quickdraw-dataset
 quickdraw-dataset copied to clipboard
quickdraw-dataset copied to clipboard
Convert saved drawing images/files (png/jpg) to same numpy (npy) bitmaps for prediction
I have been scratching my head for over 5 days now trying various models and code repos and still have not been able to make it work. The model trains well and evals well but I am failing at actual predictions.
Instead of models based on drawing strokes, I have been playing with models using actual drawing images to predict (like a image classifier) and most of these models use the numpy bitmaps dataset (npy files).
Everything is well and good except the part to feed the model drawing from a saved image file (since most of these articles or code repos fed it via canvas or JS or android). I tried to replicate their prediction code (mainly image processing) as much as I can in python but the predictions are still way way wrong.
Here is my image processing and prediction code:
from PIL import Image
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
from random import randint
from scipy.misc.pilutil import imsave, imread, imresize
%matplotlib inline
clock = qd.get_drawing("circle")
apple = clock
apple.image.save("apple.png")
mypath = "data/"
txt_name_list = []
for (dirpath, dirnames, filenames) in walk(mypath):
if filenames != '.DS_Store':
txt_name_list.extend(filenames)
break
def adjust_gamma(image, gamma=1.5):
invGamma = 1.0 / gamma
table = np.array([((i / 255.0) ** invGamma) * 255
for i in np.arange(0, 256)]).astype("uint8")
return cv.LUT(image, table)
def preprocess(img):
# for sketch & not canvas drawings use the following:
gray = cv.bilateralFilter(img, 9, 75, 75)
#
gray = cv.erode(gray, None, iterations=1)
#
gray = adjust_gamma(gray, 1.1)
#return gray
th3 = cv.adaptiveThreshold(gray, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY_INV, 11, 2)
#th3 = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C,cv.THRESH_BINARY_INV, 11, 2)
return th3
#img = apple.image.convert("L")
#imgData = request.get_data()
#convertImage(imgData)
print("debug")
x = imread('apple.png', mode='L')
x = preprocess(x)
#x = cv.bitwise_not(x)
x = imresize(x, (32, 32))
x = x.astype('float32')
x /= 255
x = x.reshape(1, 32, 32, 1)
print(txt_name_list)
#print(x)
out = model.predict(x)
#print(out)
print(np.argmax(out, axis=1))
index = np.array(np.argmax(out, axis=1))
index = index[0]
print(txt_name_list[index])
plt.imshow(x.squeeze())
There is quite a difference between how image looks in numpy dataset and how it comes after I process it.
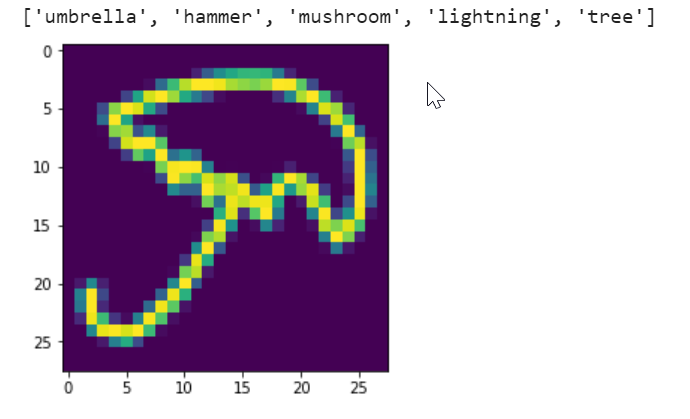
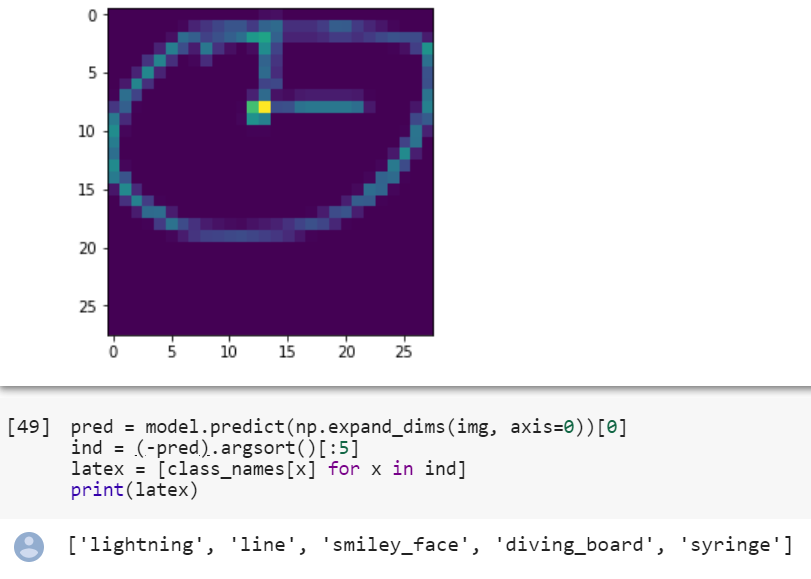
Here is my full model:
from __future__ import print_function
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from os import walk, getcwd
import h5py
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.utils import np_utils
import cv2 as cv
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D, BatchNormalization, AveragePooling2D
from keras import backend as K
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from keras.optimizers import SGD
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping,ModelCheckpoint
from sklearn.metrics import confusion_matrix
#For Multi GPU
from keras.utils import multi_gpu_model
from keras import metrics
batch_size = 128
epochs = 40
img_rows, img_cols = 28, 28
mypath = "data/"
txt_name_list = []
#slice_train = 30500
slice_train = 10000
def top_3_acc(y_true, y_pred):
return metrics.top_k_categorical_accuracy(y_true, y_pred, k=3)
def readData():
x_train = []
x_test = []
y_train = []
y_test = []
xtotal = []
ytotal = []
x_val = []
y_val = []
for (dirpath, dirnames, filenames) in walk(mypath):
if filenames != '.DS_Store':
txt_name_list.extend(filenames)
break
#print(mypath)
i=0
classescount = 0
for txt_name in txt_name_list:
txt_path = mypath + txt_name
x = np.load(txt_path)
print(txt_name)
print(i)
classescount += 1
x = x.astype('float32') / 255. ##scale images
y = [i] * len(x)
x = x[:slice_train]
y = y[:slice_train]
if i != 0:
xtotal = np.concatenate((x, xtotal), axis=0)
ytotal = np.concatenate((y, ytotal), axis=0)
else:
xtotal = x
ytotal = y
i += 1
print(classescount)
print("xshape = ", xtotal.shape)
print("yshape = ", ytotal.shape)
x_train, x_test, y_train, y_test = train_test_split(xtotal, ytotal, test_size=0.3, random_state=42)
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2, random_state=1)
return x_train, x_val, x_test, y_train, y_val, y_test, classescount
def lenet(x_train, x_val, x_test, y_train, y_val, y_test, num_classes):
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
x_val = x_val.reshape(x_val.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
x_val = x_val.reshape(x_val.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# more reshaping
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_val = x_val.astype('float32')
x_train /= 255
x_test /= 255
x_val /= 255
# convert class vectors
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
y_val = keras.utils.to_categorical(y_val, num_classes)
x_train = np.pad(x_train, ((0, 0), (2, 2), (2, 2), (0, 0)), 'constant')
x_val = np.pad(x_val, ((0, 0), (2, 2), (2, 2), (0, 0)), 'constant')
x_test = np.pad(x_test, ((0, 0), (2, 2), (2, 2), (0, 0)), 'constant')
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_val.shape[0], 'validation samples')
print(x_test.shape[0], 'test samples')
print(y_train.shape)
print(input_shape)
model = Sequential()
model.add(Conv2D(filters=6, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 1)))
model.add(AveragePooling2D())
model.add(Conv2D(filters=16, kernel_size=(3, 3), activation='relu'))
model.add(AveragePooling2D())
model.add(Flatten())
model.add(Dense(units=120, activation='relu'))
model.add(Dense(units=84, activation='relu'))
model.add(Dense(units=num_classes, activation='softmax'))
filepath = "saved/weightslenet.{epoch:02d}.h5"
ES = EarlyStopping(patience=5)
check = ModelCheckpoint(filepath, monitor='val_acc', verbose=1, save_best_only=False, mode='max')
#model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy', top_3_acc])
#Trying Multi GPU
#model = multi_gpu_model(model, gpus=2)
#model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs,verbose=1, validation_data=(x_val, y_val), callbacks=[ES, check])
#model.fit(x_train, y_train,batch_size=batch_size,epochs=epochs,verbose=1, validation_data=(x_val, y_val), callbacks=[ES, check])
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
model.save('cnnOld2.h5')
print("Saved model to disk")
#
# cm = metrics.confusion_matrix(test_batch.classes, y_pred)
# # or
# # cm = np.array([[1401, 0],[1112, 0]])
#
# plt.imshow(cm, cmap=plt.cm.Blues)
# plt.xlabel("Predicted labels")
# plt.ylabel("True labels")
# plt.xticks([], [])
# plt.yticks([], [])
# plt.title('Confusion matrix ')
# plt.colorbar()
# plt.show()
print(y_test)
loaded_model = keras.models.load_model('cnnOld2.h5', custom_objects={"top_3_acc": top_3_acc})
print("test")
#y_pred = loaded_model.predict_on_batch(x_test)
#score = loaded_model.evaluate(x_test, y_test, verbose=0)
y_pred = loaded_model.predict(x_test)
print(y_pred)
indexes = np.argmax(y_pred, axis=1)
i=0
for y in y_pred:
y[y<1000]=0
# print("allzero",y)
y[indexes[i]] = 1
i+=1
cm = confusion_matrix(
y_test.argmax(axis=1), y_pred.argmax(axis=1))
acc = accuracy_score(y_test.argmax(axis=1), y_pred.argmax(axis=1), normalize=True, sample_weight=None)
cr = classification_report(y_test.argmax(axis=1), y_pred.argmax(axis=1))
print(cm)
print(acc)
print(cr)
def main():
x_train, x_val, x_test, y_train, y_val, y_test, num_classes = readData()
lenet(x_train, x_val, x_test, y_train, y_val, y_test, num_classes)
if __name__ == '__main__':
main()
Another and different approach I tried with same problem running predictions on saved images. This model also works on android but cannot seem to process image file same way to get prediction
https://colab.research.google.com/github/zaidalyafeai/zaidalyafeai.github.io/blob/master/sketcher/Sketcher.ipynb