Deep Reinforcement Learning with a Natural Language Action Space
Metadata
- Authors: Ji He, Jianshu Chen, Xiaodong He, Jianfeng Gao, Lihong Li, Li Deng and Mari Ostendorf
- Organization: University of Washington and Microsoft Research
- Conference: ACL 2016
- Paper: https://arxiv.org/pdf/1511.04636.pdf
- Game simulator: https://github.com/jvking/text-games
Summary
This paper purposes a Deep Reinforcement Relevance Network (DQN-based) learn to understand the texts from both text-based state and action (learn the "relevance" between state and action) via playing a text-based game. The objective is to navigating through the sequence of texts (input state and output action) so as to maximize the long-term reward in the game (using Q-learning).
Text-based Games

- Parser-based (less complex action language): Typed-in commands such as "go east" or "get key".
- Choice-based and hypertext-based (more complex action language): Present actions after or embedded within the state text.
Deep Reinforcement Relevance Network (DRRN)

- The authors explained the success of the DRRN is due to the separation embedding space of state and action and interaction function (e.g., dot-product of state and action embeddings), resulting in a good estimation of Q-function.
- Bag-of-words (BOW) as text input feature.
- Difference vocabulary between state and action space.
- Action are selected from: argmax_{a_t^i} Q(s_t, a_t^i), where s_t and a_t^i are BOW representation, t denotes t-th time step and i denotes the i-th action (choice-based game).
Dataset Statistics
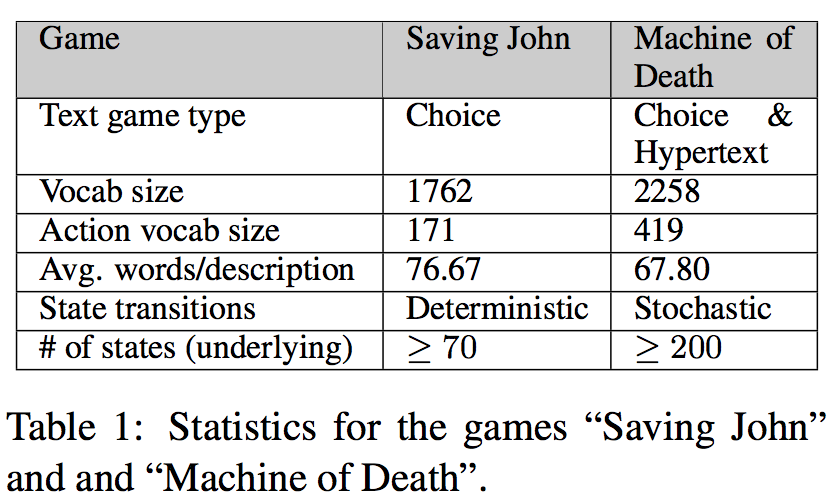
Result

Related Work
Narasimhan et al. use LSTM to characterize the state space in a DQN framework for learning control policies for parser-based text games. They show that more complex sentence representation can give further improvements. However, this paper tried LSTM in "“Machine of Death" and did not improve. This may due to the scale of the task or the embeddings need to be trained on large dataset.
Personal Thoughts
The vocabulary size of both state space and action space are relatively smaller than many NLP tasks. Wonder if it can still perform well when the vocabulary size is large.
References
- Language understanding for text-based games using deep reinforcement learning by Narasimhan et al. EMNLP 2015.