graphsignal-python
 graphsignal-python copied to clipboard
graphsignal-python copied to clipboard
Graphsignal Tracer for Python
Graphsignal: Inference Profiling And Monitoring



Graphsignal is a machine learning inference profiling and monitoring platform. It helps data scientists and ML engineers make model inference faster and more efficient. It is built for real-world use cases and allows ML practitioners to:
- Optimize and monitor inference by measuring latency and throughput, analyzing bottlenecks and resource utilization.
- Start profiling and monitoring jobs and server applications automatically by adding a few lines of code.
- Use Graphsignal in local, remote or cloud environment without installing any additional software or opening inbound ports.
- Keep data private; no code or data is sent to Graphsignal cloud, only statistics and metadata.
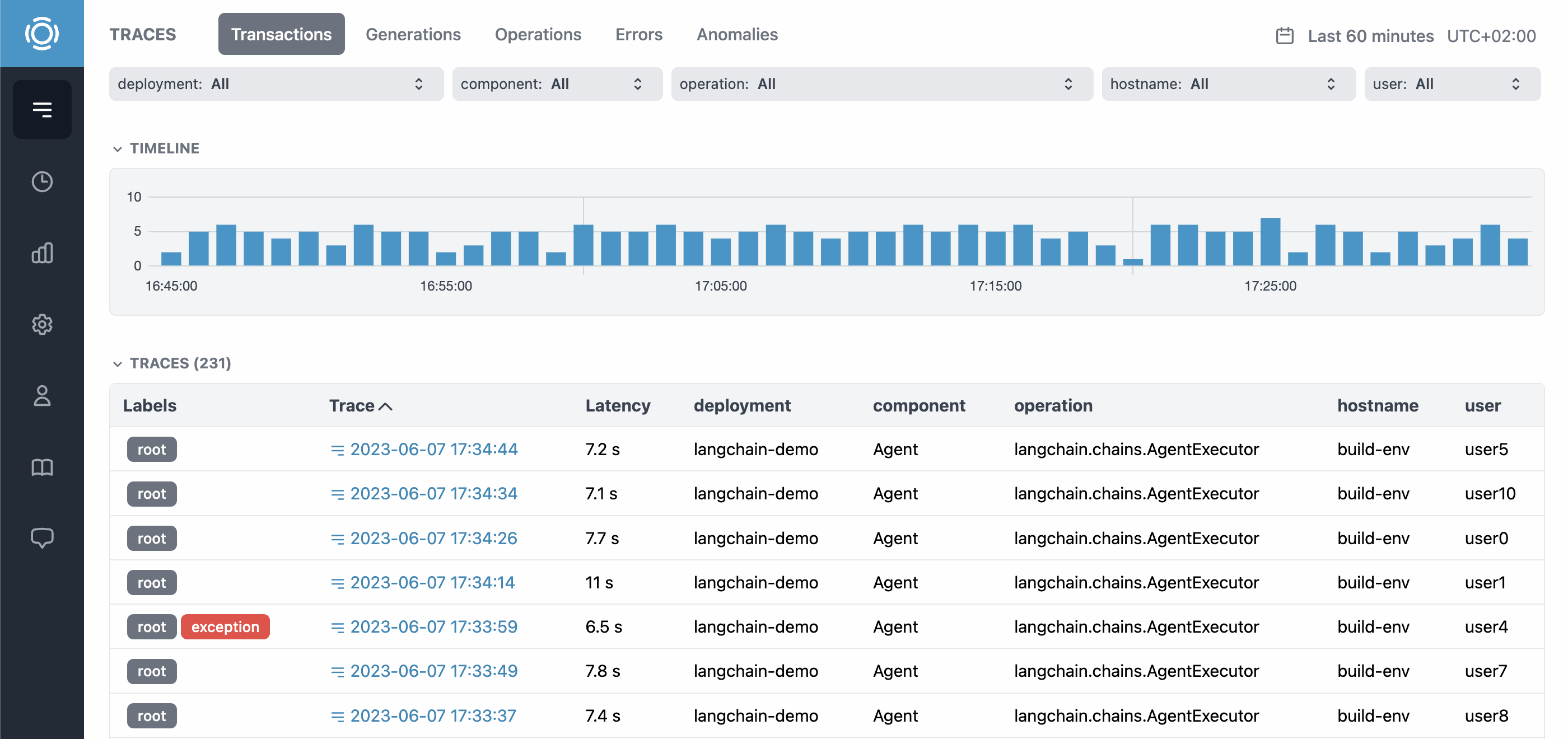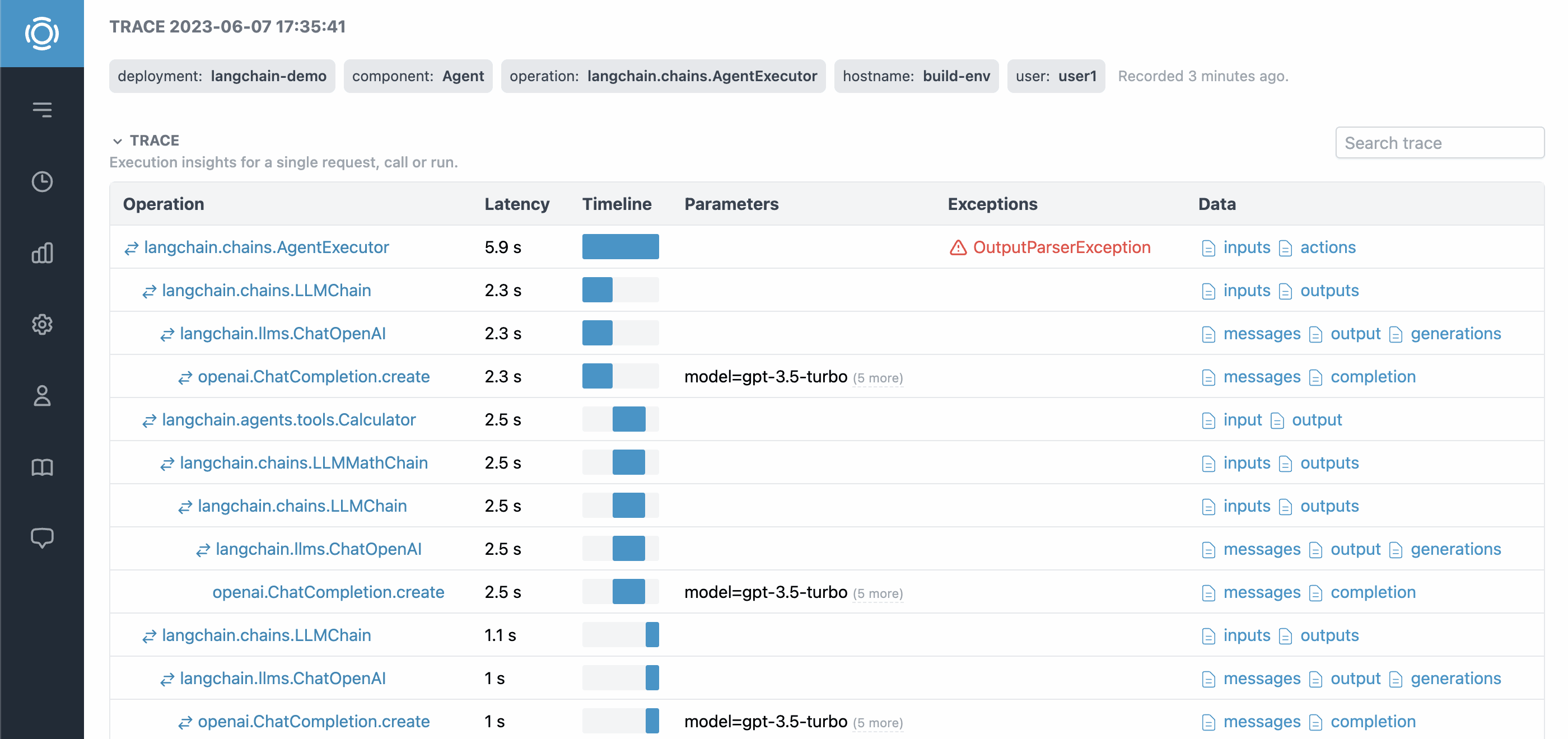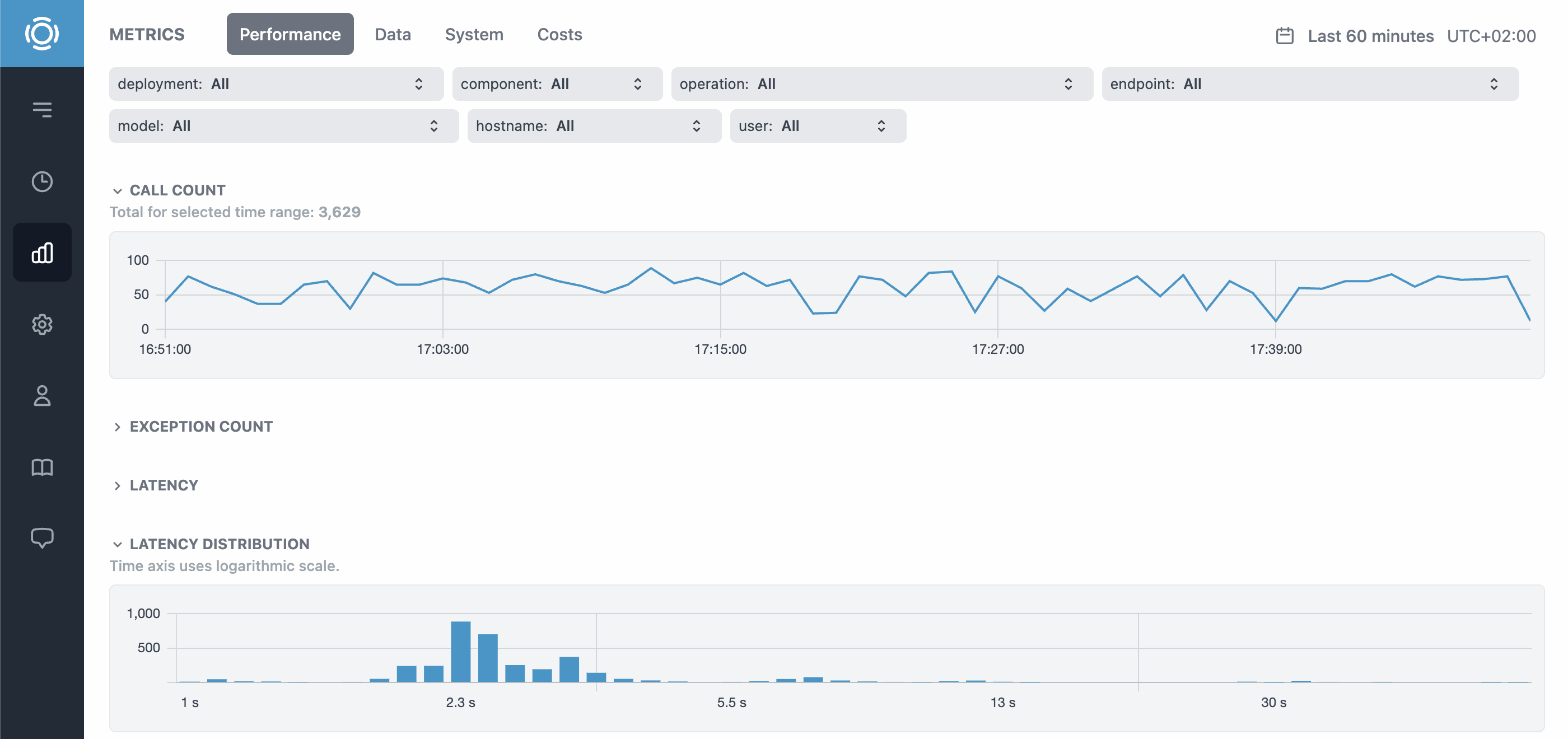
Learn more at graphsignal.com.
Documentation
See full documentation at graphsignal.com/docs.
Getting Started
1. Installation
Install Graphsignal agent by running:
pip install graphsignal
Or clone and install the GitHub repository:
git clone https://github.com/graphsignal/graphsignal.git
python setup.py install
2. Configuration
Configure Graphsignal agent by specifying your API key directly or via environment variable.
import graphsignal
graphsignal.configure(api_key='my-api-key')
To get an API key, sign up for a free account at graphsignal.com. The key can then be found in your account's Settings / API Keys page.
Provide a workload_name to track runs, deployments or applications separately.
graphsignal.configure(api_key='my-api-key', workload_name='model-serving-prod')
Integration
Use the following examples to integrate Graphsignal agent into your machine learning application. See integration documentation and API reference for full reference.
Graphsignal agent is optimized for production. All inferences wrapped with inference_span will be measured, but only a few will be profiled to ensure low overhead.
Python
from graphsignal.tracers.python import inference_span
with inference_span(model_name='my-model'):
# function call or code segment
TensorFlow
from graphsignal.tracers.tensorflow import inference_span
with inference_span(model_name='my-model'):
# function call or code segment
Keras
from graphsignal.tracers.keras import GraphsignalCallback
model.predict(..., callbacks=[GraphsignalCallback(model_name='my-model')])
# or model.evaluate(..., callbacks=[GraphsignalCallback(model_name='my-model')])
PyTorch
from graphsignal.tracers.pytorch import inference_span
with inference_span(model_name='my-model'):
# function call or code segment
PyTorch Lightning
from graphsignal.tracers.pytorch_lightning import GraphsignalCallback
trainer = Trainer(..., callbacks=[GraphsignalCallback(model_name='my-model')])
trainer.predict() # or trainer.validate() or trainer.test()
Hugging Face
from transformers import pipeline
from graphsignal.tracers.pytorch import inference_span
# or from graphsignal.tracers.tensorflow import inference_span
pipe = pipeline(task="text-generation")
with inference_span(model_name='my-model'):
output = pipe('some text')
JAX
from graphsignal.tracers.jax import inference_span
with inference_span(model_name='my-model'):
# function call or code segment
ONNX Runtime
import onnxruntime
from graphsignal.tracers.onnxruntime import initialize_profiler, inference_span
sess_options = onnxruntime.SessionOptions()
initialize_profiler(sess_options)
session = onnxruntime.InferenceSession('my-model-path', sess_options)
with inference_span(model_name='my-model', onnx_session=session):
session.run(...)
Measuring Rates
By using any inference_span method, multiple metrics are automatically measured and periodically reported, including inference performance, CPU, GPU and memory.
To measure additional rates, InferenceSpan.set_count(name, value) method can be used. For example, by providing the number of processed items on every inference, item rate per second will be automatically calculated.
with inference_span(model_name='text-classification') as span:
span.set_count('sentences', 5)
span.set_count('words', 250)
Reporting Exceptions
When with context manager is used with inference_span methods, exceptions are automatically reported. For other cases, use InferenceSpan.add_exception(exc_info) method.
span = inference_span(model_name='my-model'):
try:
preds = model(inputs)
except:
span.add_exception(exc_info=True)
span.stop()
3. Monitoring
After everything is setup, log in to Graphsignal to monitor and analyze inference performance.
Examples
Model serving
import graphsignal
from graphsignal.tracers.pytorch import inference_span
graphsignal.configure(
api_key='my-api-key', workload_name='my-model-serving')
...
def predict(x):
with inference_span(model_name='my-model'):
return model(x)
Batch job
import graphsignal
from graphsignal.tracers.pytorch import inference_span
graphsignal.configure(
api_key='my-api-key', workload_name='job-{0}'.format(datetime.date.today()))
....
for x in data:
with inference_span(model_name='my-model'):
preds = model(x)
More integration examples are available in examples repo.
Overhead
Although profiling may add some overhead to applications, Graphsignal only profiles certain inferences, automatically limiting the overhead.
Security and Privacy
Graphsignal Profiler can only open outbound connections to agent-api.graphsignal.com and send data, no inbound connections or commands are possible.
No code or data is sent to Graphsignal cloud, only statistics and metadata.
Troubleshooting
To enable debug logging, add debug_mode=True to configure(). If the debug log doesn't give you any hints on how to fix a problem, please report it to our support team via your account.
In case of connection issues, please make sure outgoing connections to https://agent-api.graphsignal.com are allowed.
For GPU profiling, if libcupti agent is failing to load, make sure the NVIDIA® CUDA® Profiling Tools Interface (CUPTI) is installed by running:
/sbin/ldconfig -p | grep libcupti