Compiler
 Compiler copied to clipboard
Compiler copied to clipboard
Lexer speedup
If you remove the support for the token namespaces, then can significantly speed up the Lexer. This will simply completely rewrite the algorithm.
Benchmarks:
- 3000 code lines
- 11867 tokens
- 5 times
Stand:
- i7 6700k
- Win 10
- PHP 7.1.11 (cli)
Hoa Original
Sources: Original Lexer
- 28.6555s
- 28.4433s
- 29.2020s
- 28.9820s
- 30.1294s
AVG: 29.0824s (408 token/s)
Compiltely rewritten (Hoa-like)
Sources: Rewritten Lexer
- 29.4850s
- 30.6486s
- 31.3297s
- 31.1340s
- 32.0120s
AVG: 30.9218s (383.7 token/s)
Fast Lexer (without namespaces support)
Sources: FastLexer
- 0.2046s
- 0.2085s
- 0.2194s
- 0.2124s
- 0.2009s
AVG: 0.2091s (56752.7 token/s)
Can it make sense to adapt it for Hoa and in those cases when the user's grammar contains only the default namespace to use the FastLexer implementation?
Hello,
I'm back from my paternity leave. I can finally answer your questions.
So, since token namespaces are dropped, a single regular expression is created which combined all token definitions, and then is used to match the data. The token name is used as the identifier of the named capture ((?<…>…)). I though about this in the past, but I didn't know how to make compatible with token namespaces. I'm glad you came with a similar approach. Using preg_replace_callback is the trick. Kudos :+1:.
The fact you iterate over the tokens with preg_replace_callback can be fast on small data, but it consumes memory because there is no real iteration over tokens: They are all generated at once. On a huge file, it is a significant difference. Can I see your benchmark please?
However, I think it is possible to have a similar algorithm with token namespaces. Instead of combining token definitions into a single pattern, it can possible to combine one pattern (of token definitions) per namespace and use preg_replace_callback_array. It is impossible to jump from one namespace to another with preg_replace_callback I guess; maybe it is possible with preg_replace_callback_array. Thoughts?
Anyway, if there is a single namespace, this optimisation is very interesting. I just would like to play with your benchmark a little bit if possible.
Are you willing to make a PR on hoa/compiler?
@Hywan Syntetic tests: https://gist.github.com/SerafimArts/a976562e388d6b8d8863941348720211
Outputs:

It is better to run these tests from different files.
However, I think it is possible to have a similar algorithm with token namespaces. Instead of combining token definitions into a single pattern, it can possible to combine one pattern (of token definitions) per namespace and use preg_replace_callback_array. It is impossible to jump from one namespace to another with preg_replace_callback I guess; maybe it is possible with preg_replace_callback_array. Thoughts?
I thought about it, but I do not have any really working code with such assembles with same namespaces. It is necessary to do either as done in re2c or flex, i.e. create a complete conversion (jump) table, or simplify and work as is.
Are you willing to make a PR on hoa/compiler?
The problem is quite large for adapting the algorithm to Hoa. I think that it will be easier for the author of Hoa to do it. The more this algorithm is already understood by the author, everything is pretty obvious (I'm just lazy). :D
👍 Very interesting ! (I've just encountered some large performance problems with Hoa/Compiler)
Hello! I transferred all the lexers into a separate component that does not depend on the parser and other pieces. It can also be used separately: https://github.com/railt/lexer
In addition, added support lexertl driver (https://github.com/BenHanson/lexertl), which speeds up another 8 times when compared with the previous version published above.
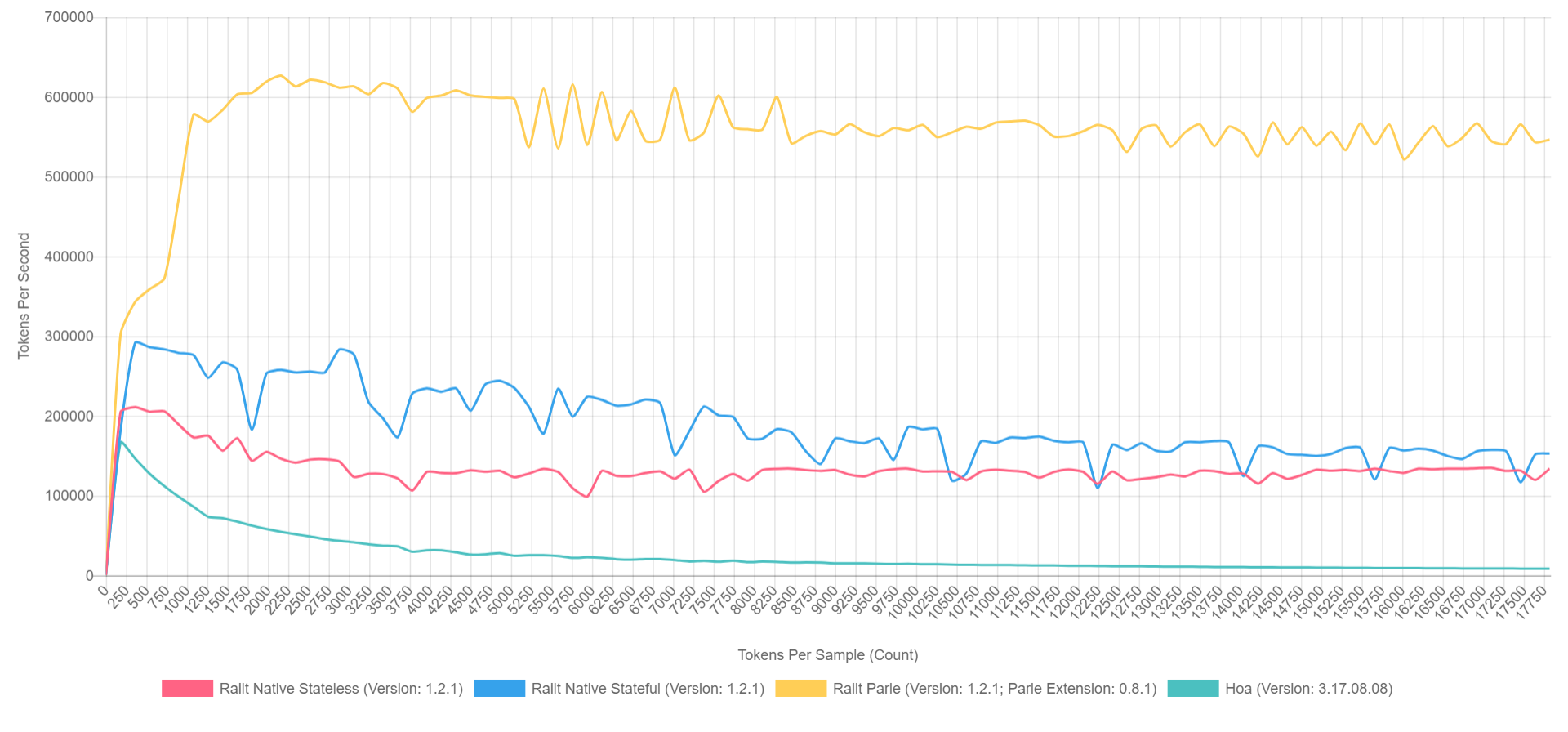
I can suggest using this component for lexical analysis, in cases when grammar tokens do not use namespaces.
@SerafimArts i don't understand how you connect the php code with the C++ library you linked. Care to explain ?
i don't understand how you connect the php code with the C++ library you linked.
@flip111 http://php.net/manual/ru/book.parle.php
It reminds me of http://nikic.github.io/2014/02/18/Fast-request-routing-using-regular-expressions.html#combined-regular-expressions
Also, try to make benchmark with S modifier: http://php.net/manual/en/reference.pcre.pattern.modifiers.php
S When a pattern is going to be used several times,it is worth spending more time analyzing it in order to speed up the time taken for matching. If this modifier is set, then this extra analysis is performed.
At present, studying a pattern is useful only for non-anchored patterns that do not have a single fixed starting character.
AFAIU, Lexer does not use ^, $, so in theory, it may give advantage when you need to call ->parse() many time, but it will give you performance degradation with a single call.
I'm trying to close huge projects at work, and I will get back on this issue, I hope shortly.
Modifier S, by the way, has been removed and is no longer supported in the current version of PHP (Since PHP 7.3 + PCRE v2)
Sources: FastLexer https://github.com/railt/railt/blob/8b1e327bb357a134b7ba5e52209796ba6597f3f6/src/Compiler/FastLexer.php#L82
yield from $result;
yield Token::eof($offset);
If I understand it right, it is just preparation for Generator (from interface point of view at least), but in fact it doesn't save memory.
I encountered with this issue (wanted to make possible parse from very long stream, for example). Probably, it can be resolved via limit (preg_replace_callback) param. When function stops, we check whether stream is closed or not and repeat since last offset.
preg_replace_callback doesn't have offset and preg_match_all doesn't have limit params. It looks like PHP is missing something like preg_matches(..., int $offset, int $limit): \Traversable. /cc @nikic
Few months ago I had to parse JSON file which had size over 500 GB (one big array with complex structured objects with random newlines). Yes, it was awful idea by the guys, but it could be useful to parse from streams as well. Finally, I found some library for PHP that parses content from streams (probably, this one: https://github.com/salsify/jsonstreamingparser, but I'm not sure).
Sorry for offtopic.
preg_replace_callback is very fast, but very memory-demanding implementation. Yep.
Theoretically, I can try to build a hybrid through preg_match and sampling through named groups, like:
\preg_match('/(?P<TOKEN_A>...)|(?P<TOKEN_B>...)/', ...);
This will significantly reduce the time spent on compiling PCRE in the classic version from Hoa and at the same time have the possibility of lazy calculations, which are not in the implementation of preg_replace_callback.
btw, few weeks ago I found out (*MARK) verb:
~
\G
(?|
(?:[^",\r\n]+)(*MARK:token0)
|
(?:"[^"\\]*(?:\\.[^"\\]*)*")(*MARK:token1)
|
(?:,)(*MARK:token2)
|
(?:\r?\n)(*MARK:token3)
|
[\S\s](*MARK:error)
)
~Jx
You can put arbitrary labels in the MARK (and put namespace there too, for example) if it is an issue (at least, it was a problem for me and I feel like you faced similar issue). (?| syntax by default requires to use the same named groups, so it wasn't possible to distinguish tokens among each other.
When you receive token with namespace, you can, for example, throw exception out of preg_replace_callback and execute different large compiled regex for different namespace since current offset.
However, as I said, preg_replace_callback doesn't have offset param, I personally used preg_match_all (it is more memory consuming, but looks like slightly faster than preg_replace_callback in described lexer implementation).
it is more memory consuming, but looks like slightly faster than preg_replace_callback in described lexer implementation
it does not allow to understand in what order the tokens are located.
However, as I said, preg_replace_callback doesn't have offset param
$offset = $offset + strlen($value); ;)
P.S. You can also read my article on Habr on this topic, where I cited different implementations as examples. But you should to translate it from the original language for understanding https://habr.com/ru/post/435102/
it does not allow to understand in what order the tokens are located.
? preg_match_all() with pattern above generates array of tokens in actual order.
<?php
preg_match_all(
'~\\G
(?|
(?:(.?)([<>=\\^]))(*MARK:T_ALIGN)
|
(?:[-+ ])(*MARK:T_SIGN)
|
(?:\\#)(*MARK:T_HASH)
|
(?:[0-9]+)(*MARK:T_WIDTH)
|
(?:,)(*MARK:T_COMMA)
|
(?:\\.(\\d+))(*MARK:T_PRECISION)
|
(?:[a-zA-Z%\\s:-]+)(*MARK:T_TYPE)
|
(?:\\})(*MARK:T_CL_PL__SWITCH__PLACEHOLDER)
|
(?:\\{([a-zA-Z][a-zA-Z0-9_.-]*)\\})(*MARK:T_NESTED_PL)
)~AJx',
',.42015+f{foo}{bar}',
$matches,
PREG_SET_ORDER
);
var_dump($matches);
array(6) {
[0]=>
array(2) {
[0]=>
string(1) ","
["MARK"]=>
string(7) "T_COMMA"
}
[1]=>
array(3) {
[0]=>
string(6) ".42015"
[1]=>
string(5) "42015"
["MARK"]=>
string(11) "T_PRECISION"
}
[2]=>
array(2) {
[0]=>
string(1) "+"
["MARK"]=>
string(6) "T_SIGN"
}
[3]=>
array(2) {
[0]=>
string(1) "f"
["MARK"]=>
string(6) "T_TYPE"
}
[4]=>
array(3) {
[0]=>
string(5) "{foo}"
[1]=>
string(3) "foo"
["MARK"]=>
string(11) "T_NESTED_PL"
}
[5]=>
array(3) {
[0]=>
string(5) "{bar}"
[1]=>
string(3) "bar"
["MARK"]=>
string(11) "T_NESTED_PL"
}
}
However, as I said, preg_replace_callback doesn't have offset param
$offset = $offset + strlen($value);;)
I mean, in order to restart preg_replace_callback with different regex (after changing namespace, state, scope, context, ...), you have to force preg_replace_callback to start with your offset. It doesn't allow it, so you have to cut string, probably. And this may have impact on performance (I didn't test it, though).
But more importantly for me, it is just not really comfortable API of PCRE in PHP. preg_match_all works fine, but may lead to memory overflow. However, input for my parser is not meant to be large; I'd rather expect many calls with more or less short strings (e.g. log template message).
So I don't see winners here, it depends, that's what I'm saying.
I mean, in order to restart preg_replace_callback with different regex
Yes it is. But in most cases it is possible to manage with one "state". The PCRE syntax is quite powerful.
For example, here are tokens of PHP language: https://gist.github.com/SerafimArts/bb9363fbd2d5cca8693cfcdc4631c2f7#file-lexer-php-L24-L178
Or GraphQL: https://github.com/railt/railt/blob/1e43c86734e3a7dc8f34172729246dec1fcdc5ff/resources/grammar/lexemes.pp2
For example, here are tokens of PHP language: https://gist.github.com/SerafimArts/bb9363fbd2d5cca8693cfcdc4631c2f7#file-lexer-php-L24-L178
How does it handle case like
"foo" //
<?php
// ...
without context/state ("out-of-code", "code")? Also, string literals looks simplified, i.e. you have to use another lexer lately to find all variables in double quoted strings, for example: "blah blah {$foo}". Another lexer is the same thing as lexer with 2 states/contexts, isn't it?
How does it handle case like ... without context/state ("out-of-code", "code")?
class PHPLexer extends Lexer
{
public function lex($sources): iterable
{
$enable = false;
foreach (parent::lex($sources) as $token) {
switch (true) {
case $token->is('T_OPEN_TAG'):
$enable = true;
break;
case $token->is('T_CLOSE_TAG'):
$enable = false;
break;
case $enable:
yield $token;
break;
}
}
}
}
i.e. you have to use another lexer lately to find all variables in double quoted strings, for example: "blah blah {$foo}". Another lexer is the same thing as lexer with 2 states/contexts, isn't it?
Yep. In this case, the second state is required. But I wrote that in most cases, and not always)))
@SerafimArts
case $token->is('T_OPEN_TAG'):
I think it doesn't work in general case, e.g.
// just HTML inline text block <?php
// the real comment
I think it doesn't work in general case, e.g.
https://gist.github.com/SerafimArts/bb9363fbd2d5cca8693cfcdc4631c2f7#file-lexer-php-L25
https://gist.github.com/SerafimArts/bb9363fbd2d5cca8693cfcdc4631c2f7#file-lexer-php-L25
I don't have ability to test it right now, but I suppose this lexer will treat first line as a comment, but in fact it is plain text + T_OPEN_TAG. And the real comment on second line only. So it still doesn't work properly without 2 explicit states.
Your point was
But in most cases it is possible to manage with one "state". For example, here are tokens of PHP language:
But it seems like example is not that convenient.
I don't have ability to test it right now, but I suppose this lexer will treat first line as a comment, but in fact it is plain text + T_OPEN_TAG. And the real comment on second line only. So it still doesn't work properly without 2 explicit states.
Oh, yes, I did not understand what you mean the first time. That's right, without two states, it's impossible to parse this =)
Could someone summarize this? I would like to know the following.
- What things can be put into actionable tickets for hoa/compiler
- What things are interesting for futher investigation.
Maybe i will come back later and try to answer these questions if they have not been answered yet.
Could someone summarize this?
Need to get rid of unnecessary calls preg_match. To do this, you can use the approach with named groups (?<NAME>...) with preg_replace_callback function or mark signes (*MARK:NAME) with preg_match_all function usage.
I implemented a simple multistate implementation based on the preg_match_replace algorithm using coroutines. You can use it as a basis: https://github.com/railt/lexer/tree/feature/multistate
Benchmarks: https://travis-ci.org/SerafimArts/lexer-benchmarks/builds