram KenLM), neural models are better at modeling frequent words, but they are less effective for rare words. A combination of the two is therefore very effective.
In-depth Hierarchical Softmax (HSM)
HSM organizes the output vocabulary into a tree where the leaves are the words and the intermediate nodes are latent variables, or class. The tree has potentially many levels and there is a unique path from root to each word (leaf). The probability of word is the product of the probabilities along the path from root, class, to the word itself.
They experiment with 2-level tree, which first predicts the class of the word c^t, and then predict the actual word w^t. Thus, the word probability (usually conditioned on context x) is computed as: p(w^t|x) = p(c^t|x) p(w^t|c^t, x).
Strategies for Clustering Words
HSM needs a pre-defined tree, thus we need to assign class for each word. Several strategies can be used:
- Random assignment
- Sorted by word frequency
- Cluster-based on word embeddings. (They experiment with Hellinger PCA over co-occurrence counts.)
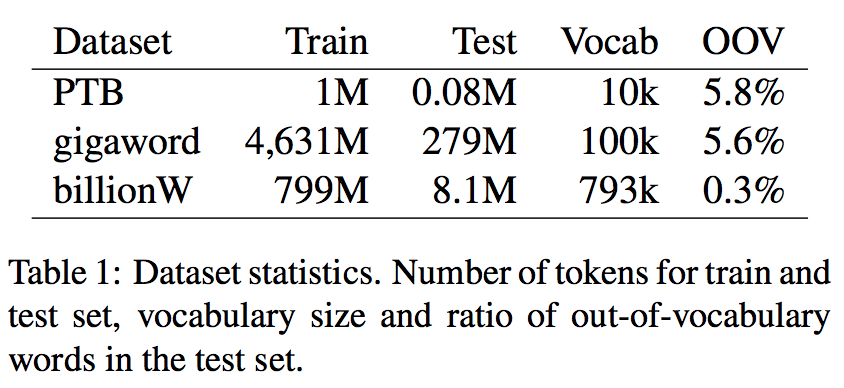
Dataset Statistics
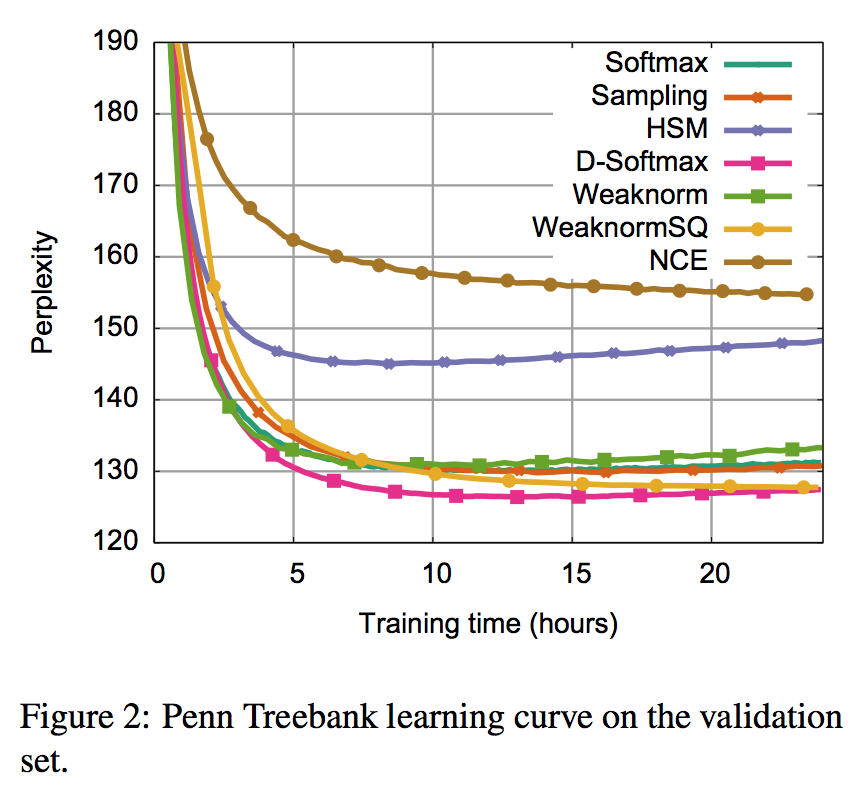
Experiment Settings: Training Time
They train for 168 hours (one week) on the large datasets (billionW, gigaword) and 24 hours (one day) for Penn Treebank.
Personal Thoughts
We may improve hierarchical softmax by giving a tree with good semantic clusters (using word2vec, glove or fasttext + clustering algorithm).
Reference
- (Must read) Related blog post: http://ruder.io/word-embeddings-softmax/
- Semantic trees for training word embeddings with hierarchical softmax: https://blog.lateral.io/2017/09/semantic-trees-hierarchical-softmax/