gpdb
 gpdb copied to clipboard
gpdb copied to clipboard
[7X] pg_resgroup_move_query() improvements.
The pg_resgroup_move_query() function implemented in 51ee26b has several disadvantages:
- Slot leaking. The slot acquired in initiator process doesn't free if target process isn't alive, didn't receive a signal, or even received, but at the time it was in idle state.
- Race condition between UnassignResGroup() called at the end of transaction (or honestly not only UnassignResGroup(), but any other code) and handler called immediately after USR1 signal.
- Not working entrydb process moving. Previously, the USR1 signal was sent to only one process, target or entrydb. Entrydb moving was never tested properly.
Improvements added to solve the first problem:
- Feedback from target process to initiator. Target process can set initiator's latch to quickly interrupt pg_resgroup_move_query() from awaiting.
- Existed movetoResSlot parameter acts like a mark. Initiator sets it and waits on latch. If movetoResSlot become NULL, slot control is on the target process side.
- Initiator PID. Used by target process to get initiator's latch.
- Mutex. To guard all critical moveto* parameters from parallel changes.
To solve the second problem, there was an attempt to use Postgres interruptions. I was unhappy to know GPDB use raw InterruptPending value to do some pre-cancellation of dispatched queries. GPDB thinks InterruptPending can be triggered only by "negative" events, which leads to cancellation. The temporary solution with InterruptPending-like "positive" flag showed that we may wait for next CHECK_FOR_INTERRUPTS() call for a long. For example, some fat insert may do group moving only at the end of dispatching, which makes no sense. Thus, decreasing the probability of races is done now by additional IsTransactionState() check.
IMPORTANT NOTICE. The existed solution still affected by race conditions. The current handler's implementation is an example of bad design and should be reworked (moved to CHECK_FOR_INTERRUPTS()). (This part is related to this. We decided to do a separate patch later - current PR is already big and fixes a problem in most cases.)
To solve the third problem, now we send signals to target and entrydb processes separately. We do UnassignResGroup() for one process only, not cleaning all counters for still working entrydb process inside handler. More, entrydb moving logic is now separated from segments moving, and so, it became more readable.
New GUC (gp_resource_group_move_timeout) was added to limit a time we're waiting for feedback from target.
New regression tests shows there is no slot leaking with some rare and now correctly resolved cases.
The patch was originally made for 6X, but let's start from 7X. The first commit is a port of commit from 6X which missed in 7X.
I know it may be hard to review such big PR for such unpopular feature, but I think it's important to do it. We have a feature that's in production for a long, but which may cause a lot of random bugs and which not works properly in various cases.
Hello, @yaowangm! Could you pls guide us on possible review activities? We badly need this patch for our customers, so we want to plan our activities based on your plans.
@ivannovick @ivanievlev Sorry I was busy on other Jiras. I will focus on the PR as top priority from now.
Thanks for review. For some reason I can't answer to some questions directly in their threads. More, I've figured out, some of my answers to such questions were no applied from 'Files changed' tab.
At first, yes, I was wrong and mixed up the story around master, coordinator and dispatcher.
At second, we don't need to distinguish entrydb on segment. We can send a signal to entrydb from QD only which is filtered by Gp_role == GP_ROLE_DISPATCH part of condition.
@yaowangm Thanks for review. I've resolved all conflicts and squashed last commits. I left two commits, because we think they shouldn't be mixed.
UPD. Here is the same for 6X.
@InnerLife0 Thanks for your work. I have no more comments. Could you please:
- Add hard line wraps to PR description to make it clear on command line env.
- Run the tests like this on both GPDB6 and GPDB7 version and let me know the result:
cd src/test/regress
make installcheck
cd src/test/isolation2
make installcheck
Thanks!
@InnerLife0 Thanks for your work. I have no more comments. Could you please:
- Add hard line wraps to PR description to make it clear on command line env.
- Run the tests like this on both GPDB6 and GPDB7 version and let me know the result:
cd src/test/regress
make installcheck
cd src/test/isolation2
make installcheck
Thanks!
- Run the tests like this on both GPDB6 and GPDB7 version and let me know the result:
cd src/test/regress make installcheck cd src/test/isolation2 make installcheck
@yaowangm Sorry, but do you mean they may differ from the ones from your CI, or you've already seen something strange in CI and want to check?
- Run the tests like this on both GPDB6 and GPDB7 version and let me know the result:
cd src/test/regress make installcheck cd src/test/isolation2 make installcheck@yaowangm Sorry, but do you mean they may differ from the ones from your CI, or you've already seen something strange in CI and want to check?
No, it's just part of the process to make ensure the code is safe. I have not run on my CI.
After a discussion inside GPDB team, we decided to ask @SmartKeyerror to have a look to ensure the code reviewed by another eye. Once he provided approval, I will merge it.
No, it's just part of the process to make ensure the code is safe. I have not run on my CI.
I mean you already have automatically started CI here (which output I can't see though), but you need a copy of test results from me for a reason. Your CI seems to have ended successfully. Or do you mean it not contains tests results?
No, it's just part of the process to make ensure the code is safe. I have not run on my CI.
I mean you already have automatically started CI here (which output I can't see though), but you need a copy of test results from me for a reason. Your CI seems to have ended successfully. Or do you mean it not contains tests results?
The automatically started CI covers just a small portion of pipeline. Usually we ask for a full dev pipeline which is run manually.
The automatically started CI covers just a small portion of pipeline. Usually we ask for a full dev pipeline which is run manually.
Sorry, but this is something new to me. I mean your team have never asked before for additional manual test results (and hard line wraps in PR description, but this is another question). Is something changed not so long ago? Anyway, why we cover only small portion of pipeline? Manual run of all tests (in case we have an ability to run them all automatically) is not handy at all. And, well, it means you believe my results are right and not check them by yourself.
It's not a problem of "not check them by yourself". The process is we usually ask for a manual full dev pipeline for each PR. For the PRs from community, GPDB team can run the pipeline instead of owner. For the PR, @SmartKeyerror or myself will run pipeline and raise any problem to you. In the meantime, it's better to you to run the pipepline locally to find problem early. If it's not feasible for you, that's OK. You can wait for result from our side.
Sorry, my fault: I was not aware that the automatically CI has included the tests I mentioned. We (GPDB team) still need to manually run some extra tests, and you can just wait for the result.
@InnerLife0 Hi~ Before I start to review this PR, I run a simple isolation2 test, and find there has many failed tests, doesn't look like a flaky case (means your changes have some problems to those tests, need to figure out what cases failure and fix them).
You can use the below command to run local resource group isolation2 tests individually:
cd src/test/isolation2
make install
./pg_isolation2_regress --init-file=../regress/init_file --init-file=init_file_isolation2 --load-extension=gp_inject_fault --schedule=isolation2_resgroup_schedule
Those test cases need to be triaged:
test resgroup/resgroup_move_query ... FAILED 35502 ms (diff 198 ms)
test resgroup/resgroup_operator_memory ... FAILED 2116 ms (diff 150 ms)
test resgroup/resgroup_dumpinfo ... FAILED 1000 ms (diff 118 ms)
test resgroup/disable_resgroup ... FAILED 7116 ms (diff 112 ms)
The difference between actual results and expected results:
======================================================================
DIFF FILE: src/test/isolation2/regression.diffs
----------------------------------------------------------------------
+ cat src/test/isolation2/regression.diffs
diff -I HINT: -I CONTEXT: -I GP_IGNORE: -U3 /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_move_query.out /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_move_query.out
--- /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_move_query.out 2022-05-20 07:48:52.921123478 +0000
+++ /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_move_query.out 2022-05-20 07:48:52.944125880 +0000
@@ -387,44 +387,29 @@
Success:
(1 row)
1<: <... completed>
- gpname | numsegments | dbid | content | pg_sleep
------------+-------------+------+---------+----------
- Greenplum | -1 | -1 | -1 |
-(1 row)
+FATAL: Unexpected internal error (assert.c:48)
+DETAIL: AssertImply failed("!(!(!(Gp_role == GP_ROLE_EXECUTE && (GpIdentity.segindex == (-1)))) || (MySessionState->resGroupSlot == ((void *)0)))", File: "resgroup.c", Line: 3949)
+server closed the connection unexpectedly
+ This probably means the server terminated abnormally
+ before or while processing the request.
--is_session_in_group works only if all backends moved to group, so it will show 'f', but gp_resgroup_status will show actual result
2: SELECT is_session_in_group(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND state = 'idle in transaction';
- is_session_in_group
----------------------
- f
-(1 row)
+server closed the connection unexpectedly
+ This probably means the server terminated abnormally
+ before or while processing the request.
2: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query';
- num_running
--------------
- 1
-(1 row)
+unknown encoding:
--if there any next command called in the same transaction, segments will try to fix the situation and move out of inconsistent state
1: SELECT * FROM gp_dist_random('gp_id'), pg_sleep(1) LIMIT 1;
- gpname | numsegments | dbid | content | pg_sleep
------------+-------------+------+---------+----------
- Greenplum | -1 | -1 | -1 |
-(1 row)
+unknown encoding:
2: SELECT is_session_in_group(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND state = 'idle in transaction';
- is_session_in_group
----------------------
- t
-(1 row)
+unknown encoding:
2: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query';
- num_running
--------------
- 1
-(1 row)
+unknown encoding:
1: END;
-END
+unknown encoding:
2: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query';
- num_running
--------------
- 0
-(1 row)
+unknown encoding:
1q: ... <quitting>
-- test11: check destination group has no slot leaking if target process set latch at the last moment
@@ -461,69 +446,43 @@
BEGIN
1&: SELECT pg_sleep(3) FROM gp_dist_random('gp_id'); <waiting ...>
2: SELECT gp_inject_fault('resource_group_give_away_after_latch', 'reset', dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_inject_fault
------------------
- Success:
-(1 row)
+unknown encoding:
2: SELECT gp_inject_fault('resource_group_give_away_after_latch', 'suspend', dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_inject_fault
------------------
- Success:
-(1 row)
+unknown encoding:
2: SET gp_resource_group_move_timeout = 1000;
-SET
+unknown encoding:
2&: SELECT gp_toolkit.pg_resgroup_move_query(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND rsgname='rg_move_query_mem_small'; <waiting ...>
+FAILED: Forked command is not blocking; got output: unknown encoding:
3: SELECT gp_wait_until_triggered_fault('resource_group_give_away_after_latch', 1, dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_wait_until_triggered_fault
--------------------------------
- Success:
-(1 row)
+server closed the connection unexpectedly
+ This probably means the server terminated abnormally
+ before or while processing the request.
3: SELECT gp_inject_fault('resource_group_move_handler_before_qd_control', 'resume', dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_inject_fault
------------------
- Success:
-(1 row)
+server closed the connection unexpectedly
+ This probably means the server terminated abnormally
+ before or while processing the request.
3: SELECT gp_wait_until_triggered_fault('resource_group_move_handler_after_qd_control', 1, dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_wait_until_triggered_fault
--------------------------------
- Success:
-(1 row)
+unknown encoding:
3: SELECT gp_inject_fault('resource_group_move_handler_after_qd_control', 'resume', dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_inject_fault
------------------
- Success:
-(1 row)
+unknown encoding:
3: SELECT gp_inject_fault('resource_group_give_away_after_latch', 'resume', dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_inject_fault
------------------
- Success:
-(1 row)
+unknown encoding:
1<: <... completed>
pg_sleep
----------
-
-(3 rows)
+(2 rows)
2<: <... completed>
- pg_resgroup_move_query
-------------------------
- t
-(1 row)
+FAILED: Execution failed
2: RESET gp_resource_group_move_timeout;
-RESET
+unknown encoding:
3: SELECT is_session_in_group(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND state = 'idle in transaction';
- is_session_in_group
----------------------
- t
-(1 row)
+unknown encoding:
1: END;
END
3: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query';
- num_running
--------------
- 0
-(1 row)
+unknown encoding:
1q: ... <quitting>
-- test12: check destination group has no slot leaking if taget process recieved one move command at the time of processing another
@@ -549,47 +508,29 @@
BEGIN
1&: SELECT pg_sleep(5) FROM gp_dist_random('gp_id'); <waiting ...>
2&: SELECT gp_toolkit.pg_resgroup_move_query(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND rsgname='rg_move_query_mem_small'; <waiting ...>
+FAILED: Forked command is not blocking; got output: unknown encoding:
3: SELECT gp_wait_until_triggered_fault('resource_group_move_handler_before_qd_control', 1, dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_wait_until_triggered_fault
--------------------------------
- Success:
-(1 row)
+unknown encoding:
3: SELECT gp_toolkit.pg_resgroup_move_query(pid, 'default_group') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND rsgname='rg_move_query_mem_small';
-ERROR: cannot send signal to process
+unknown encoding:
3: SELECT gp_inject_fault('resource_group_move_handler_before_qd_control', 'resume', dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_inject_fault
------------------
- Success:
-(1 row)
+unknown encoding:
1<: <... completed>
pg_sleep
----------
-
-(3 rows)
+(2 rows)
2<: <... completed>
- pg_resgroup_move_query
-------------------------
- t
-(1 row)
+FAILED: Execution failed
3: SELECT is_session_in_group(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND state = 'idle in transaction';
- is_session_in_group
----------------------
- t
-(1 row)
+unknown encoding:
1: END;
END
3: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query';
- num_running
--------------
- 0
-(1 row)
+unknown encoding:
3: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='default_group';
- num_running
--------------
- 0
-(1 row)
+unknown encoding:
1q: ... <quitting>
-- Test13: check we'll wait and quit by gp_resource_group_move_timeout if target process stuck on signal handling
@@ -609,26 +550,20 @@
BEGIN
1&: SELECT pg_sleep(3); <waiting ...>
2: SET gp_resource_group_move_timeout = 3000;
-SET
+unknown encoding:
2: SELECT gp_toolkit.pg_resgroup_move_query(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND rsgname='rg_move_query_mem_small';
-ERROR: target process failed to move to a new group
+unknown encoding:
2: SELECT gp_inject_fault('resource_group_move_handler_before_qd_control', 'resume', dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_inject_fault
------------------
- Success:
-(1 row)
+unknown encoding:
2: RESET gp_resource_group_move_timeout;
-RESET
+unknown encoding:
1<: <... completed>
pg_sleep
----------
(1 row)
2: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query';
- num_running
--------------
- 0
-(1 row)
+unknown encoding:
1: END;
END
@@ -649,28 +584,26 @@
(1 row)
1&: SELECT * FROM gp_dist_random('gp_id'), pg_sleep(3) LIMIT 1; <waiting ...>
2: SELECT gp_toolkit.pg_resgroup_move_query(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND rsgname='rg_move_query_mem_small';
- pg_resgroup_move_query
-------------------------
- t
-(1 row)
+unknown encoding:
1<: <... completed>
gpname | numsegments | dbid | content | pg_sleep
-----------+-------------+------+---------+----------
Greenplum | -1 | -1 | -1 |
(1 row)
2: SELECT is_session_in_group(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND state = 'idle in transaction';
- is_session_in_group
----------------------
- t
-(1 row)
+unknown encoding:
1: END;
END
DROP ROLE role_move_query;
-DROP
+server closed the connection unexpectedly
+ This probably means the server terminated abnormally
+ before or while processing the request.
DROP RESOURCE GROUP rg_move_query;
-DROP
+server closed the connection unexpectedly
+ This probably means the server terminated abnormally
+ before or while processing the request.
DROP ROLE role_move_query_mem_small;
-DROP
+unknown encoding:
DROP RESOURCE GROUP rg_move_query_mem_small;
-DROP
+unknown encoding:
diff -I HINT: -I CONTEXT: -I GP_IGNORE: -U3 /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_operator_memory.out /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_operator_memory.out
--- /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_operator_memory.out 2022-05-20 07:48:55.588401985 +0000
+++ /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_operator_memory.out 2022-05-20 07:48:55.599403134 +0000
@@ -92,7 +97,7 @@
-- rg1 has no group level shared memory, and most memory are granted to rg2,
-- there is only very little global shared memory due to integer rounding.
CREATE RESOURCE GROUP rg2_opmem_test WITH (cpu_rate_limit=10, memory_limit=59);
-CREATE
+ERROR: total memory_limit exceeded the limit of 100
-- this query can execute but will raise OOM error.
@@ -101,8 +106,9 @@
SET ROLE TO r1_opmem_test;
SET
SELECT * FROM many_ops;
-DETAIL: Resource group memory limit reached
-ERROR: Out of memory
+ groupid | groupname | concurrency | cpu_rate_limit | memory_limit | memory_shared_quota | memory_spill_ratio | memory_auditor | cpuset
+---------+-----------+-------------+----------------+--------------+---------------------+--------------------+----------------+--------
+(0 rows)
RESET role;
RESET
@@ -111,8 +117,9 @@
SET ROLE TO r1_opmem_test;
SET
SELECT * FROM many_ops;
-DETAIL: Resource group memory limit reached
-ERROR: Out of memory
+ groupid | groupname | concurrency | cpu_rate_limit | memory_limit | memory_shared_quota | memory_spill_ratio | memory_auditor | cpuset
+---------+-----------+-------------+----------------+--------------+---------------------+--------------------+----------------+--------
+(0 rows)
RESET role;
RESET
@@ -121,8 +128,9 @@
SET ROLE TO r1_opmem_test;
SET
SELECT * FROM many_ops;
-DETAIL: Resource group memory limit reached
-ERROR: Out of memory
+ groupid | groupname | concurrency | cpu_rate_limit | memory_limit | memory_shared_quota | memory_spill_ratio | memory_auditor | cpuset
+---------+-----------+-------------+----------------+--------------+---------------------+--------------------+----------------+--------
+(0 rows)
RESET role;
RESET
@@ -131,7 +139,7 @@
--
ALTER RESOURCE GROUP rg2_opmem_test SET memory_limit 40;
-ALTER
+ERROR: resource group "rg2_opmem_test" does not exist
ALTER RESOURCE GROUP rg1_opmem_test SET memory_limit 20;
ALTER
ALTER RESOURCE GROUP rg1_opmem_test SET memory_shared_quota 100;
@@ -177,7 +185,7 @@
--
DROP RESOURCE GROUP rg2_opmem_test;
-DROP
+ERROR: resource group "rg2_opmem_test" does not exist
ALTER RESOURCE GROUP rg1_opmem_test SET memory_limit 40;
ALTER
ALTER RESOURCE GROUP rg1_opmem_test SET memory_shared_quota 50;
diff -I HINT: -I CONTEXT: -I GP_IGNORE: -U3 /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_dumpinfo.out /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_dumpinfo.out
--- /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_dumpinfo.out 2022-05-20 07:48:57.683620761 +0000
+++ /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_dumpinfo.out 2022-05-20 07:48:57.685620970 +0000
@@ -42,7 +42,7 @@
SELECT dump_test_check();
dump_test_check
-----------------
- t
+ f
(1 row)
2:END;
diff -I HINT: -I CONTEXT: -I GP_IGNORE: -U3 /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/disable_resgroup.out /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/disable_resgroup.out
--- /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/disable_resgroup.out 2022-05-20 07:49:05.566443857 +0000
+++ /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/disable_resgroup.out 2022-05-20 07:49:05.568444066 +0000
@@ -3,10 +3,14 @@
! ls -d /sys/fs/cgroup/cpu/gpdb/*/;
/sys/fs/cgroup/cpu/gpdb/6437/
/sys/fs/cgroup/cpu/gpdb/6438/
+/sys/fs/cgroup/cpu/gpdb/65571/
+/sys/fs/cgroup/cpu/gpdb/65573/
! ls -d /sys/fs/cgroup/cpuacct/gpdb/*/;
/sys/fs/cgroup/cpuacct/gpdb/6437/
/sys/fs/cgroup/cpuacct/gpdb/6438/
+/sys/fs/cgroup/cpuacct/gpdb/65571/
+/sys/fs/cgroup/cpuacct/gpdb/65573/
-- reset the GUC and restart cluster.
+ read diff
+ exit 2
@InnerLife0 Hi~ Before I start to review this PR, I run a simple isolation2 test, and find there has many failed tests, doesn't look like a flaky case (means your changes have some problems to those tests, need to figure out what cases failure and fix them).
Will take a look. Thanks.
Should be fixed. And yes, it was flaky.
The error was around the one new assertion from addressed PR comments. A lot of time has passed and I forgot why we can't have such assertion in sessionSetSlot(). Comment rearranged, assertion changed.
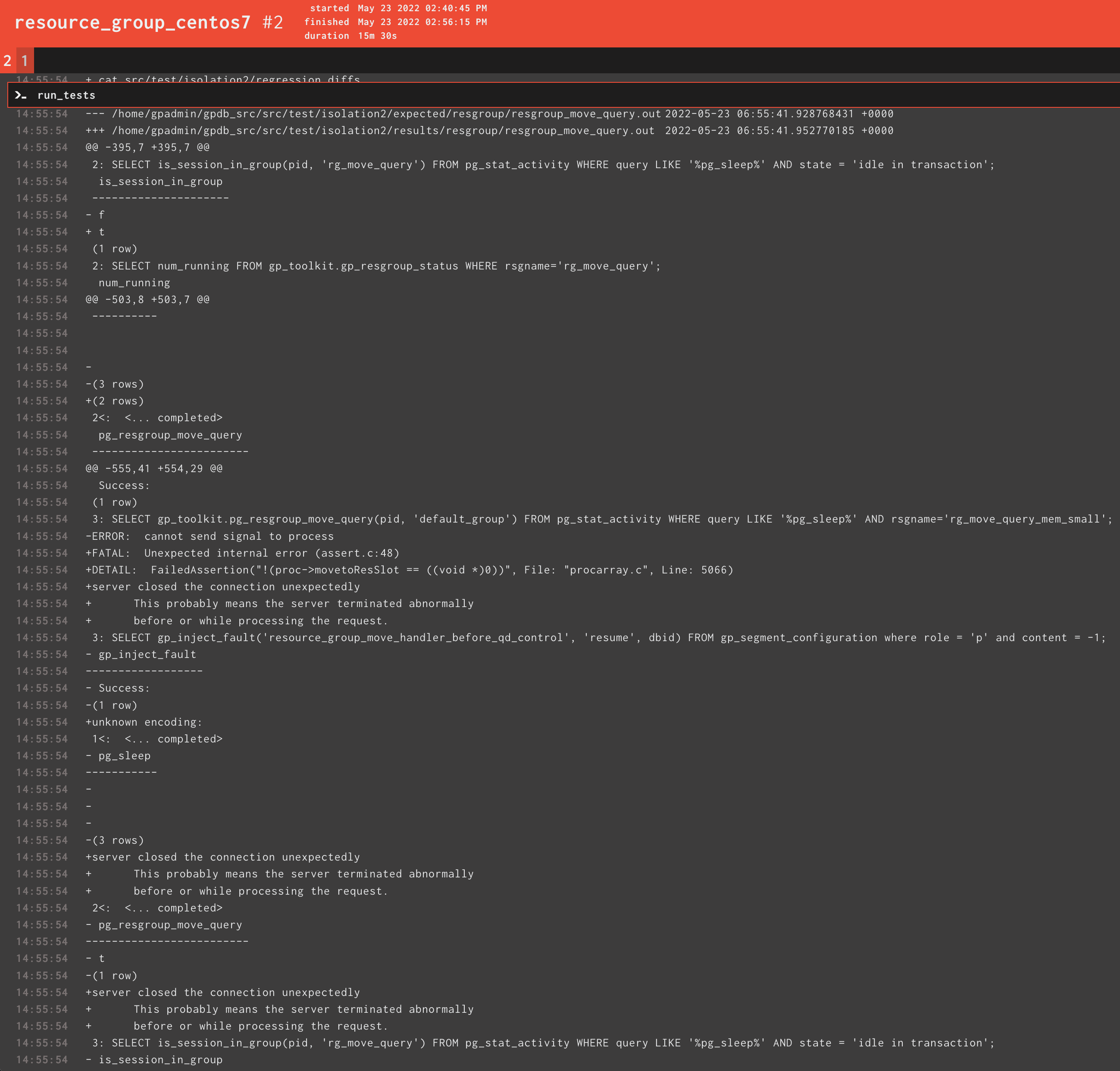
@InnerLife0 Hi, the latest commit still failed in the same cases.
SELECT is_session_in_group(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND state = 'idle in transaction';
is_session_in_group
---------------------
- f
+ t
The result of true is the expected result? If so, we should change the resgroup_move_query.out; if not, we should make it correct.
And the Assert failed again:
3: SELECT gp_toolkit.pg_resgroup_move_query(pid, 'default_group') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND rsgname='rg_move_query_mem_small';
-ERROR: cannot send signal to process
+FATAL: Unexpected internal error (assert.c:48)
+DETAIL: FailedAssertion("!(proc->movetoResSlot == ((void *)0))", File: "procarray.c", Line: 5066)
+server closed the connection unexpectedly
+ This probably means the server terminated abnormally
+ before or while processing the request.
And there has "unknown encoding"in the output, that's weird:
3: SELECT gp_inject_fault('resource_group_move_handler_before_qd_control', 'resume', dbid) FROM gp_segment_configuration where role = 'p' and content = -1;
- gp_inject_fault
------------------
- Success:
-(1 row)
+unknown encoding:
Besides, I found the error "+ERROR: total memory_limit exceeded the limit of 100" in resgroup_operator_memory.out, which should not happen.
The result of
trueis the expected result? If so, we should change theresgroup_move_query.out; if not, we should make it correct.
The expected result is false, which described in the comment. Now I try to find why this test is still flaky. I can't get true result here when running tests locally.
And the Assert failed again:
Damn. This is another assertion I've add from address PR comments. I see why it can shoot and will fix it.
+unknown encoding:
True. It's weird. Can't say much about this error. Probably, it's some strange artifact of failed tests.
Besides, I found the error "+ERROR: total memory_limit exceeded the limit of 100" in resgroup_operator_memory.out, which should not happen.
Yes, that could happen if some of tests failed.
@SmartKeyerror
I've fixed a bug with assertions, but I can't reproduce first bug around true/false result. More, I can't understand a part you didn't mention.
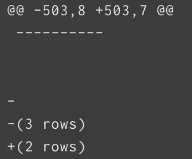
pg_sleep should return 3 rows on demo cluster, but successfully returns 2.
Can you please tell more about your test environment? Can you run tests again and attach server logs if any difference appeared?
Can you please tell more about your test environment?
I run it in our team's private pipeline, it's a little complicated, so I don't know the exact environment...
But the good news is that there is only one failed test case in your last commit:
======================================================================
DIFF FILE: src/test/isolation2/regression.diffs
----------------------------------------------------------------------
+ cat src/test/isolation2/regression.diffs
diff -I HINT: -I CONTEXT: -I GP_IGNORE: -U3 /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_move_query.out /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_move_query.out
--- /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_move_query.out 2022-05-30 09:05:51.488987447 +0000
+++ /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_move_query.out 2022-05-30 09:05:51.512989690 +0000
@@ -395,7 +395,7 @@
2: SELECT is_session_in_group(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND state = 'idle in transaction';
is_session_in_group
---------------------
- f
+ t
(1 row)
2: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query';
num_running
@@ -503,8 +503,7 @@
----------
-
-(3 rows)
+(2 rows)
2<: <... completed>
pg_resgroup_move_query
------------------------
@@ -566,8 +565,7 @@
----------
-
-(3 rows)
+(2 rows)
2<: <... completed>
pg_resgroup_move_query
------------------------
How can we explain that pg_sleep returns only 2 rows?
Is it possible to gather server logs to have a chance to debug true/false test?
We can't reproduce the bug running installcheck-resgroup on our developers machines.
How can we explain that
pg_sleepreturns only 2 rows? Is it possible to gather server logs to have a chance to debugtrue/falsetest? We can't reproduce the bug runninginstallcheck-resgroupon our developers machines.
That's a little strange, this case will pass in my local environment using the below command:
./pg_isolation2_regress --init-file=../regress/init_file --init-file=init_file_isolation2 --load-extension=gp_inject_fault resgroup/resgroup_move_query
But failed in the pipeline, I'll investigate it tomorrow.
But failed in the pipeline, I'll investigate it tomorrow.
@SmartKeyerror Hi! Is there any news?
@InnerLife0 Sorry for the late response, after I changed the number of segment from 2 to 3 in test pipeline environment, the resgroup_move_query case still failed, failed at "test10: check destination group has no slot leaking if we got an error on latch waiting":
--- /home/gpadmin/gpdb_src/src/test/isolation2/expected/resgroup/resgroup_move_query.out 2022-06-21 03:17:40.197087007 +0000
+++ /home/gpadmin/gpdb_src/src/test/isolation2/results/resgroup/resgroup_move_query.out 2022-06-21 03:17:40.221089333 +0000
@@ -395,7 +395,7 @@
2: SELECT is_session_in_group(pid, 'rg_move_query') FROM pg_stat_activity WHERE query LIKE '%pg_sleep%' AND state = 'idle in transaction';
is_session_in_group
---------------------
- f
+ t
(1 row)
2: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query';
num_running
2: SELECT num_running FROM gp_toolkit.gp_resgroup_status WHERE rsgname='rg_move_query'; num_running @@ -503,8 +503,7 @@
-(3 rows) +(2 rows)
For the failure, my assumption is: in a corner case, the query to be moved didn't release slot correctly (might be caused by sort of race condition). num_running indicates group->nRunning which is modified in groupPutSlot():
1721 static void
1722 groupPutSlot(ResGroupData *group, ResGroupSlotData *slot)
1723 {
1724 int32 released;
1725
1726 Assert(LWLockHeldByMeInMode(ResGroupLock, LW_EXCLUSIVE));
1727 Assert(group->memQuotaUsed >= 0);
1728 Assert(slotIsInUse(slot));
1729
1730 /* Return the memory quota granted to this slot */
1731 groupReleaseMemQuota(group, slot);
1732
1733 /* Return the slot back to free list */
1734 slotpoolFreeSlot(slot);
1735 group->nRunning--;
Relevant code path:
ResGroupMoveQuery (or UnassignResGroup)
--groupReleaseSlot
----groupPutSlot
And the value of group->nRunning is fetched in ResGroupGetStat():
1032 case RES_GROUP_STAT_NRUNNING:
1033 result = Int32GetDatum(group->nRunning + group->nRunningBypassed);
1034 break;
A mystery is why we got an empty value here (may be a null) when getting an integer value. I have not found the root cause. Maybe we need to check the code related to concurrency protection.
For the failure, my assumption is: in a corner case, the query to be moved didn't release slot correctly (might be caused by sort of race condition).
num_runningindicatesgroup->nRunningwhich is modified ingroupPutSlot():
Sorry, but I can't understand what you mean. As I can see, we still don't have any error around num_running field. Your quote is related to sleep() output which was gathered from 2 segments and now should be fixed.
But we still have something around is_session_in_group() which returns true in your environment. Do we have any chance to debug this? Any server logs or something?
For the failure, my assumption is: in a corner case, the query to be moved didn't release slot correctly (might be caused by sort of race condition).
num_runningindicatesgroup->nRunningwhich is modified ingroupPutSlot():Sorry, but I can't understand what you mean. As I can see, we still don't have any error around
num_runningfield. Your quote is related tosleep()output which was gathered from 2 segments and now should be fixed.But we still have something around
is_session_in_group()which returns true in your environment. Do we have any chance to debug this? Any server logs or something?
Sorry please ignore my previous comments. When I wrote it I was not aware of the latest progress of Zhenglong tomorrow afternoon. It's due to different segments number between local/pipeline env and we have known the root cause.
resgroup_move_querycase still failed, failed at "test10: check destination group has no slot leaking if we got an error on latch waiting":
@SmartKeyerror We still don't know much about your testing environment, but we have an assumption. Is it possible you test resgroups not on the classic demo cluster deployed on the single host? This test may return true if you have segment hosts on the separate machines. If that's true, I'm curious to know what already existed Test7 is trying to check.