graph-node
 graph-node copied to clipboard
graph-node copied to clipboard
graphman doesnt work with full hash for deployment, but rather only name
Attempt with full hash of deployment:
pops@val01-grt-m:/home/pops/graph-node/target/debug$ ./graphman --config /home/pops/graphman.toml remove QmS5Pu88ZfZcFpTpbE2khnvdYVqdK9f41qxrwL4kw6rFG7
Removing subgraph QmS5Pu88ZfZcFpTpbE2khnvdYVqdK9f41qxrwL4kw6rFG7
pops@val01-grt-m:/home/pops/graph-node/target/debug$ ./graphman --config /home/pops/graphman.toml unused record
Recording unused deployments. This might take a while.
Recorded 0 unused deployments
Attempt with name of deployment:
pops@val01-grt-m:/home/pops/graph-node/target/debug$ ./graphman --config /home/pops/graphman.toml remove indexer-agent/wL4kw6rFG7
Removing subgraph indexer-agent/wL4kw6rFG7
pops@val01-grt-m:/home/pops/graph-node/target/debug$ ./graphman --config /home/pops/graphman.toml unused record Recording unused deployments. This might take a while.
id | 73
shard | primary
namespace | sgd73
subgraphs |
entities | 1438
Recorded 1 unused deployments
Ideally full hash of deployment should work.
Version is 20.3.
let me add here so i dont clutter, after i removed subgraphs i didnt need anymore, graphman must have done something as ive got new SGDs now in my db. For context my last sgd was 110, opened today for a new subgraph. Then i saw this in grafana and verified in db too:
SGDs 111 to 118 are all fake, or not made by me. This is quite alarming imo!
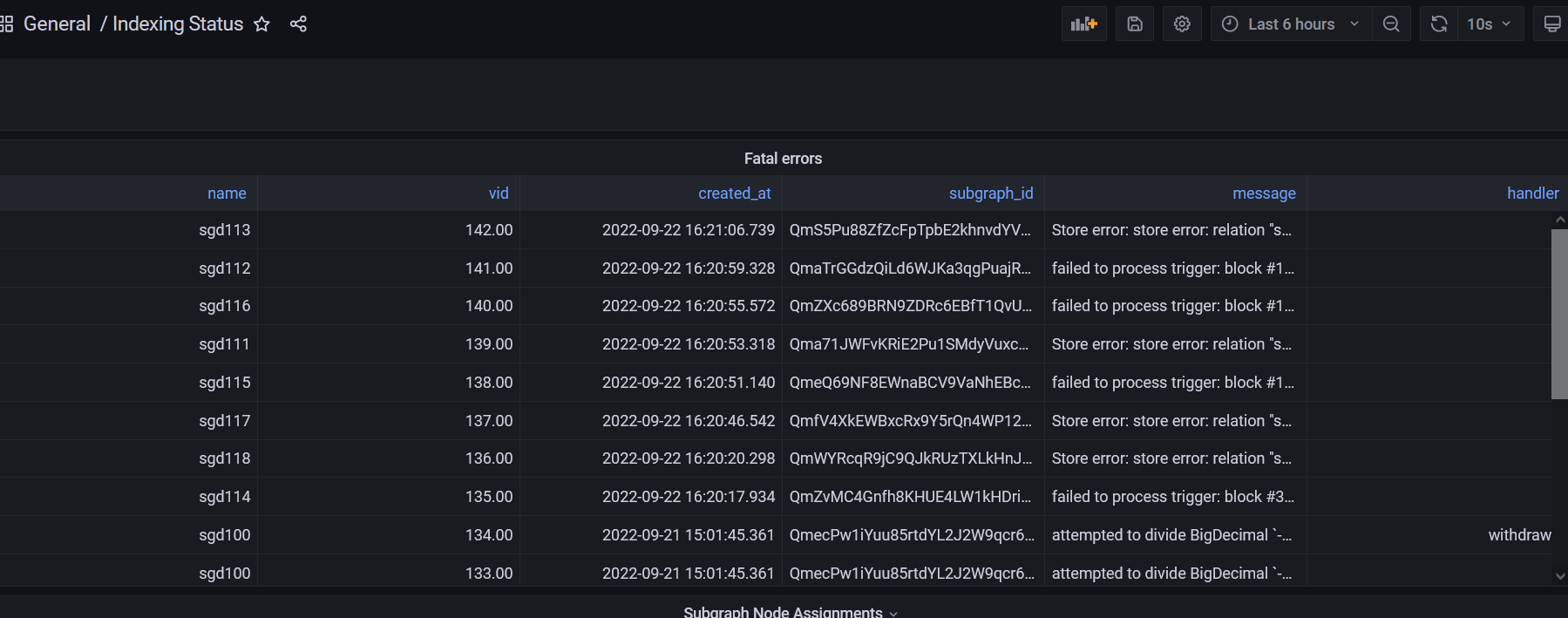
@azf20 @fordN lmk if you need any more info, tagged you on discord too but here might be easier
Hi @mindstyle85 I think in this case the indexer-agent is redeploying the subgraphs when it is started up, @fordN is there a recommended way to handle this? cc @lutter
Hi @mindstyle85 I think in this case the
indexer-agentis redeploying the subgraphs when it is started up, @fordN is there a recommended way to handle this? cc @lutter
This is not true, i checked the subgraphs it added back, and i didnt even add any of them myself (i have a separate list in google sheet on all subgraphs i ever started indexing etc). None of those 8 or 9 were in the list.
So to clarify:
- You stopped the indexer agent
- You ran
graphman --config graphman.toml remove indexer-agent/pkAyYrk93gthenunused recordand thenunused remove - You restarted the indexer agent
- And then there were 8-9 new subgraphs deployed which you never added, which all failed
On the subject of the original post, I think that is expected behaviour, as graphman remove is for removing subgraph names, rather than deployments (which might potentially point to multiple subgraph names, so could have unintended consequences), so I think that is the expected behaviour
But it seems you are also reporting this separate issue about the mystery new SGDs?
So to clarify:
- You stopped the indexer agent
- You ran
graphman --config graphman.toml remove indexer-agent/pkAyYrk93gthenunused recordand thenunused remove- You restarted the indexer agent
- And then there were 8-9 new subgraphs deployed which you never added, which all failed
On the subject of the original post, I think that is expected behaviour, as
graphman removeis for removing subgraph names, rather than deployments (which might potentially point to multiple subgraph names, so could have unintended consequences), so I think that is the expected behaviourBut it seems you are also reporting this separate issue about the mystery new SGDs?
Correct on the first part.
For the expected behaviour part, others have reported that it used to work with just subgraph deployment and now its changed to name. I dont mind it, but decided to report since it seems it was possible to remove it by the full hash before.
Yes basically i reported two things here, and this second one (agent adding new subgraphs i never used before which took up new SGD IDs, while my last manual one was 110, i am now at 126 - because i used graphman twice, to remove the first batch of these odd deployments).
hey @azf20 i restarted the indexer stack today (graph node, indexer, agent) , and it seems actually that also causes those same subgraphs to come back again and they were actually syncing this time so i had to manually never them:
graph-indexer indexer rules set QmWYRcqR9jC9QJkRUzTXLkHnJxgaQiXPFHWdqXijZthifR parallelAllocations 0 decisionBasis never allocationAmount 0
graph-indexer indexer rules set QmZvMC4Gnfh8KHUE4LW1kHDri6EjsNmWYFXewqLLuZJdMS parallelAllocations 0 decisionBasis never allocationAmount 0
graph-indexer indexer rules set QmeQ69NF8EWnaBCV9VaNhEBcAtie82Px64qEF8MpPCiEGS parallelAllocations 0 decisionBasis never allocationAmount 0
graph-indexer indexer rules set QmZXc689BRN9ZDRc6EBfT1QvU9c56ewkiZJ9uXgvN8wd2X parallelAllocations 0 decisionBasis never allocationAmount 0
graph-indexer indexer rules set QmfV4XkEWBxcRx9Y5rQn4WP12XzMw5Dfi71eXPCmTwW8gu parallelAllocations 0 decisionBasis never allocationAmount 0
i also checked all this quickly on graphscan and none of them exist (at least not anymore)
now another report from mips participant about graphman issues (same error i see in some of those subgraphs that were added to our indexing without me actually having a rule set for them):
failed to process trigger: block #18416963 (0x9145…4743), transaction 0093a40f3c15fbcedf58066975a3a49ab13d4e6ef854d633f3f74198866d801b: Store error: store error: relation "sgd2.router" does not exist wasm backtrace: 0: 0x2195 - <unknown>!src/v1-runtime/mapping/handleLiquidityAdded
user quote:
It originally failed so I deleted it with graphman and restarted it using decisionBasis offchain via the CLI. I think the important bit is the sgd2.router part. If I understand correctly sgd2 is the namespace for a deployment? If so, the latest deployment for this subgraph is sgd9. Anyone have any idea where it is picking up the old sgd2 prefix from?
for the sake of us mainnet indexer it would be great if this graphman issue is fixed before it screws up too many of us and the only option left will be to start from scratch
Hey @mindstyle85, in the situation where you remove a subgraph, then find that it is redeployed I have a few questions:
- Is the indexer-agent redeploying it? You can check the logs to confirm.
- What version of indexer-agent are you running?
- Where you previously allocated to that subgraph? If so when did the allocation close? The indexer-agent attempts to keep a subgraph syncing for an epoch (day) after closing an allocation because the gateways don't have a hard cutoff of queries exactly when an allocation closes.
Hey @mindstyle85, in the situation where you remove a subgraph, then find that it is redeployed I have a few questions:
- Is the indexer-agent redeploying it? You can check the logs to confirm.
- What version of indexer-agent are you running?
- Where you previously allocated to that subgraph? If so when did the allocation close? The indexer-agent attempts to keep a subgraph syncing for an epoch (day) after closing an allocation because the gateways don't have a hard cutoff of queries exactly when an allocation closes.
hey @fordN, the subgraph isnt really redeployed because its a subgraph i never even used and 100% didnt set a rule at any point either:
- will need to check the logs, unfortunately theyre buried now as its been a while (do you have a specific string i can grep to find it faster?)
- 20.3
- No i wasnt and i didnt even have any rule for any of those i screenshotted above (i run an offline list of all subgraphs im using so im 100% sure here). Not even offchain sync
Ok, so the behavior you observed is that a subgraph deployment began syncing even though there is no corresponding rule for that subgraph? Is there also an allocation being created? I'd grep the logs for the deployment ID of the subgraphs you weren't expecting to be deployed. I'd also look in the actions queue for a corresponding action which will tell you information on why the agent identified that action to be taken and which rule it matched with.
Ok, so the behavior you observed is that a subgraph deployment began syncing even though there is no corresponding rule for that subgraph? Is there also an allocation being created?
yes on first and no on second
I grepped the logs and there was nothing found, i went even 30 days back, nothing seen on the action queue either.
there is something else strange though, all those fake subgraphs disappeared now from grafana (see my screenshot in 2nd post in this issue vs the one here below). Now im thinking thats maybe just an UI issue after graph agent restart? Because what i suspect is that once i restarted my whole stack (node and service too), those dissappeared from grafana. The SGDs though still suggest that those are somewhere in the database (i should be at around 115 maximum at the moment).
this is a super weird issue.. Could you let me know how i can find a specific SGD in the db with graphman? i want to check that too since i cant see them in grafana anymore
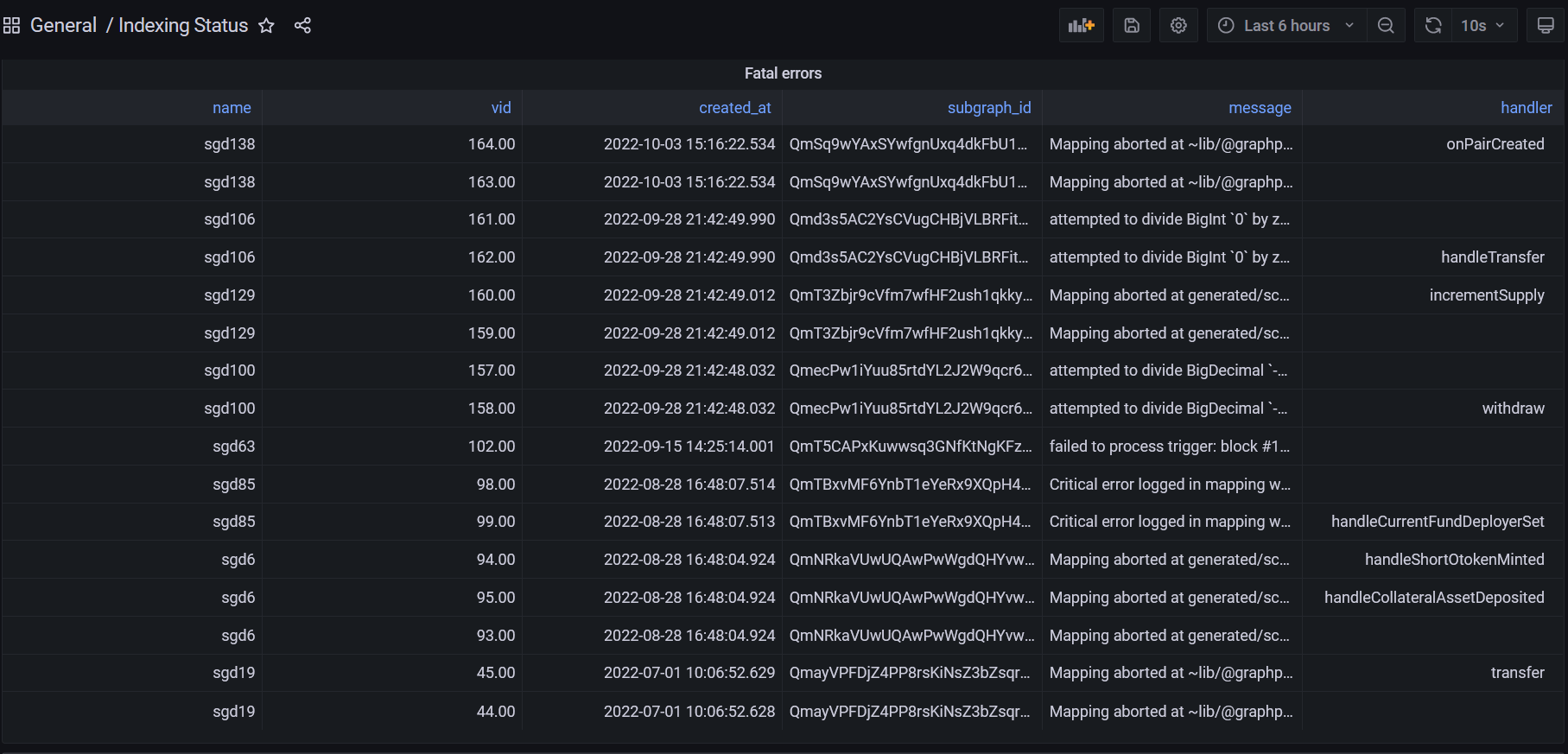
now another report from mips participant about graphman issues (same error i see in some of those subgraphs that were added to our indexing without me actually having a rule set for them):
failed to process trigger: block #18416963 (0x9145…4743), transaction 0093a40f3c15fbcedf58066975a3a49ab13d4e6ef854d633f3f74198866d801b: Store error: store error: relation "sgd2.router" does not exist wasm backtrace: 0: 0x2195 - <unknown>!src/v1-runtime/mapping/handleLiquidityAddeduser quote:
It originally failed so I deleted it with graphman and restarted it using decisionBasis offchain via the CLI. I think the important bit is the sgd2.router part. If I understand correctly sgd2 is the namespace for a deployment? If so, the latest deployment for this subgraph is sgd9. Anyone have any idea where it is picking up the old sgd2 prefix from?
Hi, this was me reporting the issue in Discord. I've been having some issues syncing one of the MIPS phase 0 subgraphs (a whole other story) but have been able to produce the same result twice now when trying to clear out an old deployment with graphman.
- Subgraph sync fails with a deterministic error.
- Set
decisionBasis neverso the agent removes the deployment. - Stop the indexer agent.
graphman info QmWq1pmnhEvx25qxpYYj9Yp6E1xMKMVoUjXVQBxUJmreSegraphman removethe two deployment names (one was added viacurlfollowing the MIPS guide, second was added using the agent anddecisionBasis offchain).graphman unused recordgraphman unused remove- Start the indexer agent.
- Re-allocate through the agent with
decisionBasis offchain - See this error on the first block that has data:
failed to process trigger: block #18416963 (0x9145…4743), transaction 0093a40f3c15fbcedf58066975a3a49ab13d4e6ef854d633f3f74198866d801b: Store error: store error: relation "sgd2.router" does not exist wasm backtrace: 0: 0x2195 - <unknown>!src/v1-runtime/mapping/handleLiquidityAdded
I've been poking around in the database and the below is the only reference I can find to sgd2. Could it be the cause? sgd2 was the old deployment namespace that was replaced with sgd5 when I redeployed. Should I delete it? Any pointers on a way to recover from this or should I look at rebuilding the DB from scratch again?
graphnode_db=# select * from unused_deployments;
deployment | unused_at | removed_at | subgraphs | namespace | shard | entity_count | latest_ethere
um_block_hash | latest_ethereum_block_number | failed | synced | id | created_at
------------------------------------------------+-----------------------------+-------------------------------+-----------+-----------+---------+--------------+----------------------------------
----------------------------------+------------------------------+--------+--------+----+-------------------------------
QmWq1pmnhEvx25qxpYYj9Yp6E1xMKMVoUjXVQBxUJmreSe | 2022-10-03 20:42:29.6186+00 | 2022-10-03 20:42:42.259077+00 | | sgd2 | primary | 257188 | \xe963595eafa10c28c8e43061ca8d21c
b943f28acf87983170ef81946dea48539 | 24352899 | t | f | 2 | 2022-10-02 15:49:03.845215+00
(1 row)
Appreciate this doesn't really fit with the original issue reported - happy to open a new one if they are likely unrelated.
The error store error: relation "sgd2.router" does not exist comes from an internal cache where we cache details about a subgraph's layout in the database for up to 5 minutes since constructing it is somewhat computationally intensive. Usually, the data for a deployment is deleted hours after it is no longer used by any subgraph, so that cache time is totally fine, and in normal operations, this error never happens.
In the scenario above, the old deployment is replaced by the new one too rapidly for the above cache. I am not sure what problem this sequence of steps is meant to address, but restarting all graph-node instances after graphman unused remove is run would avoid this error. Alternatively, if this is meant to address a transient infrastructure problem, graphman rewind might be a better option.
Just in case it wasn't clear from my previous comment: the database is totally fine despite this error.
Just in case it wasn't clear from my previous comment: the database is totally fine despite this error.
Hey Lutter, I really appreciate you explaining what happened here. it all makes perfect sense and I can confirm that clearing the cache by restarting the graph nodes has done the trick. My problem can be struck from the record on this issue. Thanks again!
(and I'll read up on graphman rewind)
I just opened PR #4044 that will make sure the error store error: relation "sgd2.router" does not exist does not appear anymore when rapidly deleting and redeploying a subgraph.