FcaFormer
 FcaFormer copied to clipboard
FcaFormer copied to clipboard
[ICCV 2023] Source code of "Fcaformer: Forward Cross Attention in Hybrid Vision Transformer"
Fcaformer: Forward Cross Attention in Hybrid Vision Transformer
Official PyTorch implementation of FcaFormer
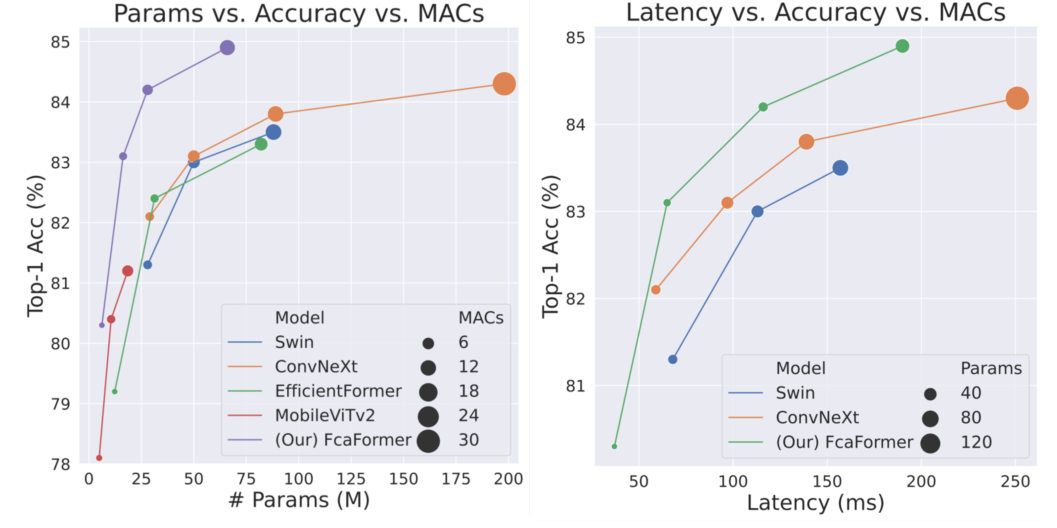
Comparison with SOTA models. The latency is measured on a single NVIDIA RTX 3090 GPU with batchsize=64.
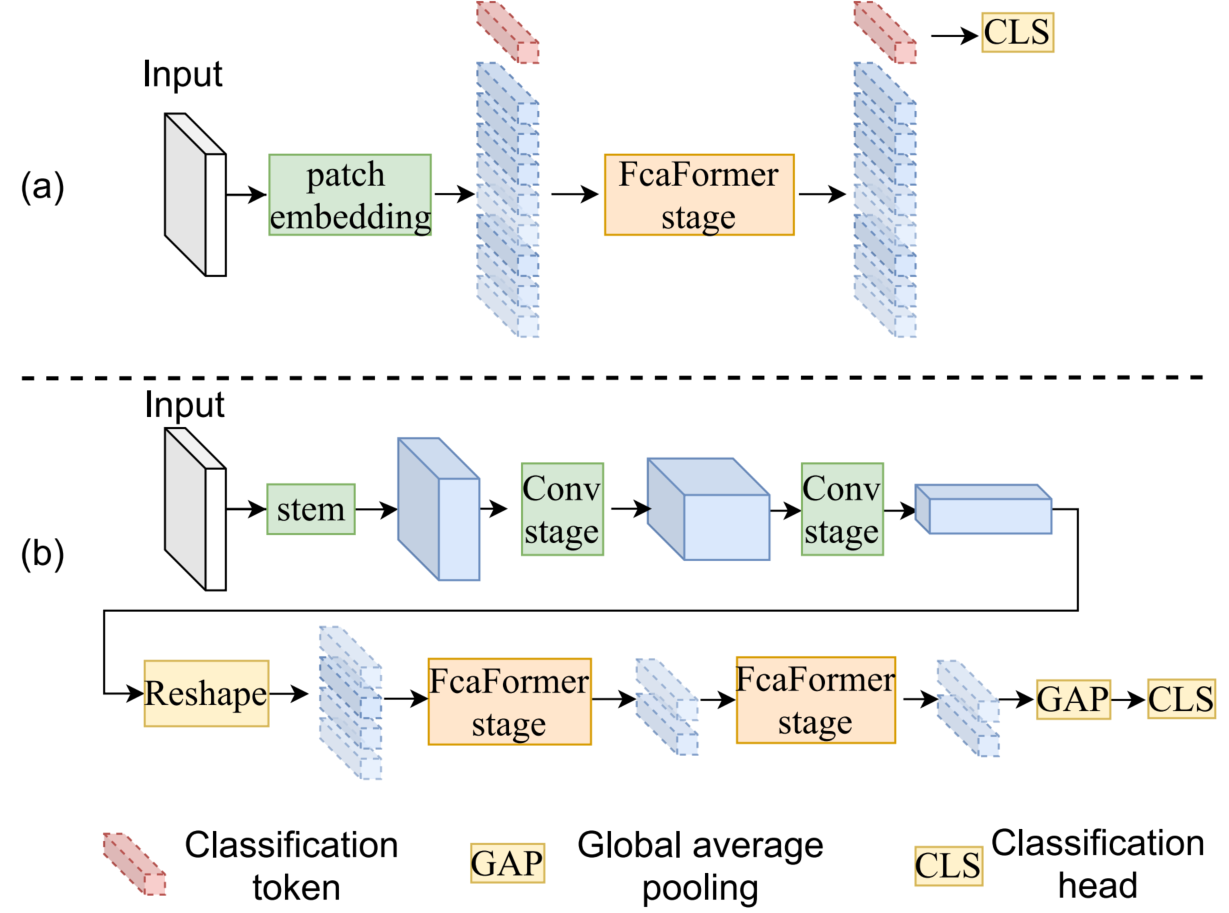
Architecture
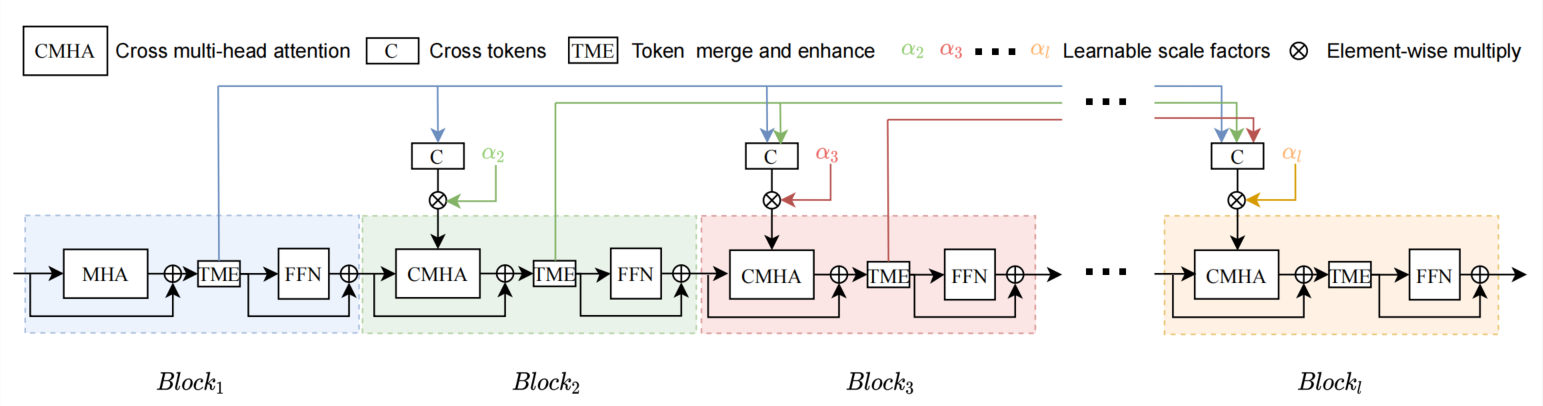
Introduction
Currently, one main research line in designing a more efficient vision transformer is reducing the computational cost of self attention modules by adopting sparse attention or using local attention windows. In contrast, we propose a different approach that aims to improve the performance of transformer-based architectures by densifying the attention pattern. Specifically, we proposed forward cross attention for hybrid vision transformer (FcaFormer), where tokens from previous blocks in the same stage are secondary used. To achieve this, the FcaFormer leverages two innovative components: learnable scale factors (LSFs) and a token merge and enhancement module (TME). The LSFs enable efficient processing of cross tokens, while the TME generates representative cross tokens. By integrating these components, the proposed FcaFormer enhances the interactions of tokens across blocks with potentially different semantics, and encourages more information flows to the lower levels. Based on the forward cross attention (Fca), we have designed a series of FcaFormer models that achieve the best trade-off between model size, computational cost, memory cost, and accuracy. For example, without the need for knowledge distillation to strengthen training, our FcaFormer achieves 83.1% top-1 accuracy on Imagenet with only 16.3 million parameters and about 3.6 billion MACs. This saves almost half of the parameters and a few computational costs while achieving 0.7% higher accuracy compared to distilled EfficientFormer.
Image classification on ImageNet 1k
| Models | #params (M) | MACs(M) | Top1 acc |
|---|---|---|---|
| Deit-T | 5.5 | - | 72.2 |
| FcaFormer-L0 | 5.9 | - | 74.3 |
| Swin-1G | 6.3 | 1.5 | 78.4 |
| FcaFormer-L1 | 6.2 | 1.4 | 80.3 |
| ConvNext-Tiny | 29 | 4.5 | 82.1 |
| Swin-Tiny | 29 | 4.5 | 81.3 |
| FcaFormer-L2 | 16.3 | 3.6 | 83.1 |
Semantic segmentation on ADE20K
| Method | Backbone | mIOU | #params | MACs |
|---|---|---|---|---|
| DNL | ResNet-101 | 46.0 | 69 | 1249 |
| OCRNet | ResNet-101 | 45.3 | 56 | 923 |
| UperNet | ResNet-101 | 44.9 | 86 | 1029 |
| UperNet | DeiT III (ViT-S) | 46.8 | 42 | 588 |
| UperNet | Swin-T | 45.8 | 60 | 945 |
| UperNet | ConNext-T | 46.7 | 60 | 939 |
| UperNet | FcaFormer-L2 | 47.6 | 46 | 730 |
Object detection on COCO
| Backbone | #params. | MACs | APbox | APbox50 | APbox75 | APmask | APmask50 | APmask75 |
|---|---|---|---|---|---|---|---|---|
| Mask-RCNN 3 × schedule | ||||||||
| Swin-T | 48 | 267 | 46.0 | 68.1 | 50.3 | 41.6 | 65.1 | 44.9 |
| ConvNext-T | 48 | 262 | 46.2 | 67.9 | 50.8 | 41.7 | 65.0 | 44.9 |
| FcaFormer-L2 | 37 | 249 | 47.0 | 68.9 | 51.8 | 42.1 | 65.7 | 45.4 |
| Cascade Mask-RCNN 3 × schedule | ||||||||
| X101-64 | 140 | 972 | 48.3 | 66.4 | 52.3 | 41.7 | 64.0 | 45.1 |
| Swin-T | 86 | 745 | 50.4 | 69.2 | 54.7 | 43.7 | 66.6 | 47.3 |
| ConvNext-T | 86 | 745 | 50.4 | 69.1 | 54.8 | 43.7 | 66.5 | 47.3 |
| FcaFormer-L2 | 74 | 728 | 51.0 | 69.4 | 55.5 | 43.9 | 67.0 | 47.4 |
Test on edge device
batch size=1, image size=224, four threads. ARM:Quad Core Cortex-A17
| Models | #params. | MACs | Latency (ms) | Memeory (M) | Acc (%) | pretrained weights |
|---|---|---|---|---|---|---|
| ConvNext-Tiny | 29 | 4.5 | 875 | 129 | 82.1 | - |
| ConvNext-Small | 50 | 8.7 | 1618 | 211 | 83.1 | - |
| ConvNext-Base | 89 | 15.4 | 2708 | 364 | 83.8 | - |
| ConvNext-Large | 198 | 34.4 | 5604 | 764 | 84.3 | - |
| Swin-Tiny | 29 | 4.5 | 588 | 139 | 81.3 | - |
| Swin-Small | 50 | 8.7 | 1576 | 222 | 83.0 | - |
| Swin-Base | 88 | 15.4 | 2624 | 378 | 83.5 | - |
| FcaFormer-L1(Micro) | 6.2 | 1.4 | 312 | 42 | 80.3 | - |
| FcaFormer-L2(Tiny) | 16 | 3.6 | 728 | 95 | 83.1 | FcaFormer-L2 Access Code:1234 |
| FcaFormer-L3(Small) | 28 | 6.7 | 1344 | 148 | 84.2 | - |
| FcaFormer-L4(Base) | 66 | 14.5 | 2624 | 328 | 84.9 | - |
Metadata
Owner
Metadata
[ICCV 2023] Source code of "Fcaformer: Forward Cross Attention in Hybrid Vision Transformer"