nodejs-pubsub
 nodejs-pubsub copied to clipboard
nodejs-pubsub copied to clipboard
Pushing 400k messages creates 10m messages to pubsub
I tried to push avro file contents to pubsub (1 record/message). The file had 429 077 records but after the push pubsub graph showed about 10 million messages. Also logged the publish calls and it was called the correct amount of times (429 077). Code is below and it's highland stream wrapped to promise.
export const avroInBucketToPubSub: AvroInBucketToPubSub = ({
exportFile,
inputTopicName,
validator
}) => {
const pubsub = new PubSub();
return new Promise((resolve): void => {
const inputTopic = pubsub.topic(inputTopicName);
hl(exportFile.createReadStream().pipe(new streams.BlockDecoder()))
.filter(row => validator.isValid(row))
.map(JSON.stringify)
.map(Buffer.from)
.each(buff => inputTopic.publish(buff))
.done(resolve);
});
};
Environment details
- OS:
- Node.js version: v10
- npm version: 6.11.3
@google-cloud/pubsubversion: 0.30.1
Steps to reproduce
- push over 100k messages without waiting reply
Making sure to follow these steps will guarantee the quickest resolution possible.
Thanks!
Tested this with pubsub emulator and syncronous pull. Worked as intented but with the actual pubsub-service the message count just kept increasing and increasing (purged after 400k messages where nearing 10 million).
Where could i file a bug report to pubsub itself? It seems that pub/sub is horribly buggy. TO RECAP IT DOES NOT HAPPEN WITH MESSAGE BURST LESS THAN 100K.
Created example repo https://github.com/hixus/faulty-google-pubsub. Message multiplication was less but still 50% when I kept publisher on. Does the publisher also need to ack sent messages?
@hixus Hi and thanks for making a nice detailed example. I'm new to the client libraries, so I apologize up front if it takes a few tries to get this where it needs to go! (Also for the late response.)
After staring at the code a bit, I want to say that there may be an issue with the queue batching code in the client library. If there's an issue with the service itself, I'll try to get the matching internal bug report routed to the right people.
I built my own reproduction case that's just publishing really simple messages (101k of them) and I'm not seeing the problem, but I will try again tomorrow with your sample repo.
There are two variables for me:
- I'm using Node v12.13.0 ... will try out with 10.
- I'm using the latest nodejs-pubsub, which is now 1.4.0. Not much changed since 1.3.0 though, which it looks like your sample repo is using.
With your test, I am definitely seeing the dashboard jump up to 800k+ unacked messages, which is interesting. I'm also seeing more read messages than what was pushed. With my own test sample, for whatever reason, that's not happening. One thing I noticed with your test repro though, the draining via subscription takes a super long time, and it looks like I'm doing event-based draining, while you're doing sync draining using the v1 interface.
So my two current guesses are:
-
The slow draining is causing the Pub/Sub service to re-queue messages for delivery, since they didn't get acked within the deadline. That would also be consistent with the number of extra messages being kind of variable. I'm not entirely sure why they'd get delivered twice though, unless...
-
There's something that's just inherently different between the v1 sync and regular event-based subscription drain.
Will keep spending some time with this!
I managed to get it send correct amount of messages with v1.publisher (batches of 100 messages). Subscriber was changed to v1 because of this https://cloud.google.com/pubsub/docs/pull#streamingpull_dealing_with_large_backlogs_of_small_messages.
I think something is not working correctly with new publisher when dealing with large amount of messages. The reason could be fire and forget style (await for each send takes ages). But Pub/Sub itself seems to be ok.
With nodejs-pubsub 1.5.0, we made some changes that set new defaults and retry logic having to do with batching. I'm unsure if that'll help, but it's probably worth mentioning.
Was happening with me too I was pushing 6K messages and on the dashboard it showed 150K messages. My code had a problem of re-creating pubsub object every-time it wanted to publish the message. check this question on stackoverflow - [https://stackoverflow.com/questions/60297471/publishing-more-than-actual-messages-in-google-pub-sub-using-node-js-and-csv-par/60306869#60306869]
Thanks for that link! Yeah, I was helping someone earlier who was having troubles because of recreating the PubSub object itself for each request. I've been trying to push some hints into the samples that the PubSub object should be kept around. That the topic objects are also heavy is a good thing to know.
I just wanted to check in on this and see if it's still causing anyone problems. (Though I'm aware with https://github.com/googleapis/nodejs-pubsub/issues/847#issuecomment-579968039 there may still be an issue with the subscription wrappers in any case.)
I tried to modify the buffer options but after I got timeout and unstability issues.
Then I switched to GRPC and I don't experience any issue. See https://www.npmjs.com/package/@google-cloud/pubsub#running-grpc-c-bindings
Hmm, @alexander-fenster is this maybe related to the fixes for the micro-generator for batching?
That should be pushed out with 2.5.0, so it might be worth trying that to see if it helps.
https://github.com/googleapis/nodejs-pubsub/pull/1087
This is coming from old memories, so take it with a grain of salt: the status of the C++ client at this point is that it's in maintenance. So we are backporting some fixes, but not really adding new features anymore. Last I heard, we did get it working with Node 14 in some capacity, but it's unlikely to move forward beyond that. (@murgatroid99 would know more maybe?) Anyway, if that does fix it for you, go for it, but the longer term goal is to make grpc-js work for everyone.
@feywind This totally may be related to batching, in that case, the fix in #1087 could help.
I also experienced similar findings in my own projects.
Might this be expected behavior? For instance, if one is attempting to send more messages than can be published OR ack'd within a given time period, wouldn't subsequent retries (on the publish side), or subsequent delivery attempts (on the subscribe side), add to the total message count?
Maybe, but in this case we'll need more documentation because posting at high throughput is what PubSub was made for and we shouldn't struggle on that specific usecase
@anthonymartin @sylvainar Did either of you happen to test with 2.5.0? That's where the batching fix landed. (Also some grpc-js fixes.)
I don't work on the Pub/Sub service itself, but it seems like, from my understanding, you shouldn't see this many duplicate messages at the user code level, even if some of them need to be nack'd for retries. The library itself should be handling lease management. So maybe in the web console you'd see a lot of extra messages, but at the client receiving end, I'd think you wouldn't.
Take the above with a grain of salt though, I will bring this up with some other library authors and see if it's expected behavior on heavy load.
Sorry I don't work on this project anymore, however I'm sure that at the time of my latest comment I had the latest version published on npm.
We're seeing this issue with v2.5.0. We're able to reproduce it by looping over a large number of requests (in our case its a customer-driven CSV import) which calls .publish() n times. In our testing, a CSV with 11,000 items in it created about 200,000 publish requests.
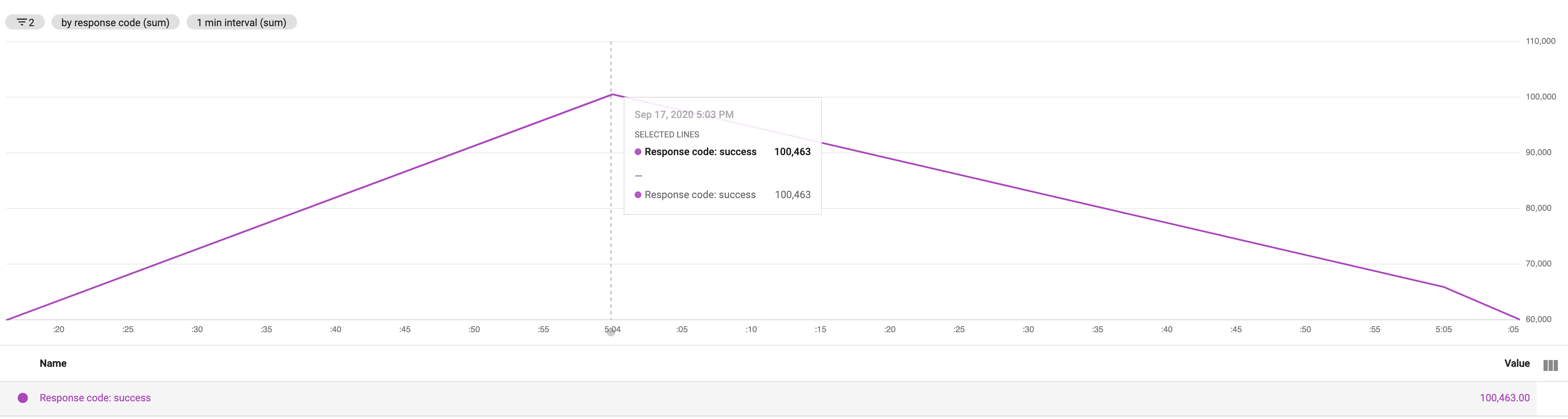
Of those requests, we're also able to verify that those ~200,000 requests become real messages as we are logging when we handle a message (new line counts as its own log so its 2x the size in this image):

So after some analysis, it's timeout errors that are causing the duplication. Simply, if we hit .publish() without waiting for a response (the Promise) it will eventually start:
{ Error: Retry total timeout exceeded before any response was received
at repeat (node_modules/@google-cloud/pubsub/node_modules/google-gax/build/src/normalCalls/retries.js:65:31)
at Timeout.setTimeout [as _onTimeout] (node_modules/@google-cloud/pubsub/node_modules/google-gax/build/src/normalCalls/retries.js:100:25)
at ontimeout (timers.js:498:11)
at tryOnTimeout (timers.js:323:5)
at Timer.listOnTimeout (timers.js:290:
@arbourd Thanks for looking at that further, and this is actually a really useful data point.
@alexander-fenster This seems to be a retry timer in the gax library, could there be an issue there?
@kamalaboulhosn This sure kind of sounds like what we were talking about the other day in the meeting, re: publish() not controlling flow?
Yeah, this definitely sounds like the issue where the publisher is overwhelmed and as a result, there are timeouts on publish, resulting in many reattempted publishes. Some type of flow control to restrict the number of messages outstanding simultaneously would likely help here.
I've proposed a possible solution to this here, with a rough patch included https://github.com/googleapis/nodejs-pubsub/issues/1081
@mnahkies Sorry this has languished a bit. gRPC related issues are hard to diagnose cleanly, and we have a few outstanding ones. There is some new debug info going into grpc-js, so that may help if reducing the connections doesn't.
I'm working this week on getting a few lingering issues closed out, and this one is today's target, so I will look at your patch in more detail after a few meetings.
After taking a look at all of this, and talking to some others, I am coming around to thinking that this might be better solved by server side publisher flow control. But I'm not 100% sure that's enabled yet. @kamalaboulhosn would know, he can respond early next week hopefully. It would be better to avoid adding the code suggested in https://github.com/googleapis/nodejs-pubsub/issues/1081 (much as I appreciate its existence :)) if it'll be deprecated again soon.
I think I misunderstood the publisher flow control plans, so we will probably still need the submitted patch.
@feywind I'm happy to tidy up the patch a bit (rebase and add tests, plus test it out e2e) - I just wanted some validation of the approach before investing too much work into it.
My understanding of the issue is such that I don't see how server side flow control can solve it. The issue as I understand it is (and please correct me if I'm getting this wrong):
- Large quantity of messages given to publisher class quickly
- All messages are batched and given to the gRPC lib via google-gax
- A timeout is started
- A single http2 connection is used to start pushing these to server
- That connection is saturated by the large quantity of message batches, causing some batches to timeout client side and be re-queued (but the timed out batches actually do get sent eventually)
Key point being that the timeout and re-queue is all happening client side.
I do think that rather than the patch I suggested, it could make more sense to handle this at a lower level.
It's a bit out of my wheelhouse, but it looks like grpc-js does some kind of connection pooling which might completely invalidate my assumptions above https://github.com/grpc/grpc-node/blob/master/packages/grpc-js/src/subchannel-pool.ts - so perhaps there is a solution that just involves enabling/increasing this https://github.com/grpc/grpc-node/blob/1612bf0bae31e5fac024eb6d024436f9cf77df60/packages/grpc-js/src/channel-options.ts#L33 for the gprc client in the pubsub sdk (or it's already enabled and I just can't find where)
@kamalaboulhosn I don't suppose you can provide any thoughts on this?
So there is no such thing as publisher-side flow control for cloud that would help the user here. We are in the process of adding publisher flow control to our client libraries and I think there is still outstanding work on node for this. I think that's the next step to take here.
What Kamal said. ^ I think that several issues are going to be closed by getting publisher-side flow control in place. It's not there yet in Node, though.
I think the scenario described by @mnahkies is possible, from the grpc-js point of view. Specifically, it may be possible for grpc-js to queue a message to be sent in an http2 stream, and for the deadline to pass before that message is sent. As far as I know, there is no mechanism to un-queue a message, so in that case, the server will eventually get the message, and it will later get the cancellation associated with the deadline.
I do want to clarify that that's now what the subchannel pool is. The connections associated with a channel are determined by the name resolution results and the load balancing policy, and there is generally only one connection per backend address. The subchannel pool is for sharing connections between channels, and that channel option just disables that sharing.