gpdb
 gpdb copied to clipboard
gpdb copied to clipboard
Real-time data warehouse
Real-time data processing can be realized only through SQL. When the source table changes, the result table automatically changes.
Please can you provide more color to the feature being requested. Currently provided text isn't helpful to get idea of what's being asked for.
Please can you provide more color to the feature being requested. Currently provided text isn't helpful to get idea of what's being asked for.
@ashwinstar Do you mean labels? I can't add tags.
Do you mean labels? I can't add tags.
The Github Issue description is not clear enough on the feature request. Are you asking for data streaming support? Are you asking for logical replication? Some more details would be helpful.
Maybe this article might be useful: https://docs.vmware.com/en/VMware-Tanzu-Greenplum-Streaming-Server/1.8/greenplum-streaming-server/GUID-overview.html
@jimmyyih Oh, sorry, I didn't make myself clear.
The data warehouse is built hierarchically. Suppose I have four layers: ODS, DWD, DWS, and ADS. These four layers are all in Greenplum. I use SQL to process data and use scheduling tools to schedule SQL regularly, but this will lead to delay.It is hoped that Greenplum can realize real-time data processing triggered by events. When my source table data changes (create, delete, update, truncate...), my result table data can automatically change. In other words, I no longer need to use Flink or Spark Streaming to achieve real-time data processing. Greenplum can help me solve this problem. I just need to write some special SQL (such as a real-time materialized view).
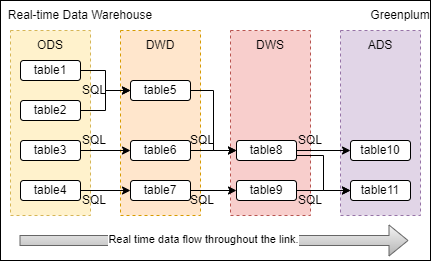 Not only does data flow into Greenplum in real time, but data processing in Greenplum is also in real time.
Not only does data flow into Greenplum in real time, but data processing in Greenplum is also in real time.
When my source table data changes (create, delete, update, truncate...), my result table data can automatically change.
So adding full trigger support in Greenplum help to accomplish the desired end goal?
I'm not sure, I hope the effect is similar to the continuous aggregation function provided by timescaledb, but it can support more SQL syntax. Refer to https://docs.timescale.com/getting-started/latest/aggregation/