A rollout restart, or scale down of haproxy causes 503 connection timeout errors
I'm using helm to run HaProxy ingress with autoscaling enabled (chart version 1.21.1). Whenever an HaProxy pod terminates (because of a scale down event, or a rollout restart), I start seeing 503 backend connection timeout errors for a few seconds.
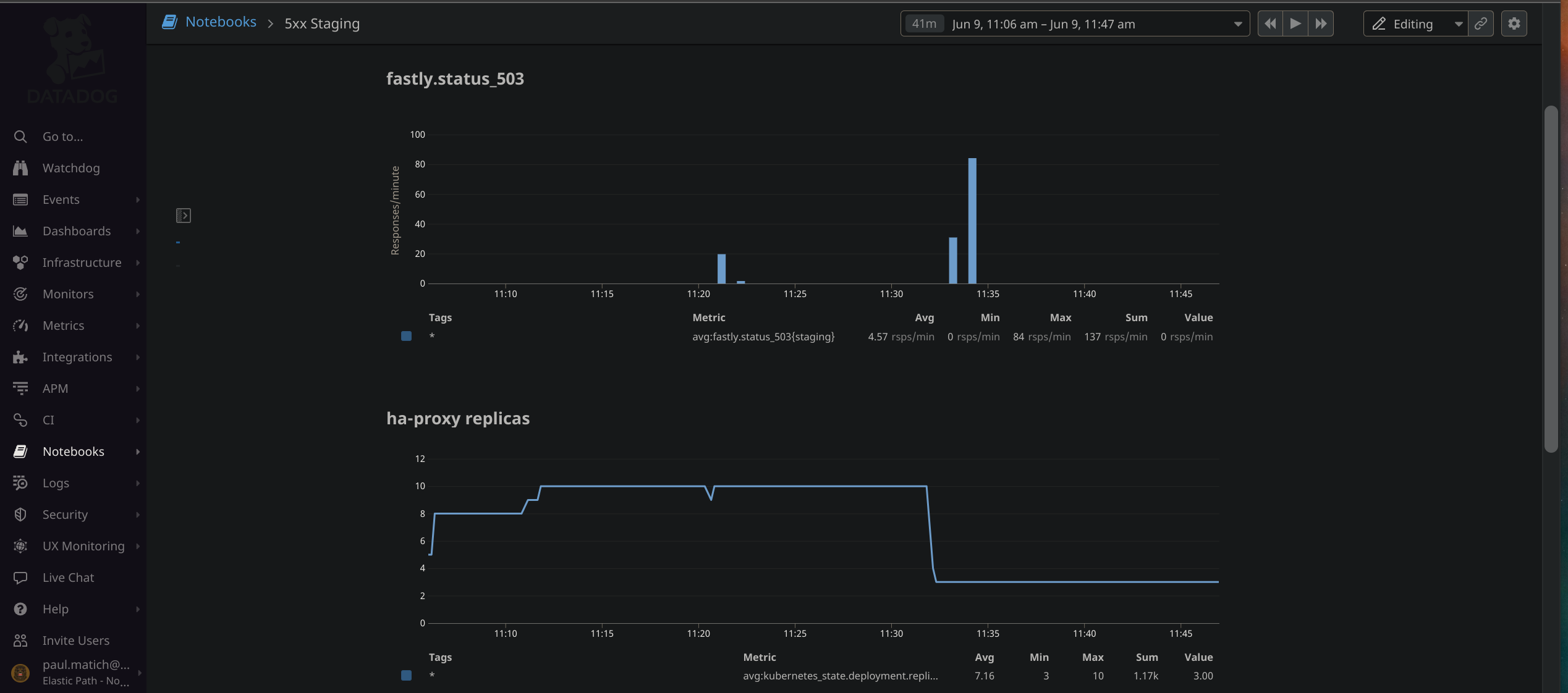
I tried adding the following example config for graceful shutdown, but that did not resolve the issue
## Example preStop for graceful shutdown
lifecycle: {}
preStop:
exec:
command: ["/bin/sh", "-c", "kill -USR1 $(pidof haproxy); while killall -0 haproxy; do sleep 1; done"]
This preStop action can't possibly be right due to s6 being used and s6-svc -1 /var/run/s6/services/haproxy should be used instead. Note that this issue is really not related to Helm Chart, but to Ingress Controller project.
Thanks @dkorunic I've opened a new issue in the Ingress Controller project. Maybe we should close this issue?
I'm not sure what you're referring to by s6 or s6-svc. Neither of those are in the preStop hook I tried.
Closing the ticket due to active https://github.com/haproxytech/kubernetes-ingress/issues/464.