Check Last-Modified before update tenant index
What this PR does
Update (download, unzip and parse) tenant index only if file has changed in storage (changed Last-Modified time). It is useful in case if we need low-latency block detection. With this changes we may use very short update intervals (ex. 1 second).
Checklist
- [ ] Tests updated
- [ ] Documentation added
- [ ]
CHANGELOG.mdupdated - the order of entries should be[CHANGE],[FEATURE],[ENHANCEMENT],[BUGFIX]
👋 Hi! Thanks for your interest in the project.
Could you share more details about your use case? I have some thoughts in random order, but I fundamentally don't understand the use case, so I would like to ear more about it first.
Random thoughts:
- Mimir has been designed to not require an up-to-date view over the bucket. What's your use case where you need it?
- The bucket index is updated by the compactor. Even if you reduce the blocks cleaner interval to 1s, it will realistically some time to update the bucket index. What's your expected max latency between when something change in the bucket and when queriers and store-gateways detect it?
- This PR introduces a S3 call to check the last modified, before actually reading the index. An S3 API call to fetch attributes (HEAD) is billed as a GET. Intra region bandwidth between S3 and compute machines is not billed, so costing wise there should be no difference (pretty much the same for other cloud providers). I assume the check on last modified has been introduced to reduce CPU utilization, but what's the actual impact? How many tenants do you have in your cluster?
Marco, Hi!
At first, thank you for the fast answer.
Your random thought number three is correct. In our case, mostly impact is on CPU usage.
Additional information for more understanding:
- We have 400+ tenants in our cluster
- Why we need low value for sync period? We deliver blocks not only from ingesters. We have our own agent, and it can deliver metrics after long storage unavailability. It's uploads block into S3 directly. Because of this, for us, important low sync interval.
We understand that we describe a corner case, and this PR doesn't have any improvement in most of the cases, but it can reduce resources utilization in some cases. And, also, it doesn't require any additional support in future time.
I think that it could be flag or config defined behaviour.
Thanks for providing more details.
We have our own agent, and it can deliver metrics after long storage unavailability. It's uploads block into S3 directly
If the agent deliver metrics "after long storage unavailability" is that critical to have these metrics available for querying 1 second after the block has been uploaded?
Because of this, for us, important low sync interval.
Could you share some numbers to let me further understand your use case, please?
- How low the sync interval is expected?
- What value you set for
-compactor.cleanup-interval? - If you build this PR and deploy it to a querier or store-gateway, what's the drop in CPU utilization?
Thanks!
- What value you set for -compactor.cleanup-interval?
1 minute. So
- How low the sync interval is expected?
We expect sub 2 minutes data availability (we use 1 minute point intervals).
- If you build this PR and deploy it to a querier or store-gateway, what's the drop in CPU utilization?
Will provide numbers in closest time
We found that storage gateway doesn't use bucketindex.Loader, so for now this changes doesn't improve performance in our case. We need more research. I'll back with new information soon.
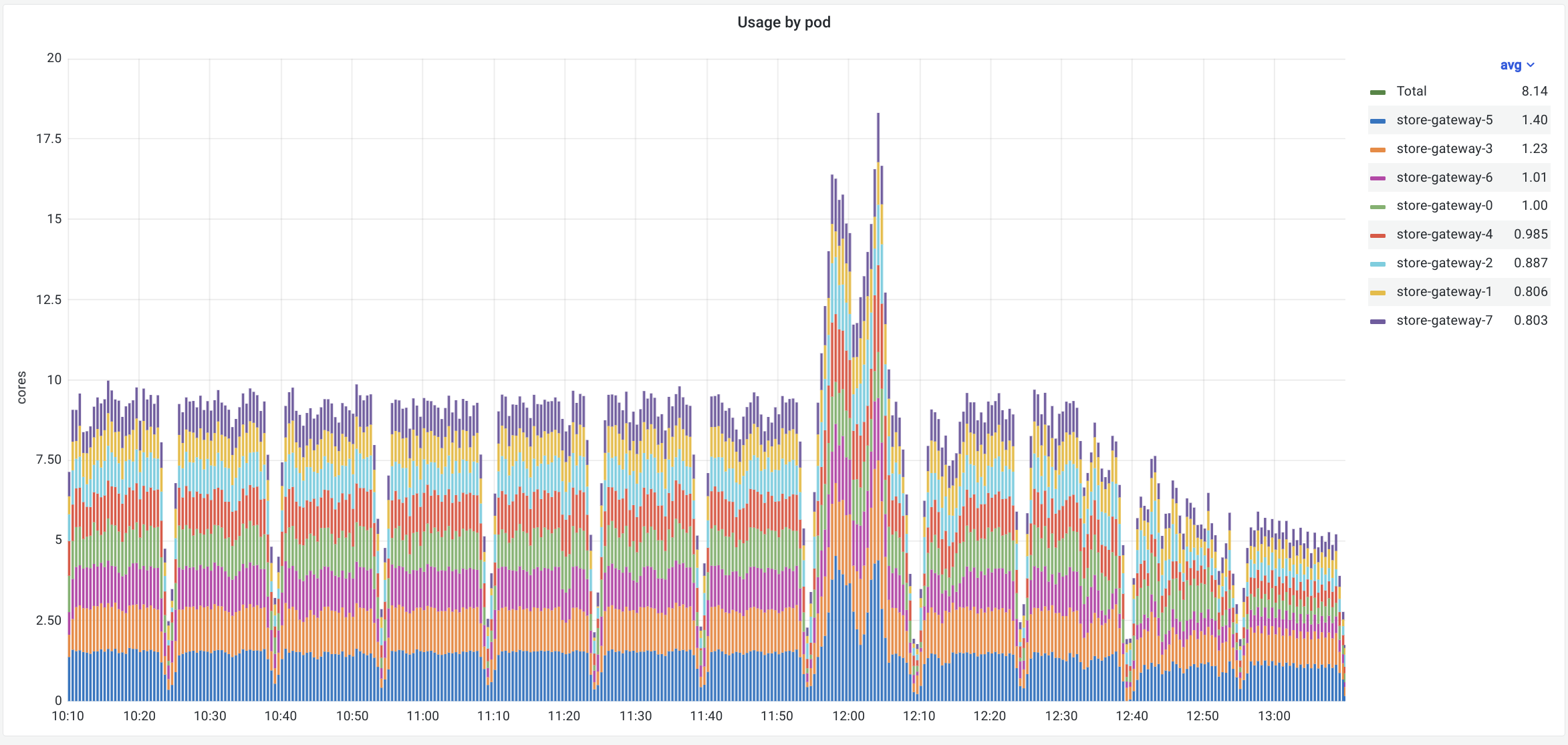
We've got 2x decrease CPU usage after using index loader (with last-modified check) in store-gateway:
To make all checks pass again, please rebase this PR on top of main. Thank you.
The CHANGELOG has just been cut to prepare for the next Mimir release. Please rebase main and eventually move the CHANGELOG entry added / updated in this PR to the top of the CHANGELOG document. Thanks!