docxBox
 docxBox copied to clipboard
docxBox copied to clipboard
CLI tool for Word DOCX templating and analysis

docxBox
CLI tool for Word DOCX templating and analysis.
Table of contents
-
Commands
- Unzip DOCX: All files, or only media files, format XML
- Zip files into DOCX
-
Output DOCX contents
- List files: All, filtered, images only
- List meta data
- List referenced fonts
- List fields
- Output XML
- Output document as plaintext
- Compare DOCX documents
-
Modify document
- Modify meta data
- Replace image
- Replace text
- Insert text into existing table
-
Replace by markup
- Insert heading
- Insert text
- Insert paragraph containing text
- Insert hyperlink
- Insert image
- Insert list
- Insert new table
- Remove content between text
- Set field value: Merge fields, generic fields
- Randomize document text
-
Batch Templating
- Replacement Pre/Post-Markers
- Arbitrary manual and scripted anlysis / modification
- Output docxBox help or version number
- Configuration
- Build Instructions
- Running Tests
- Code Convention
- Changelog
- Roadmap
- Bug Reporting and Feature Requests
- Third Party References
- License
Commands
Unzip DOCX: All files, or only media files, format XML
Unzip all files: docxbox uz foo.docx
Unzip only media files:
docxbox uzm foo.docx
or docxbox uz foo.docx -m
or docxbox uz foo.docx --media
Unzip all files and indent XML files:
docxbox uzi foo.docx
or docxbox uz foo.docx -i
or docxbox uz foo.docx --indent
Zip files into DOCX
docxbox zp path/to/directory out.docx
Compress XML, than zip files into DOCX:
When having indented XML
(i.e. via uzi command) for manual
manipulation, the zpc command compresses (= unindents) all XML files before
zipping them into a new DOCX:
docxbox zpc path/to/directory out.docx
Output DOCX contents
List files: All, filtered, images only
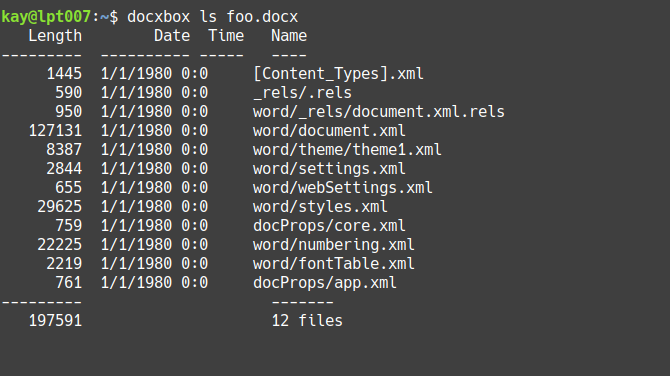
Lists files contained within a given DOCX, and their attributes:
docxbox ls foo.docx
To output as JSON:
docxbox lsj foo.docx
or docxbox ls foo.docx -j
or docxbox ls foo.docx --json
Filter by wildcard
docxbox ls foo.docx *.xml Lists only files ending w/ .xml
List all files containing string or regular expression
docxbox lsl foo.docx foo Lists all files containing the string foo
or docxbox ls foo.docx -l foo
or docxbox ls foo.docx --locate foo
This command is a shorthand to the grep tool (must be installed on your system
when using this command).
The search-string therefor can also be given as a regular expression:
docxbox lsl foo.docx '/[0-9A-Z]\{8\}/'
Lists all files containing 8-digit IDs, e.g. word recent session IDs
(ISO/IEC 29500-1).
List all files containing string or regular expression as JSON
docxbox lslj foo.docx foo
or docxbox lsl foo.docx -j foo
or docxbox ls foo.docx -lj foo
or docxbox lsl foo.docx --json foo
or docxbox ls foo.docx --locate -j foo
or docxbox ls foo.docx --locate --json foo
List image files
Output list of contained images and their media attributes (like width, height, encoding, compression, etc.)
docxbox lsi foo.docx
or docxbox ls foo.docx -i
or docxbox ls foo.docx --images
To output as JSON:
docxbox lsij foo.docx
or docxbox lsi foo.docx -j
or docxbox ls foo.docx -ij
or docxbox lsi foo.docx --json
or docxbox ls foo.docx --images --json
Note: Media attributes are read using the
file command, which must be installed on your
system (but usually should be already) when using docxBox's lsi command.
List meta data
docxBox displays only attributes that are contained within the current DOCX file (the attributes can vary by DOCX version and word processor used for creation), also if given empty.
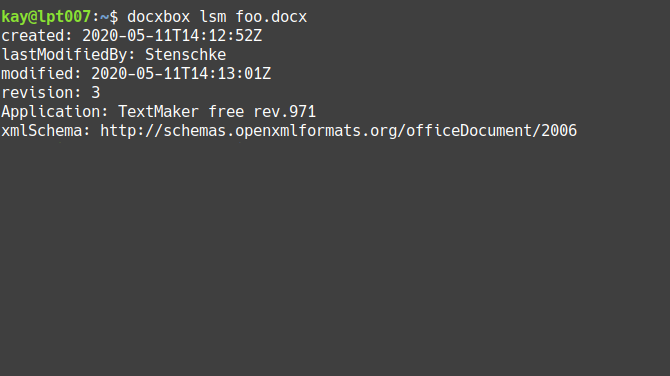
Output meta data of given DOCX:
docxbox lsm foo.docx
or docxbox ls foo.docx -m
or docxbox ls foo.docx --meta
To output as JSON:
docxbox lsmj foo.docx
or docxbox lsm foo.docx -j
or docxbox ls foo.docx -mj
or docxbox lsm foo.docx --json
or docxbox ls foo.docx --meta --json
Reference: Recognized meta attributes
-
Authors: Creator, lastModifiedBy (
<dc:creator>and<cp:lastModifiedBy>of docProps/core.xml) -
Dates (ISO 8601): Creation-, modification and print-date
(<dcterms:created>and<cp:modified>and<cp:lastPrinted>of docProps/core.xml) -
Descriptions: Description, Keywords, Subject, Title
(<dc:description>,<dc:keywords>,<dc:subject>,<dc:title>of docProps/core.xml) -
Language (
<dc:language>of docProps/core.xml) -
Revision (
<cp:revision>of docProps/core.xml) -
Application created with and its version, name of used template, company,
XML schema of document (
<Application>,<AppVersion>,<Template>,<Properties xmlns ...and<Company>of docProps/app.xml)
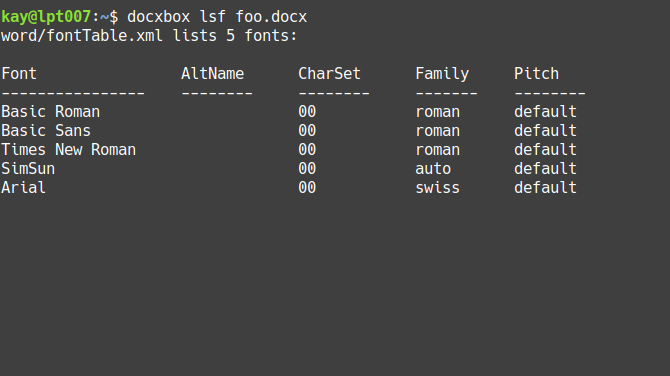
List referenced fonts
docxbox lsf foo.docx
or docxbox ls foo.docx -f
or docxbox ls foo.docx --fonts
To output as JSON:
docxbox lsfj foo.docx
or docxbox lsf foo.docx -j
or docxbox ls foo.docx -fj
or docxbox lsf foo.docx --json
or docxbox ls foo.docx --fonts --json
List fields
docxbox lsd foo.docx
or docxbox ls foo.docx -d
or docxbox ls foo.docx --fields
To output as JSON:
docxbox lsdj foo.docx
or docxbox ls foo.docx -dj
or docxbox lsd foo.docx --json
or docxbox ls foo.docx --fields --json
Output XML
docxbox cat foo.docx word/_rels/document.xml.rels
outputs the given file's XML, indented for better readability.
Hint: For viewing or editing complex XML, e.g. with syntax highlightning,
you can use your favorite text editor via the
cmd command
Output document as plaintext
docxbox txt foo.docx outputs the given document's plaintext
(ATM: w/o header and footer)
Output plaintext segments:
docxbox txt foo.docx -s
or docxbox txt foo.docx --segments
Outputs the plaintext from document, with markup sections separated by newlines. This can be helpful to identify "segmented" sentences: Texts which visually appear as a unit, but are declared within multiple separate XML elements (due to formatting or change-tracking purposes).
Compare DOCX documents
docxBox helps tracing changes to the files contained within DOCX archives, made when manipulating documents in word processor applications.
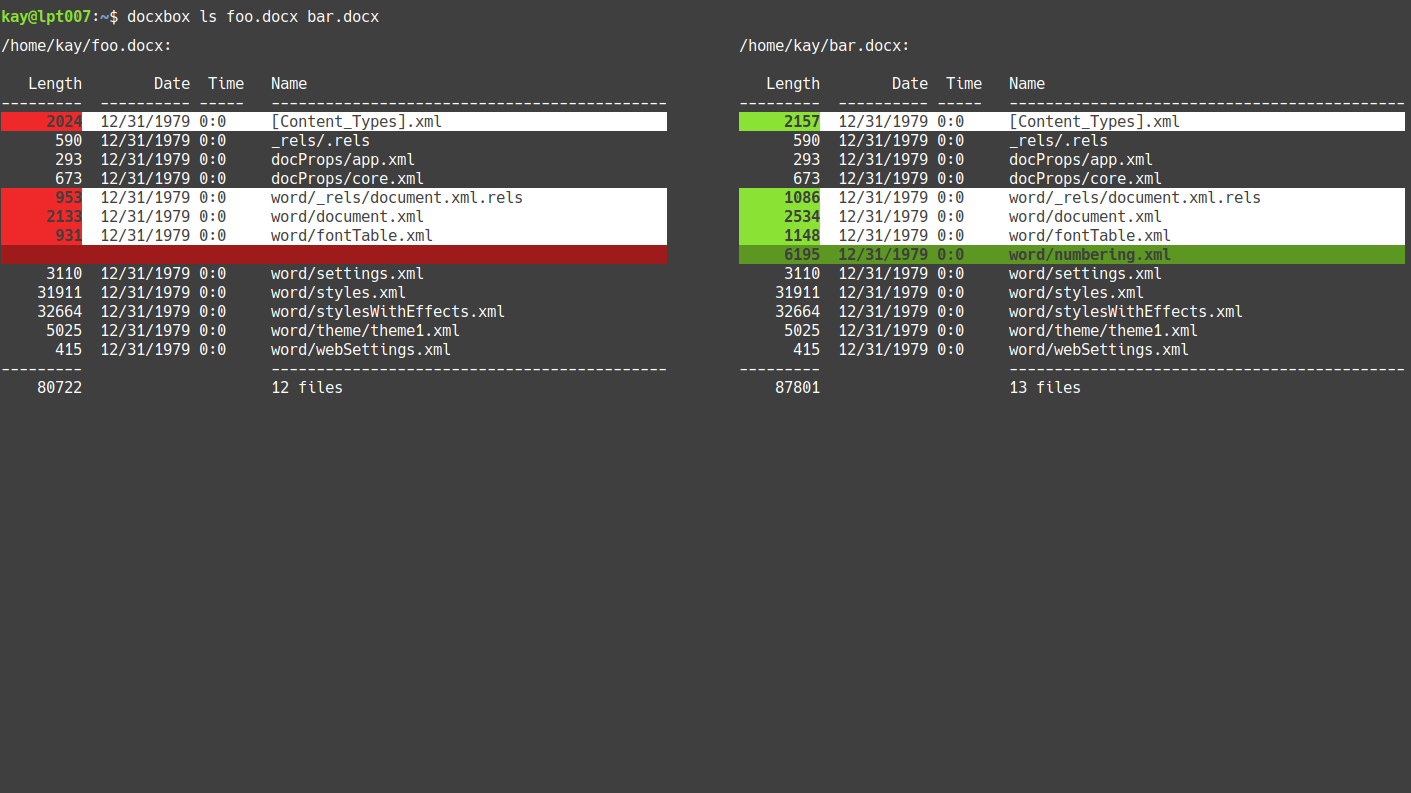
When given two DOCX files, the ls command lists all files of both DOCX
documents side-by-side. docxBox compares all files and highlights files
w/ different attributes or (identical attributes but) different content.
docxbox ls foo_v1.docx foo_v2.docx
Note: Comparisons are always output as plaintext, JSON output is not supported.
Compare specific file from two DOCX archives
Files that have changed between versions of a document, can be inspected using
the diff tool (which must be installed on your system).
Display side-by-side comparison of the formatted XML of given file
(word/settings.xml), with differences indicated:
docxbox diff foo_v1.docx foo_v2.docx word/settings.xml
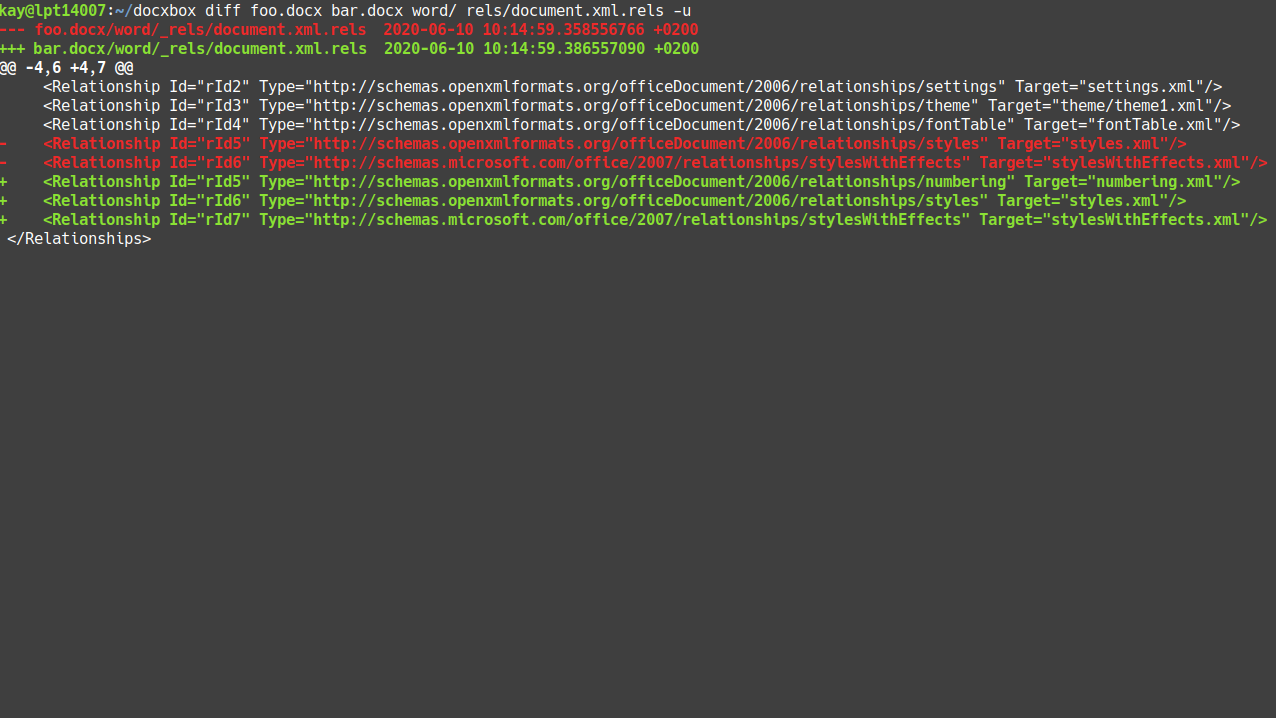
Display unified diff:
docxbox diff foo_v1.docx foo_v2.docx word/settings.xml -u
or: docxbox diff foo_v1.docx foo_v2.docx word/settings.xml --unified
Modify document
Modify meta data
docxBox allows to modify existing attributes, or adds attributes if not present.
- Set creation-date:
docxbox mm foo.docx created "2020-01-29T09:21:00Z" - Set creator attribute:
docxbox mm foo.docx creator "docxBox v0.0.1" - Set description attribute:
docxbox mm foo.docx description "Foo bar baz" - Set keywords attribute:
docxbox mm foo.docx keywords "Foo bar baz" - Set language attribute:
docxbox mm foo.docx language "en-US" - Set lastModifiedBy attribute:
docxbox mm foo.docx lastModifiedBy "docxBox v0.0.1" - Set lastPrinted attribute:
docxbox mm foo.docx lastPrinted "2020-01-10T10:31:00Z" - Set modification-date:
docxbox mm foo.docx modified "2020-01-29T09:21:00Z" - Set revision attribute:
docxbox mm foo.docx revision 2 - Set subject attribute:
docxbox mm foo.docx subject "Foo bar" - Set title attribute:
docxbox mm foo.docx title "Foo bar, baz"
Notes:
- Altering meta data does NOT automatically update preview texts of
generic fields, which display respective meta data.
For updating field values, use thesfvcommand. - All modifications automatically update the
modification-dateattribute to the current timestamp, unless explicitly setting a different one. - During Batch Templating the
modification-dateis not updated automatically.
To alter/insert an attribute and save the modified document to a new file:
docxbox mm foo.docx <attribute> <value> new.docx
To update multiple meta attributes with one mm command, tuples of
attribute-keys and -values can be given as JSON:
docxbox mm foo.docx "{\"<attribute>\":\"<value>\",\"<attribute>\":\"<value>\", ...}" new.docx
Replace image
docxbox rpi foo.docx image1.jpeg /home/replacement.jpeg overwrites the
DOCX w/ the modified document.
Note: The original and replacement image must be of the same format (bmp, gif, jpg, etc.).
docxbox rpi foo.docx image1.jpeg /home/replacement.jpeg new.docx
This creates a new file: new.docx
Replace text
Replace all (case-sensitive) occurrences of given string in DOCX text:
docxbox rpt foo.docx old new updates foo.docx
docxbox rpt foo.docx old new new.docx creates a new file new.docx
Insert text into existing table
stv inserts values (and cells if needed) into an existing table, starting at
1st cell of given row. If there are less columns in the row than values given,
more rows are added after the row.
This is useful for maintaining a specific table style (borders, coloring, font, etc.) when rendering dynamic documents from DOCX templates.
Example: Fill/Insert four cells starting w/ second row of first table in
document:
docxbox stv foo.docx "{\"table\":1,\"row\":2,\"values\":[\"foo\",\"bar\",\"baz\",\"qux\"]}
Note: Table and rows are indexed starting w/ 1 (not 0).
The table and row to start inserting data into can also be identified by text (distinct within the document) contained within a cell of that table and row:
docxbox stv foo.docx "{\"cell\":\"insert-data-here\",\"values\":[\"foo\",\"bar\",\"baz\",\"qux\"]}
Replace by markup
Moreover replacing text and fields, docxBox supports rendering and inserting the following Office Open XML elements:
- Heading 1, 2, 3
- Text
- Paragraph containing text
-
Image (formats:
bmp,emg,gif,jpeg,jpg,png,tif,tiff,wmf) - Table
- Unordered list
Markup specification for such elements must be given as JSON, following these rules:
- JSON must be wrapped within
{...} - The first item must be a type identifier (
h1,h2,h3,img/image,ol,table,ul) - All attributes are given associative (as JSON object related to the type)
- The order of attributes within the config of the type is arbitrary
Insert heading
Example: Replace string search by a Heading 1 with the text
Foo:
docxbox rpt foo.docx search "{\"h1\":{\"text\":\"Foo\"}}"
docxBox supports rendering of Header 1, 2 and 3 (h1, h2, h3).
Insert text
Example: Replace string search (by a new run) with the text
Foo:
docxbox rpt foo.docx search "{\"text\":{\"text\":\"Foo\"}}"
Insert paragraph containing text
Example: Replace string search (by a new paragraph containing a run)
with the text Foo:
docxbox rpt foo.docx search "{\"p\":{\"text\":\"Foo\"}}"
Insert hyperlink
Example: Replace string search by a hyperlink:
docxbox rpt foo.docx search "{\"link\":{\"text\":\"docxBox\",\"url\":\"https://github.com/gyselroth/docxbox\"}}"
Insert list
Replace string search by an unordered list:
docxbox rpt foo.docx search "{\"ul\":{\"items\":[\"item-1\",\"item-2\",\"item-3\"]}}"
Insert image
Image markup specification example:
{
"img":{
"name":"example.jpg",
"offset":[0,0],
"size":[2438400,1828800]
}
}
Specification rules:
- The
nameparameter is optional - The
offsetargument is optional - Image size is per default expected to be given in EMUs
(= English Metric Unit, being:
pixels * 9525), but can also be specified in Pixels like:"size\":[\"256px\",\"192px\"]
When inserting a new image file, it must be given as additional argument:
docxbox rpt foo.docx search "{\"image\":{\"size\":[2438400,1828800]}}" images/ex1.jpg
Insert new table
To replace text by a newly rendered table like:
| A | B | C |
|---|---|---|
| a1 | b1 | c1 |
| a2 | b2 | c2 |
| a3 | b3 | c3 |
the table specification as JSON looks like:
{
"table":{
"columns":3,
"rows":3,
"header":["A","B","C"],
"content":[
["a1","b1","c1"],
["a2","b2","c2"],
["a3","b3","c3"]
]
}
}
Specification rules:
-
headeris optional, when given:columnsis optional -
contentis optional, when given:rowsis optional
Replace search by table:
docxbox rpt foo.docx search "{\"table\":{\"header\":[\"A\",\"B\",\"C\"],\"content\":[[\"a1\",\"a2\",\"a3\"],[\"b1\",\"b2\",\"b3\"],[\"c1\",\"c2\",\"c3\"]]}}"
Remove content between text
Remove content between (and including) given strings (left and right):
docxbox rmt foo.docx left right updates foo.docx
docxbox rmt foo.docx left right new.docx creates a new file new.docx
Set field value: Merge fields, generic fields
Merge fields
When setting the value (text) of a merge field, the merge field is reduced to its textual component (maintaining its visual style).
Note: A particular merge field can NOT be merged repeatedly: merging turns the former field into a text element (the field subsequently does not exist as such any more).
docxbox sfv foo.docx "MERGEFIELD foo" bar (Updates foo.docx)
Changes all merge fields, whose identifier begins with foo,
into the text bar.
docxbox sfv foo.docx "MERGEFIELD foo" bar new.docx
Saves the resulting DOCX to a new DOCX file: new.docx
Hint: To find out field identifiers use docxBox's lsd
command.
Generic fields
Setting field values includes also preview texts of otherwise generic fields, which in some word processing applications have to be updated explicitly.
docxbox sfv foo.docx "PRINTDATE" "10.01.2020"
Updates the shown text of all print-date fields to 10.01.2020.
Randomize document text
Replace all text of an existing document by similarly structured random "Lorem Ipsum" dummy text, helpful for generating DOCX documents for testing purposes:
docxbox lorem foo.docx updates foo.docx
docxbox lorem foo.docx new.docx creates a new file new.docx
Batch Templating
docxBox's batch templating mode allows to perform an arbitrary sequence of operations (supporting all docxBox commands for document manipulation) upon a given DOCX. It thereby facilitates a more extensive range of templating options than the commands directly (= without batch templating) available.
Example: docxBox does not directly support replacing merge fields by other than plain textual content. Via batch templating, merge fields can be transformed into text in one step of a sequence, which can completely or in part, in a later step be replaced by generic content like for example a table, which can later be filled with more content.
Replacement Pre/Post Markers
Batch templating can make use of "markers": optional text elements containing a distinct identifier string. Markers can temporarily be inserted and can subsequently be replaced again at a later step of the batch sequence by other generic content.
Rules:
- Markers can be added before (key:
pre) and after (key:post) the actual generic replacement content - Markers can either be of the type
textorparagraph(orp) to insert surrounding line-breaks - Markers contain a textual identifier, which can use any text (but should be distinct within the document)
Batch sequence JSON
Sequences of templating steps to be batch-processed must be given like:
{
"<STEP_ID>": {"<COMMAND>": [("<ARGUMENT_1>",)(,"<ARGUMENT_2>",...)]},
"<STEP_ID>": {"<COMMAND>": [("<ARGUMENT_1>",)(,"<ARGUMENT_2>",...)]},
...
}
Example:
{
"1": {"mm": ["description", "foo"]},
"2": {"rpt": ["bar", "baz"]},
"3": {"rpt": [
"qux",
{"h1": {"text": "Quux"}}
]}
}
Rules:
- Every step must be given as a tuple of step-ID and -parameters
-
<STEP_ID>is an arbitrary string, must be distinct within the sequence - Parameters must be given as a tuple of a command and its respective arguments
-
<COMMAND>accepts any of docxBox's commands for DOCX manipulation (rmt,rpi,rpt,lorem,mmandsfv) -
<ARGUMENT>: Argument(s) for respective command, same as in non-batch mode - When a command has no arguments (e.g.
lorem), an empty array must be given though (E.g.:{"lorem":[]}) - Arguments for markup-configuration of generic document elements can be given as nested JSON
Example: Replace string by heading-1 followed by table containing images
Templating sequence:
-
Step "1": Replace string
fooby heading-1 with the text:Foobar(followed by a temporary markermy-marker-1) -
Step "2": Replace the marker
my-marker-1by table containing 2x2 cells - Steps "3" to "6": Replace (the placeholder texts within the) table cells by images
- Add new image files into docx document
Batch config:
{
"1": {"rpt": [
"foo",
{
"h1": {
"text": "Foobar",
"post": {"text": "my-marker-1"}
}
}
]},
"2": {"rpt": [
"my-marker-1",
{
"table": {
"columns": 2,
"rows": 2,
"header": ["A","B"],
"content": [
["img-a1", "img-b1"],
["img-a2", "img-b2"]
]
}
}
]},
"3": {"rpt": [
"img-a1",
{
"img": {
"name": "blue.png",
"size": [2438400, 1828800]
}
}
]},
"4": {"rpt": [
"img-b1",
{
"img": {
"name": "green.png",
"size": [2438400, 1828800]
}
}
]},
"5": {
"rpt": [
"img-a2",
{
"img":{
"name": "orange.png",
"size": [2438400, 1828800]
}
}
]},
"6": {"rpt": [
"img-b2",
{
"img": {
"name": "red.png",
"size": [2438400,1828800]
}
}
]}
}
The full batch command:
Note: As when inserting new images in non-batch mode
(via rpt or rpi), also during batch
templating, image files to be added into the document must be given as trailing
arguments.
docxbox batch foo.docx "{\"1\":{\"rpt\":[\"foo\",{\"h1\":{\"text\":\"Foobar\",\"post\":{\"text\":\"my-marker-1\"}}}]},\"2\":{\"rpt\":[\"my-marker-1\",{\"table\":{\"columns\":2,\"rows\":2,\"header\":[\"A\",\"B\"],\"content\":[[\"img-a1\",\"img-b1\"],[\"img-a2\",\"img-b2\"]]}}]},\"3\":{\"rpt\":[\"img-a1\",{\"img\":{\"name\":\"blue.png\",\"size\":[2438400,1828800]}}]},\"4\":{\"rpt\":[\"img-b1\",{\"img\":{\"name\":\"green.png\",\"size\":[2438400,1828800]}}]},\"5\":{\"rpt\":[\"img-a2\",{\"img\":{\"name\":\"orange.png\",\"size\":[2438400,1828800]}}]},\"6\":{\"rpt\":[\"img-b2\",{\"img\":{\"name\":\"red.png\",\"size\":[2438400,1828800]}}]}}" blue.png green.png orange.png red.png
Save batch processed document to new file
To save the resulting document of batch processed manipulations to a new file, instead of overwriting the source document, the destination filename can optionally be given as the very last argument (also trailing other optional arguments like image files):
docxbox batch foo.docx "{\"1\":{\"mm\":[\"description\",\"foo\"]},\"2\":{\"rpt\":[\"bar\",\"baz\"]},\"3\":{\"rpt\":[\"qux\",{\"h1\":{\"text\":\"Quux\"}}]}}" new.docx
Arbitrary manual and scripted analysis / modification
docxBox eases conducting arbitrary modifications on files contained within a
DOCX, manually and scripted.
All steps besides the actual modification are automated via docxBox, with the
respective user-defined modification inserted.
Example - Edit XML file manually:
docxbox cmd foo.docx "nano *DOCX*/word/document.xml"
docxBox in the above example does:
-
Unzip
foo.docx - Indent all extracted XML files
- Render (= replace
*DOCX*w/ the resp. extraction path)
and execute the command:nano *DOCX*/word/document.xml, thereby openingdocument.xmlfor editing in nano, halting docxBox until exiting the editor. - Unindent all extracted XML files
-
Zip the extracted files back into
foo.docx
Output docxBox help or version number
docxbox
or docxbox h
Outputs docxBox's help text.
docxbox h <command> Outputs more help on a given command.
docxbox v Outputs the installed docxBox's version number.
Configuration
docxBox can optionally be configured using the following environment variables:
| Option | Possible Values | Default |
|---|---|---|
docxBox_notify |
stdout = Output notifications to stdout only |
stdout |
log = Log all notifications to file only |
||
both = Output notifications to stdout and log file |
||
off = Do not output any notifications |
||
docxBox_log_path |
empty = out.log is written to out.log in current working directory |
empty |
arbitary_path/filename.out = log file is written to given path |
||
docxBox_clear_log_on_start |
0 = docxBox appends notifications to logfile |
0 |
1 = docxBox resets the logfile on startup |
||
docxBox_verbose |
0 = Only most relevant notifications, if not disabled, are output to stdout |
0 |
1 = If enabled, all modification notifications are output to stdout |
Example:
Export variable to the environment docxBox runs in: export docxBox_verbose=1
Build Instructions
cmake CMakeLists.txt; make
Running tests
In order to run functional tests, Bats must be installed.
Run all tests: ./test.sh
Run specific test suite:
./test.sh <suite>
E.g.: ./test.sh ls - Filenames in test/functional/ correspond to test suite names.
Check all tests for memory-leaks via Valgrind:
./test.sh valgrind
In order to check for memory-leaks, Valgrind must be
installed on your computer.
Code Convention
The source code of docxBox follows the
Google C++ Style Guide.
The source code of functional tests follows the
Google Shell Style Guide
Changelog
See Changelog
Roadmap
- v1.0.0: Ensure all templating options work and output is microsoft word compatible
- v1.0.0: Add HTTP/s server mode (make usable as local web service)
- v1.1.0: Libre-Office compatible appending of two DOCX files into a single one (by XML appending, instead of adding sub-documents)
Bug Reporting and Feature Requests
If you find a bug or have an enhancement request, please file an issue on the github repository.
Third Party References
Microsoft Office and Word are registered trademarks of Microsoft Corporation.
docxBox was built using the following third party libraries and tools:
| Library | Description | License |
|---|---|---|
| nlohmann/json | JSON for Modern C++ | MIT License |
| tfussel/miniz-cpp | Cross-platform header-only C++14 library for reading and writing ZIP files | MIT License |
| leethomason/tinyxml2 | A simple, small, efficient, C++ XML parser | zlib License |
| Tool | Description | License |
|---|---|---|
| Bats | Bash Automated Testing System | MIT License |
| Clang | A C language family frontend for LLVM | Apache License |
| Cmake | Family of tools designed to build, test and package software | New BSD License |
| Cppcheck | Static analysis tool for C/C++ code | GNU General Public License version 3 |
| cpplint | Static code checker for C++ | BSD-3 Clause |
| GCC | GCC, the GNU Compiler Collection | GNU General Public License version 3 |
| Travis CI | Hosted Continuous Integration Service | MIT License |
| Valgrind | System for debugging and profiling Linux programs | GNU General Public License, version 2 |
Thanks a lot!
License
docxBox is licensed under The MIT License (MIT)