harfbuzz
 harfbuzz copied to clipboard
harfbuzz copied to clipboard
Tai Tham and USE
This issue follows on from issue #170 with a proposal based on research into a visual encoding. In order to test such a proposal, I am proposing we make the following special cases for the USE for Tai Tham:
| code | name | old category | new category |
|---|---|---|---|
| 1A56 | medial la | MBlw | SUB |
| 1A5A | sign low pa | FAbv | MAbv |
| 1A5B | high ratha or low pa | SUB | CMBlw |
| 1A61 | sign a | VPst | GB |
| 1A63 | sign aa | VPst | GB |
| 1A64 | sign tall aa | VPst | GB |
| 1A6D | sign oy | VPst | VBlw |
| 1A74 | mai kang | VMAbv | VAbv |
| 1A7A | ra haam | VAbv | FAbv |
| 1A7B | mai saam | VMAbv | FM |
| 1A7C | khuen-lue karan | FM | FAbv |
| 1A7F | cryptogrammic dot | FBlw | CMBlw |
Based on these changes, people can start implementing test fonts and keyboards towards deciding whether a visual encoding is the best solution for Tai Tham. In talking with folks interested in Tai Tham implementation, they all agree that this is the best first step forward. After all, Tai Tham is so broken in OpenType that having something is a good first step so long as people understand that this too may change.
Since the spacing vowel signs U+1A61, U+1A63, and U+1A64 cannot follow a sakot, GB would be a more appropriate category than B.
USE now overrides U+1A7B TAI THAM SIGN MAI SAM from FM to VMAbv. Do you propose it stay FM?
The old categories of U+1A74 and U+1A7C should be VMAbv. (U+1A7C used to be FM, and still is in HarfBuzz.)
. B -> GB sounds good to me. . Reverting U+1A7B from FM to VMAbv and back to FM: Yes please. Back to FM . U+1A74, U+1A7C: OK.
I have updated the original message and table accordingly.
L2/19-365 maps U+1A60 TAI THAM SIGN SAKOT to H instead of the bespoke category Sk. Should #1731 be reverted?
I note that Tai Tham users are still considered lower class beings who can have their working fonts arbitrarily broken yet again. (Experimentation should use a different script tag.) Moral: Use a hack font, not Unicode.
The proposed USE classification above does not accord with L2/19-365. To accord with the final character sequencing, the following should also be VMAbv along with the tone marks:
U+1A58 TAI THAM SIGN MAI KANG LAI U+1A59 TAI THAM CONSONANT SIGN FINAL NGA U+1A7A TAI THAM SIGN RA HAAM U+1A7C TAI THAM SIGN KHUEN-LUE KARAN
This is needed for sane rendering of U+1A59 (Laotians have rights!) and U+1A7A with tone marks.
To test the Hosken scheme, one also needs to check out the proposed formatting characters
U+1A8E TAI THAM SIGN INITIAL U+1A8F TAI THAM SIGN FINAL
Has any one any bright ideas on how to do that? The best idea I can come up with is to purloin the variation selectors U+FE0E and U+FE0F. The problem is that adding simulations of those proposed characters must not split script runs.
Everyone reading this medium is trying to get Tai Tham to work. All the "lower class being" and "Laotians have rights" kind of comments is irrelevant and distracting.
L2/19-365 maps U+1A60 TAI THAM SIGN SAKOT to H instead of the bespoke category Sk. Should #1731 be reverted?
For a trial of the new encoding, yes. Of course, the reversion will break any text that follows, mutatis mutandis, the proposals accepted for the original encoding. (Paradoxically, it would currently repair my fonts, which aren't ready for CVC but not CVCV to be accepted.)
I'm envisaging a transition program with 3 Tai Tham script codes: Lana, Lanx (experimental) and Lant (transitional). You might regard it as a pipe dream.
Lana attempts to support current encoding - its rendering would have little modification. Lanx attempts to support the new encoding (or approximation to it). It would initially be for the use of font developers and other hardy souls. Lant would be available once Lanx had stabilised or the new encoding been accepted by the UTC.
Lant would not insert dotted circles. Once the new encoding had been accepted, and the rendering had stabilised, the new rendering would be transferred to Lana, with the insertion of dotted circles, and support for Lant and Lanx would be dropped.
So: If Lanx is present, that is used. Otherwise, if Lant is present, use that. Else, use Lana.
Sensible combinations in participating fonts would be: Lana + Lanx (developer's version) Lana + Lant (for users transitioning data) - spell-checker support would be important. Lana (For users with only ephemeral data)
This would work best if HarfBuzz were the only renderer.
Everyone reading this medium is trying to get Tai Tham to work.
Tai Tham was just about working before the USE was adopted. There were some minor, simple to fix wrinkles left. I'm not sure the yet to be encoded kludge characters will work. At least 27% of Tai words in the script will have to be re-encoded (those with CVC syllables), plus another 6% in corpora that follow the proposals' vowel order. Even Pali, which is conventional Indian Indic with a dash of Tibetan, will have to have some modification, though nothing like as much.
Actually, we don't need much of this group of changes to be almost there. I looked at my random sample of words to see what is currently wrong. If we: (1) Make U+1A61, U+1A63, and U+1A64 GB (a hack I'd long pondered) (2) Accept the USE vowel sequencing of above and below (or reverse it) (3) Make U+1A56 MEDIAL LA class SUB (4) Accept that MEDIAL RA must be the last consonant of a cluster These are all in Martin's proposal.
We get 99.5% correct rendering with changes to only 7% of Tai vocabulary - mostly item (2). The problem with the rest of the sample is non-final U+1A7B MAI SAM, where we have a coding problem anyway. There are then peripheral problems that can be solved by grouping superscript final consonants in the same class tone marks. (They've shown up in text from outside Northern Thailand, so aren't represented in my random test.)
Here is the link to the random sample only the renderer code in your browser will have been updated recently.
1A58 1A59 1A7A 1A7C being changed for my proposed FAbv to VMAbv is of marginal value given there are no VMBlw or VMPst. I would still hold that FAbv is more appropriate given they are all final type characters and we would want them to occur following tone marks rather than mixed in with them.
We are not in a position to implement 1A8E/F yet and this whole process is about building the credibility to then propose their addition to Unicode and bringing around the nay sayers.
I have no problem if we want to introduce an intermediate script tag for this, but I don't think it will be easy to have two slightly differently tuned USE implementations in harfbuzz at the same time. This aims to be a low cost change that allows us to move nimbly rather than getting bogged down.
The core changes you suggest above are the same as I propose and the only other changes are pretty minor and disambiguate ordering confusion (as a visually motivated order aims to achieve).
I realise that you desire to minimise the impact that getting a good encoding for Tai Tham has on your previous work. But I would suggest that the relatively few people who are currently able to work with Tai Tham text are in a good position to carry the load of dealing with change more than the much larger user community that cannot engage at the moment due to lack of decent script support. Therefore I give pleas of "don't change existing fonts or data" less weight in my mind over getting the encoding right.
1A58 1A59 1A7A 1A7C being changed for my proposed FAbv to VMAbv is of marginal value given there are no VMBlw or VMPst. I would still hold that FAbv is more appropriate given they are all final type characters and we would want them to occur following tone marks rather than mixed in with them.
Who's 'we'? U+1A7A with tone mark has U+1A7A visually ordered before (left and below) the tonemark (Tai Khuen example), while U+1A59 with tone mark in cramped space has the tone mark to the right of U+1A59 (major Lao text book). I don't think this change matters for U+1A58 MAI KANG LAI. The old, still extant rendering of U+1A58 is as part of the next syllable. It calls out for handling by the reph feature, but that depends on the division into 'clusters', which cannot be controlled by the font. Co-occurrence of U+1A58 with a tone mark would be remarkable but is not inconceivable. I'm not sure about U+1A7C; it's co-occurrence with a tone mark would be remarkable (probably ungrammatical), but I think it is safer to try to keep the properties of U+1A7A and U+1A7C aligned, even though U+1A7C should never act as a consonant. (Having said that, there's one transliteration that treats it as a repha.)
The argument for forcing tone marks to follow in the encoding would be that both orders occur according to personal taste, and that we need a common ordering for search to work. What is the evidence of variable ordering in the lay-out?
The easiest way of reordering tone mark + final, superscript consonant is by formal ligature, which relies on their not being two tone marks together, While having 5 tone marks is bad enough, there are reports of another three tone marks out there, which are modern borrowings (directly or indirectly) of Thai mai tho, mai tri and mai chattawa. Wyn Owen reports mai tho from Tai Khuen (there may also be disputed evidence of it for Tai Lue), Kourilsky implies mai tri and mai chattawa for Lao (Tham script that is, not Lao script) and I've actually seen that pair in Northern Thai.
forcing tone marks to follow Please read as 'forcing tone marks to precede'.
Who's 'we'?
Why, the Queen and myself, of course!
The primary purpose in this 'visual' order is to arrive at a single consistent order. While it is convenient if that order makes rendering easier, it isn't necessary. Where people squeeze in tone marks is a stylistic issue and I see no value in complicating the encoding by treating finals as vowels just to get them before tone marks. So, I beg to differ and let's keep the order as listed above. Reordering two adjacent marks in OT either involves ligatures (which is ugly) or one lookup per one side of the pair. (One naturally chooses the side with the least number of glyphs in the class.) There are plenty of other areas where ordering doesn't perfectly fit rendering, even across new cluster boundaries. I think of sara am (U+1A63 U+1A74) as a prime example, where the U+1A74 goes over the U+1A63 in Khuen and over the preceding consonant in Lanna.
If people are borrowing tone marks from Thai into Khuen, I would suggest from some initial thought that they are merely variants of the 3 extra tone marks already encoded for Khuen. But I could well be wrong and we would need to address their encoding as we analyse them.
What evidence do you have of variation in relative position of final consonants and tone marks? When the original proposals were written, we had no evidence of how they interacted. I'm suggesting that treating final consonants as vowel marks works. 'Sara am' (or mai kam to use the native name) is a well known case of variation in layout; the UTC was wrong to decompose it.
and over the preceding consonant in Lanna.
That's an oversimplification - if you keep saying it you will deceive yourself. What is true is that positioning over the centre of the consonant seems to be restricted to Northern Thai, but Northern Thai shows a lot of variation.
I've already found that people see my use of the kha pe glyph (identical to mai chattawa) for TONE-4 as an error. Additionally, semantically based unifications that work for Tai Khuen don't necessarily travel well. It's the usage outside of Tai Khuen that complicates matters. I can imagine Northern Thai coming to contrast mai tho and TONE-5 (with the latter interpreted as TONE-2 but convert consonant to low class - and TONE-5 is a superscript '3').
I can understand why in Khuen someone may print a rahaam (U+1A7A) before a tone mark, given the greater regularising that has gone on in Khuen, which moves the rahaam left and into an upper vowel type position. For technical reasons, therefore, I can imagine they have the ability to shift a tone mark right but not left and so chose that position for this rare sequence. In Lanna, rahaam definitely hangs to the right. I enclose an example:
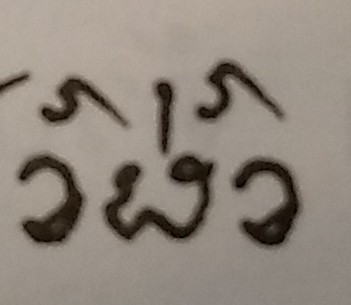
You already stated that they had to do something special with the rahaam or with the tone, so I suggest that we can safely leave the encoding order as it is.
For U+1A59, I can sympathise with it being treated, again, as if it were an upper vowel, taking the corresponding space. So if you really don't want to do the reorder for that one final, then I suppose I could entertain it having a category of VAbv. It's systematically, ugly, though. Are you sure you want that? Apart from saving a lookup, what does it gain us? It certainly messes with the idea that it is a final.
I don't have any printed examples, only handwritten examples. There's one problem with your example, though - it involves U+1A63 SIGN AA. It's highly reminiscent of the combination of tone and MAI KANG. How do you think the complete phonetic syllable should be encoded? To me it seems that <U+1A39 HIGH PHA, U+1A75 TONE-1, U+1A63 SIGN AA, U+1A7A RA HAAM> would be the natural encoding, and of course there's then no rendering level sanction unless someone adds it to a font.
Have you resolved how to distinguish the two Lao arrangements of base consonant, non-spacing subscript consonant, U+1A62 mai sat and sign aa? The Northern Thai writings I've seen are ambiguous between chained syllables and mai sat acting as mai kak. In the original encoding, a font could handle the Lao contrast by treating the order of mai sat and subscript consonant as significant for rendering. (I haven't noticed a difference in Northern Thai.)
I think one may occasionally have to resort to entering text codepoint by codepoint - complex input methods certainly occasionally breakdown on Ubuntu 16.04, and its reassuring to have an XKB keyboard layout as backup. To that end, it is good to be able to remember the order of the codepoints. With vowels below preceding vowels above, one gets a lot of simplifications:
- Onset consonants are dealt with with full consonants. (The consonant framework is primary.)
- Marks below then precede marks above.
- One doesn't have to worry whether MAI KANG is a vowel (as clearly the case in a very few words), a vowel modifier (as befits niggahita/anusvara/'bindu'), or just a final consonant (/w/, as well as the previous nasal rôles)
- The sequencing of RA HAAM doesn't depend on whether it is a vowel killer (so VAbv) or a final consonant.
- The sequencing of MAI SAT doesn't depend on whether it is a vowel, a vowel modifier (as when it shortens a vowel and, in most spelling styles, thereby affects the tone) or a final consonant (except with following vowels)./tu
It certainly makes sense for the equivalent writings ᨲᩩᩴ and ᨲᩩᩙ of /tuŋ/ to have parallel spellings. Storing the final consonant before the vowel (/u/) is not nice, but that's your preferred solution for final consonants in general.
-
Rahaam. Looking at the preceding -aa vowel with a rahaam over it, the rahaam following the tone and consonant is, OK not entirely clearly, not over the -aa. In the wider example of the text this is from (which shows lots of rahaams), the rahaam is always top right. And there is an example of a tone mark to the right of the rahaam as well. I do apologise for that oversight.
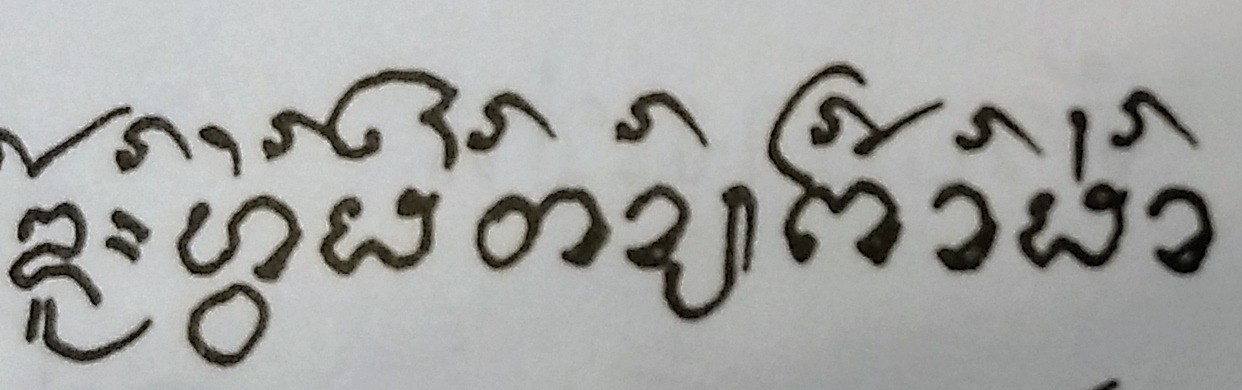 I still don't consider that it calls for rahaam to change order from FAbv.
I still don't consider that it calls for rahaam to change order from FAbv. -
Lao use of U+1A62 as mai sat or mai kak (if I understand correctly). Again, if I understand correctly, the text itself is ambiguous in that one cannot tell purely from shape or position which is being used. One has to use knowledge of the language. Therefore, we do not expect that the encoding will disambiguate them. But I may have completely misunderstood you on this.
-
I really like this idea of handling the few characters that can ambiguously act as vowels or finals or whatever, as you present. BTW the rahaam ambiguity is only resolved by this if there is no tone mark, but it's not important. Let's work with your idea a bit. Let's say we do that. But, or in addition, we take the principle that for a visual, fixed order, encoding, it doesn't actually matter what the order is, so long as it is defined and bases are bases. This means we could take the new combined set of VAbv/FAbv and move it all over to before VBlw and keep the USE happy. But there are clearly some characters which are never going to be in VAbv and would be silly to move over. These we can move back into FAbv. This is in effect what I have done.
Based on this thinking, the only question is which characters should go in FAbv instead of VAbv? Currently, including my proposal, we have 1A58-1A5A, 1A7A, 1A7C. What I am beginning to comprehend is that you consider 1A7A/C as acting like a vowel in that it kills just a vowel rather than the whole cluster. Looking at, for example ᩆᩢᨠ᩠ᨯᩥ᩺ MFL p694 where a rahaam follows a vowel, I realise that rahaam could never precede a vowel and therefore I would not want to have rahaam in free variable order with a VAbv. Having said that, VAbv stacks and therefore a wrong ordering would be visible. (Sorry for thinking at you). In addition, of the 300+ examples in MFL, I don't think I see any where the rahaam is just killing the vowel. Yes, it's ambiguous as to whether it is silencing just the final or the whole cluster, but not just the vowel. I'm still inclined to stick with FAbv for rahaam.
Sorry to take so long to get back to you. I've been busy rescuing and republishing the content of a Yahoo group. Today's the day the content is due to vanish. This post deals with point 2 above, which shows that my explanation of the issue was not clear enough. The system's input methods have failed and I'm going to have to reboot - I'm depending on the independent system in Emacs.
Visual ambiguity between mai sat and mai kak is not, so far as I am aware, a visual problem, though vowel v. shortener was a challenge for transliteration from Tai Tham to Thai. My solution was that short /ua/ is so rare that medial /wa/ should be the default reading. Mai sat v. mai kak in Northern Thai can usually be resolved by context - the problem areas seems to be where final /k/ gets reduced to a glottal stop in at least some speech, so one isn't sure whether it should be taken as double acting (taking both rôles) or not.
The problem word from Lao is the Tai Tham contraction of ຄັນວ່າ 'if'. In the authoritative text I've been working with, not only is the tone mark dropped, but so is the coda consonant /n/. The phonetic order encoding is <LOW KA, MAI SAT, SAKOT, WA, SIGN AA> ᨣᩢ᩠ᩅᩣ. The problem is the writing of the rime /aːk/ using mai kak. The prescribed encoding is <MAI SAT, SIGN AA>, and the Northern Thai writing I have seen is consistent - the mai kak is associated with consonant. (In particular, this applies to the rendering in the MFL: ᨸᩢᩣ Rev 1 p435, ᨾᩢᩣ Rev 1 548, ᩉᩖᩢᩣ Rev 1 p805.) Now Lao (both scripts) generally prefers to position marks above further to the right, and for the rime /aːk/, the mai kak is more clearly associated with the vowel. Indeed, Theppitak Karoonboonyanan has taken to encoding the rime in Lao (sensu lato) as <SIGN AA, MAI SAT>. Now, ຄວາກ is also a Lao word, and in Tai Tham (but I have no attestation) this is ᨣ᩠ᩅᩢᩣ <LOW KA, SAKOT, WA, MAI SAT, SIGN AA>. These two words are visually distinct in the Lao writing style used in the book, so they need to be encoded differently. On the other hand, encoding the words with the rime /aːk/ spelt using mai kak differently between the two languages is undesirable.
Now, with the logical order spelling, there is enough information for a font to render the two words differently.
The Lao text I've been analysing is:
1951, Phouy (Phaya Luang Maha Sena), Learn fast to read Tham characters in Lao Texts [ແບບຣຽນໄວ ເຫຼັ້ມນຶ່ງ ຣຽນອ່ານໝັງສືທັມຂຽນເປັນພາສາລາວ]
available at https://web.archive.org/web/20160429020009/http://www.laomanuscripts.net/downloads/tham_lao.pdf
The contracted word occurs on p27 ('mention') and at the end of the top line of p32 ('use'). The best example justifying my claimed Tai Tham form of ຄວາກ is ᨸᩢ᩠ᨠᨡ᩠ᩅᩢᩣ (= ປັກຂວາກ) on p44, at Row 3 Column 2 of the table.
Page 44 Row 3 Column 1 Orthographic syllable 2 is interesting. In the encoding of the accepted proposals, it is ᩈ᩠ᩃᩢᩣ <HIGH SA, SAKOT, LA, MAI SAT, SIGN AA>. Depending where the MAI SAT is rendered, one could get 3 possible Lao readings: /san laː/, /saʔ lan laː/ or /saʔ laːk/, though the second would be a bit of a guess. (I've arbitrarily guessed that Lao doesn't distinguish the anaptyctic vowel phonetically.) The phonetic order scheme would need a ZWNJ for the second possibility, which would be very rare.
RA HAAM as Vowel Killer
Are you aware of the Thai diacritic wanchakan (วัญฌการ)? That's the Thai analogue of RA HAAM not used as a consonant.
In all but two of the 18 words in the MFL whose final cluster is ᩃ᩺ <LA, RA HAAM>, the transliteration indicates, by lack of thanthakhat, that the consonant is sounded, and I have no reason to disbelieve it. One of them, ᨾᩫᨱ᩠ᨯᩫᩃ᩺, is given a phonetic respelling (to indicate that DA is pronounced like LOW TA), and the final cluster is represented by the Thai letter no nu, confirming that it is sounded. Two of the 16 are in borrowed compounds of English 'ball'; the final consonant is sounded in the corresponding loans into Siamese.
The space below the preceding base consonant is occupied, and this prevents the LA being subscripted to indicate that it is syllable-final; consciousness of the etymology seems to prevent the final consonant being rewritten as RA to indicate a final /n/. (Actually, ᨠᩢᨾᩛᩫᩃ᩺ has a commoner variant which I would back-transliterate to *ᨠᩣᩴᨻᩫ᩠ᨶ, which could be what gave rise to the surprising form ᨠᩣᩴᨻᩫᩖ recorded in the NTDPLM.)
The two exceptions are borrowings of English 'mail' and 'alcohol', where the 'l' is also silent in Thai.
In name plates and the like, final unsubscripted NGA frequently shows up with RA HAAM, as in the nameplate of Wat Mokhamtuang at the Wikipedia article for [url=https://en.wikipedia.org/wiki/Tai_Tham_script]Tai Tham script[/url]. I've not come across it in running text.
Now, if one has a word-final sequence -CCV and silence the vowel, in the Tai languages, one is left with a phonologically impossible sequence, which is resolved by not pronouncing the final consonant. This is how wanchakan becomes thanthakhat (the official name used for U+0E4C). Tai Tham usage is following the path of Siamese, and now also uses it to kill consonants in English loan words, and sometimes other letters in foreign words.
Your previous message expressed the desire that there be a visual distinction for low ka, sakot wa, mai sat, sign aa where the mai sat renders more over the sign aa. I can see two solutions to that:
- Use the two encodings as has been suggested (mai sat, sign aa and sign aa, mai sat)
- Use the to be proposed layout controls.
Either way, this issue can be addressed later and does not impact the proposed character categorisations. Just more noise in an already very noisy issue discussion.
The discussion regarding thanthakhat doesn't persuade me that we need to have two positions for ra haam in the encoding order, and thus the cost of such ambiguity. And the most natural place as I see it, is at the end of the syllable. I don't see any examples where it actually makes any difference. I see a few examples of rahaam co-occurring with an upper vowel (MFL p651, p704, p727!, p861) all of which have the thanthakhat syllable finally. There are no cases of rahaam co-occurring with a lower vowel. I think trying to move the rahaam forward will introduce more confusion than it solves. Hence, my desire to keep it as a F.
I don't want to cut off discussion. But the longer we drag on these digging in rabbit holes, the longer before we can get this implemented and the greater the likelihood that my window of opportunity to get a OT font done so that we can persuade the UTC of the need for the layout control, will close and delay things even further. Please, can we proceed and action this issue?
I've floated a suggestion on how we might conveniently test out SIGN INITIAL and SIGN FINAL at Adding Experimental Control Characters for Tai Tham.
We're waiting for Ebrahim to respond to the suggestion of Lanx.
Actually there are many cases of words with an undeniable vowel below and RA HAAM above. Firstly, it seems to have been quite a common way of writing final /n/ in the north when the vowel is a mark below. Secondly, the MFL has the word ᨾᩉᩣᩉᩥᨦ᩠ᨣᩩ᩺ 'giant fennel' on p. 537, where RA HAAM is a vowel killer. It just goes to show that the order 'vowel above, then vowel below' is bad. It gets really crazy when one has a vowel below, vowel above and tone mark. Nether top to bottom not bottom to top works with that order. As to writing anusvara and then vowel...
The layout controls work for khanwaa v. khwaak (ᨣ᩠ᩅᩢᩣ) will work, though calling the WA in the first word a 'final' is confusing. The point is that it phonetically follows the vowel of the cluster.
If you put the change in a different, new OpenType script, 'Lanx', and make it the preferred script for Tai Tham, you could implement Martin's request straight away.
If you put his changes in the script Lana, on what data should the Tai Tham Pali web data (e.g. on Wiktionary) change the encoding of -uṃ from <SIGN U, MAI KANG> to <MAI KANG, SIGN U>? I don't know the schedule for updating the shaper for MS Edge (Windows 7 to 11), Safari (iPhone 6, and later iPhones), Chrome and Firefox - and are they really synchronised?
Perhaps the solution is simply to abandon centralised shaping and let the fonts do it all - that now seems to work on Windows 10. The work done by the shaping engine for Tai Tham isn't difficult, even though some non-using fonts make a bad job of it. (Da Lekh already does the job itself to convert ASCII text to Tai Tham.)
I can do a proper review in a couple weeks, but this proposal seems like a plausible approach. There isn’t any concrete alternative proposal, so I guess we should implement this one.
It is not a good idea to introduce new script tags. 'lana' should select USE and will be unstable until Unicode gets their act together. In the meantime, DFLT is stable and will let fonts do whatever they want with minimal normalization and without any validation.
Where is this stability documented for Windows? With Noto Sans Tai Tham Regular Version 2.000, on Windows Version 10.10.17763.3165 (but frequently updated) <U+1A20, U+1A32, U+1A38, U+1A6E> renders as what looks like <uni1A20, uni1A6E, uni1A32, uni1A38> on Notepad but as what looks like <uni1A20, uni1A32, uni1A6E, uni1A38> in Microsoft Office Standard 2016. (Formally the uni1A6E actually gets ligated.)
What non-extraordinary action do you expect of Unicode?
Incremental improvements have been requested of HarfBuzz and refused, notably the support of CVCV syllables, which if done properly should reduce the pain of treating MAI SAM as a tone mark. (What works is treating Mai Sam as consonant_dependent, but Unicode rejected that on the grounds that the Indic Syllable Category property wasn't there to support the USE.)
Incremental improvements have been requested of HarfBuzz and refused,
I don't have the knowledge to decide on this, so previously I was reluctant to step away from the specs. Now that we have @dscorbett working on HarfBuzz, I trust his work on this and he is working on you now.
With Noto Sans Tai Tham Regular Version 2.000, on Windows Version 10.10.17763.3165 (but frequently updated) <U+1A20, U+1A32, U+1A38, U+1A6E> renders as what looks like <uni1A20, uni1A6E, uni1A32, uni1A38> on Notepad but as what looks like <uni1A20, uni1A32, uni1A6E, uni1A38> in Microsoft Office Standard 2016. (Formally the uni1A6E actually gets ligated.)
Background details:
Noto Sans Tai Tham Regular only has GSUB tables for the DFLT script. It has no glyph for U+25CC. All the relevant font-programmed activity is performed in the feature liga. For Notepad, what is happening is that USE is transposing vowel and consonant, and then visually feature liga transposes again, moving the vowel 2 places left instead of one. It appears that MS Word is not performing any font-directed shaping.
Curiously, for the real word ᨲᩕ᩠ᩅᨯ /thuːat/ <HIGH TA, MEDIAL RA, SAKOT, WA, DA>, Notepad does the rendering properly, but in MS Word the SAKOT and WA fail to ligate.
Explanation: It seems that both Notepad and Word are executing the USE, and for Notepad the liga feature is enabled when the DFLT script's GSUB is used, but is not enabled by MS Word.
Conclusion: Using the DFLT script for Tai Tham may not work at all with DirectWrite, and when it does it will require work-arounds to nullify the effects of the application of the USE that will occur on Windows 10. (Windows 11 is unexplored.)
I have not tested the work-arounds, but I think they are doable. Meanwhile, my test suite will be crippled by the loss of a Directwrite-using web browser.
I think I noticed the same issue with the liga feature and Notepad and Word 2016 with Limbu script (also routed to USE on Windows). I was able to fix the rendering (for Limbu) in Word 2016 by turning on ligatures. I typed the word ligatures in the box that says Tell me what you want to do. By enabling Standard Ligatures (or Standard and Contexual ligatures, or All Ligatures) the rendering was correct. This ligature option is available in some font dialog box, but I cannot find it at the moment. If I change the liga feature to rlig in the Limbu font, then Word displays correctly, without having to manually enable ligatures.