Investigate sequencer init tree latency
I'm looking into why we are getting linear growth of sequencer latency without any changes in the number of leaves being sequenced. It looks like the only part of the sequencing process that is getting slower as the tree grows is initMerkleTreeFromStorage which makes sense, each subsequent run requires retrieving a larger and larger tree (or more accurately set of sub trees).
Originally I was confused as I thought there was persistent caching of subtrees but after looking at the code closer it looks like the existing caching only happens at the storage.LogTreeTx level. This means that subsequent runs of the signer don't get the benefit of cached subtrees and have to go and build the cache again each time.
Is there a specific reason for not caching this information at a higher level? It seems like it'd be significantly faster to just retrieve whatever new stuff was generated since the last sequencing operation.
The cache only contains subtrees that will be affected by the subsequent write. So the time shouldn't be increasing linearly because of the subtree packing and I don't think we saw this in testing. Might need more investigation here.
Reading each time ensures that there's a consistent view of the database state. We did consider longer-term caching but went with the simpler approach that was easier to reason about correctness.
Ah, I think my major mistake here was thinking that the nodes needed to reconstruct the tree were stable, looking closer at the code I now see that's incorrect. It looks like there would be some overlap between signing operations but the required cache size in order to get a viable number of cache hits seems like not a workable trade off.
I'm now even more confused why we are seeing such linear growth (but also why we are getting up to ~1.5 seconds for tree initialization especially since it looks like <10 nodes need to be retrieved). I wonder if the extra latency is just a artifact of retrieving all of the nodes serially instead of in batches (per Sequencer.buildMerkleTreeFromStorageAtRoot), I guess if each read took ~150ms this would make sense.
I'll do some experiments and see if I can come back with some more useful information.
I might look at instrumenting this code so we can see how much work it's doing and get more detail on latency.
We can look at the SQL query plan as well. It's quite an expensive one IIRC and maybe batching it would help.
Just as a matter of interest how big is your log tree at the moment? Wondering if you've gone past the range we tested with yet.
Also are you able to use a test instance to get some performance numbers / query plans? We're considering bringing up a CI instance alongside CloudSpanner but not sure how soon we can get this done.
Our current test tree isn't very big, we're somewhere around ~50 million entries. I'd be happy to run any experiments you can think of.
We've been banging our heads against this a bit internally to see if we could come up with anything interesting. I think our main conclusion is that due to the use of a subquery/join in the get-subtrees query while batching provides a speed up at our current tree size (around 2x using this rough patch https://github.com/google/trillian/compare/master...rolandshoemaker:batch-init-tree) it's likely that as the tree continues to grow this performance will degrade to be worse than the unbatched version.
I'm currently looking at if the unbatched query can be sped up by not using max(...)/GROUP BY with the assumption that it'll only ever be used with a single subtree ID (and also if the subtree queries can be effectively parallelized).
I'm a bit surprised as we tested with much larger trees than that. I ran the GCE / Galera test up to about 700M and we got to around 1B with CloudSQL.
If you're playing with SQL another thing I've considered trying is seeing whether it's quicker to simplify the query and scan for the latest version in code rather than have MySQL do the work. There can never be more than (256 / average sequenced batch size) versions for each node but the rows are fairly large so it could also be worse. I think the only way is to try it.
I haven't had time to set up a test environment yet though I might get time to work on it soon.
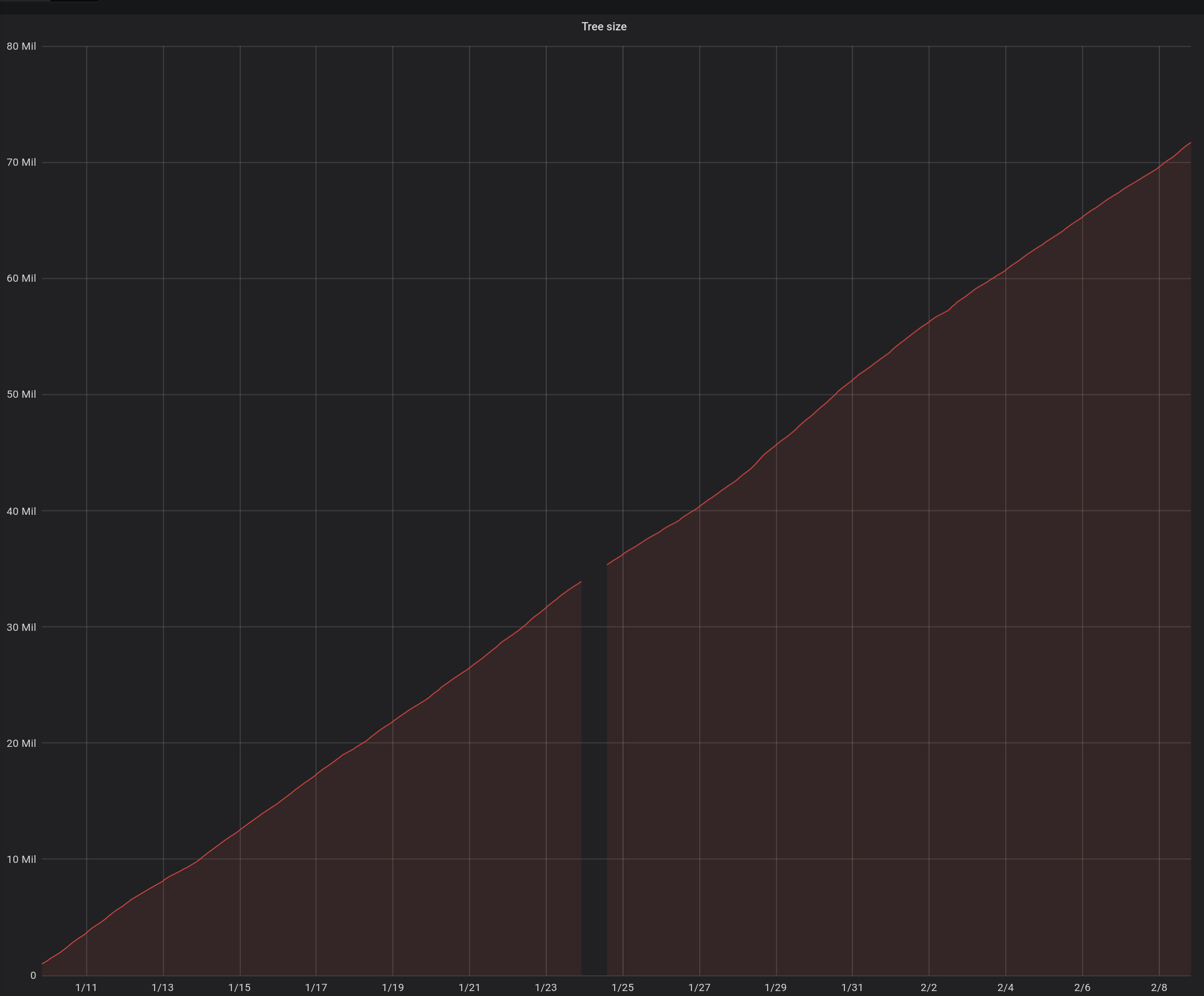
Here's some grafana output showing the tree size and init tree latency increasing for two separate trees. The database is MariaDB 10.3.8.
Tree with 72M certs
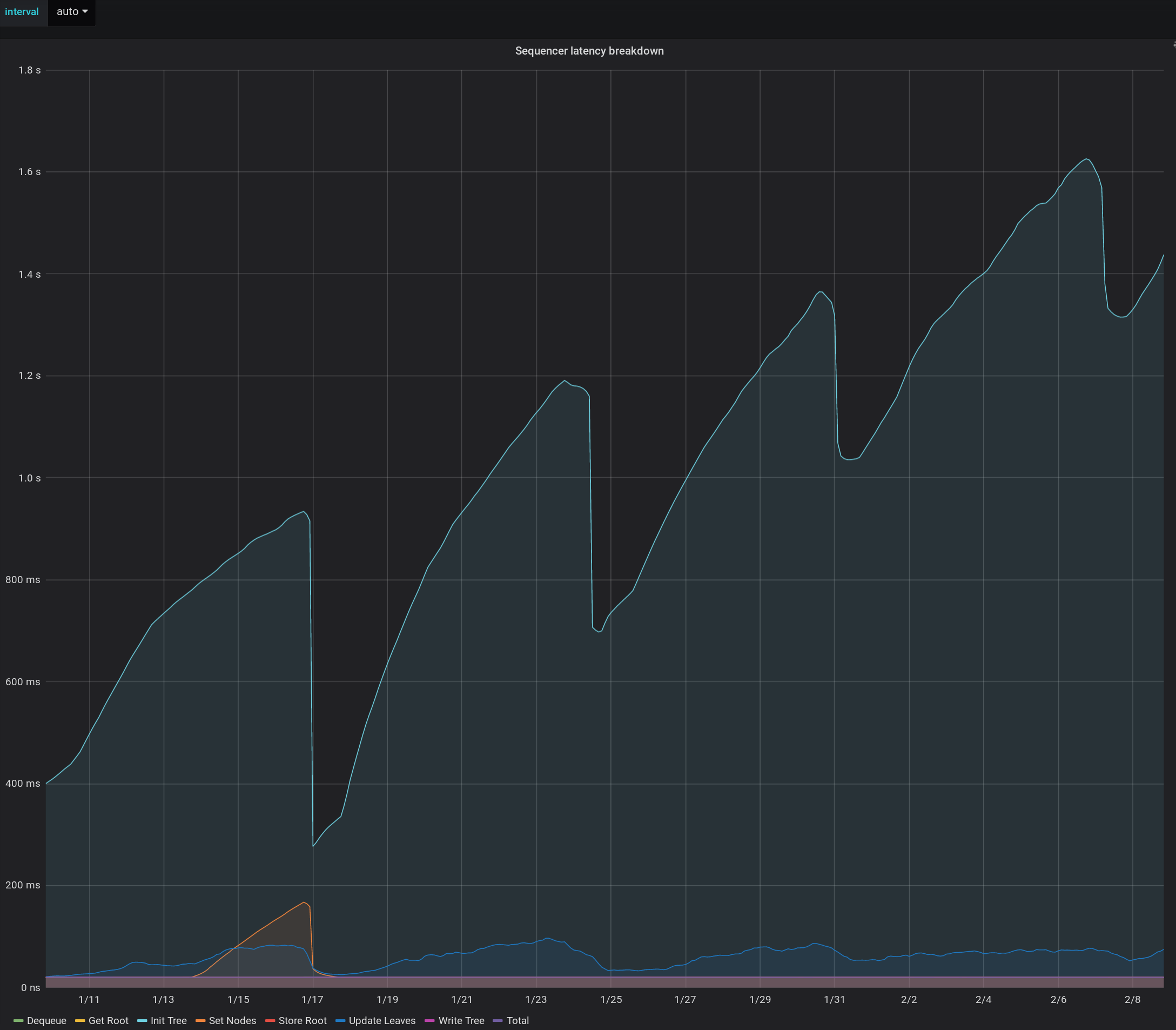
Tree with 4.5M certs

A bit of background: When the sequencer starts a transaction, it loads a thing that we call a "compact Merkle tree" which is basically the right border of the tree of size O(log N). It then appends the new leaves to this structure, and stores the new tree nodes.
I think it might be loading each node/stratum of the compact tree individually, that's why latencies for bigger trees add up. It could also explain this sawtooth latency pattern on one of the graphs - the number of nodes in the compact tree decreases upon reaching certain K * power-of-2 positions.
Some ways to optimize this (ideally all of them):
- Make a list of nodes to fetch in advance, and then issue a single request.
- Don't load the whole compact tree, because in most cases we are interested in just a couple of nodes in the lower level, the upper levels change very rarely. The precise set of nodes that we are interested in could be computed with the help of compact ranges - it's a new technique that I have plans to port into Trillian at some point.
- Cache the compact Merkle tree between sequencing runs.
Well it doesn't happen on CloudSpanner. And these are small trees so there aren't that many nodes involved. A path in a tree this size crosses ~5 subtrees, which is the unit they're fetched in. That should be a trivial read for any decent database.
Whatever mechanism is used here must have a valid up to date view of the tree. That's why we build it each time.
Let's consider 2 consecutive signer transactions:
TX1:
- Read compact tree C1.
- Append entires E1 to C1. That will generate a list of new nodes N1 to store, and the compact tree will transform to C2.
- Store N1 and some other data.
TX2:
- Read compact tree C2.
- (and 3) ditto
- Scenario 1 (normally is the case): This signer was the master, and nobody has updated the tree in between TX1 and TX2. Then reading C2 in TX2 will return exactly the same thing as a compact tree in TX1 computed using C1 and N1. There is no need to read it again (yet we need to re-create the tree cache, which is a different thing).
- Scenario 2 (double master situations, bugs, etc): If we know that something has happened in between signer runs (we can recognize this by comparing tree size cached after the previous TX1, and tree size read in TX2), then we can't rely on the cached compact tree, so we do read C2 from storage again.
Currently we always assume Scenario 2, but we can change it so that Scenario 1 is run in most cases.
This is somewhat orthogonal to why it's taking increasing amounts of time initialize it.
It should be somewhere proportional to log(log(tree size)), well not exactly that but log(tree size) is an upper bound on number of subtree fetches, which are all more or less the same maximum size.
@pgporada @rolandshoemaker Guys, would it be possible for you to test how this behaves with #1510 change? In that PR I am requesting all necessary compact tree nodes in one go (optimization 1 from the list above). Upd: Please use PR #1523
- Make a list of nodes to fetch in advance, and then issue a single request.
The PR is not ready to be merged (nodes returned by the storage layer need to be reordered), but it does work for the MySQL storage.
PR #1523 is now tested and merged. It would be really great to see how it affects performance in your setup.
Hm, I noticed this comment now, and it looks like the code linked from there is almost identical to my PR. I am slightly concerned with what it says about this being slower on bigger trees. I do think, however, that using batch request is the right thing to do, and any "de-batching" if necessary should happen on the storage layer.
Other changes have been done since #1188. I think the main one was fixing a bad query that was doing excessive work inside the fetching itself.
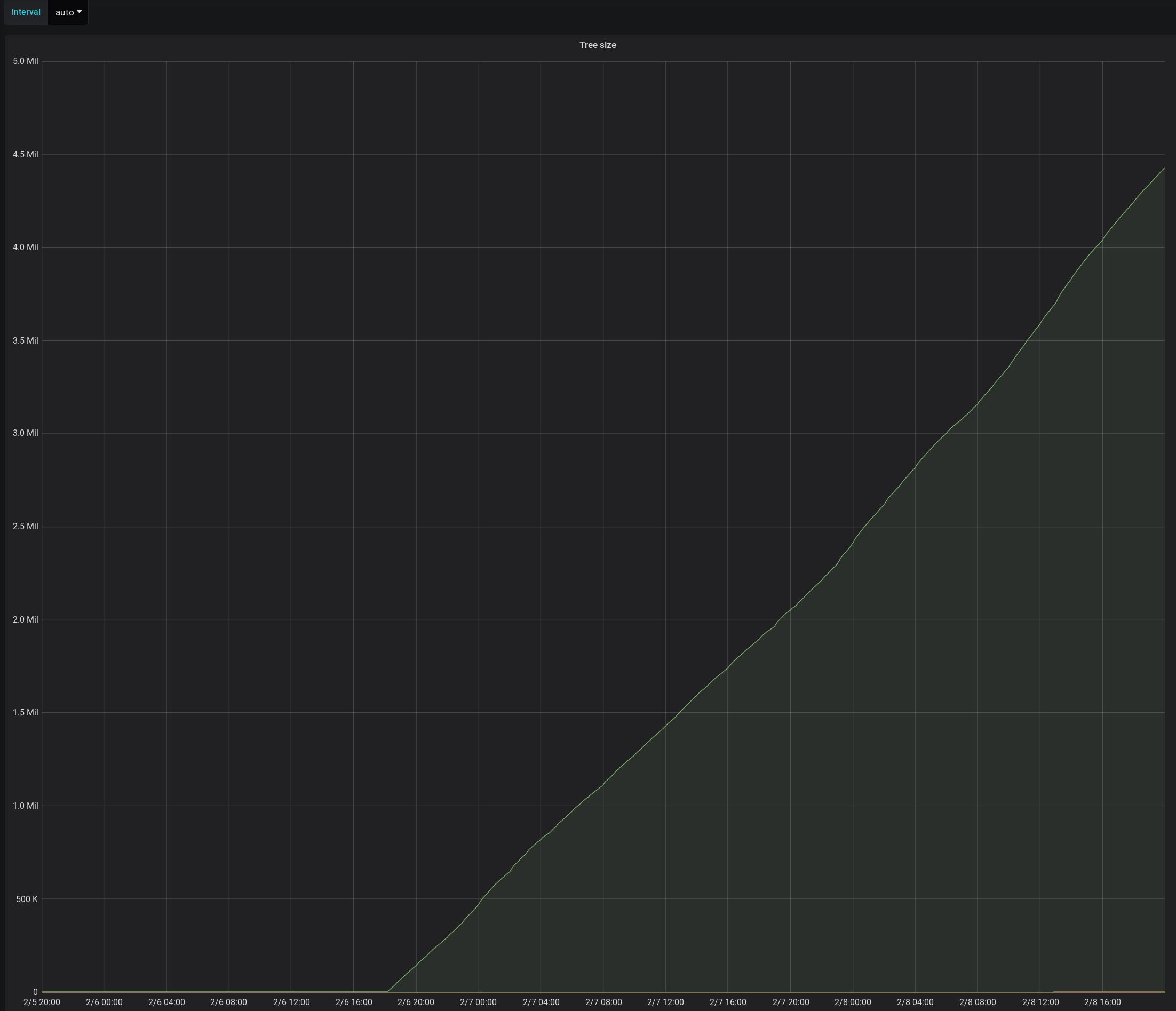
As an update, we have been running commit 07c5829 since May 1st, 2019 on a test log with a tree size of ~300M. We aren't seeing init-tree growth as we did on https://github.com/google/trillian/issues/1188#issuecomment-461929943 and it appears that on average init-tree has sped up by ~3s.
Good news, thanks for the data. But ~10s is still quite a lot, isn't it? I am working on an optimization (PR #1592) that will significantly reduce CPU usage in various places, such as loading the subtree cache (which is also part of the init-tree phase). It reduces complexity from O(N log N) to O(N), so in theory subtree cache population should become 4-8x faster (I should actually do a benchmark). I would be super interested in seeing more of such graphs :)
Although I suspect the main bottleneck is still the database, and the best speed-up here would be caching compact.Tree between sequencing runs. This is also on my list.
I created PR #1598 as a PoC (I expect it will result in nearly zero cost of init-tree), in case you are interested in testing that. In the meantime, I think the PR needs more work before it will be safe to submit.
Here's all the database metrics we've gathered for the particular test log running 07c5829 over the past 15 days.
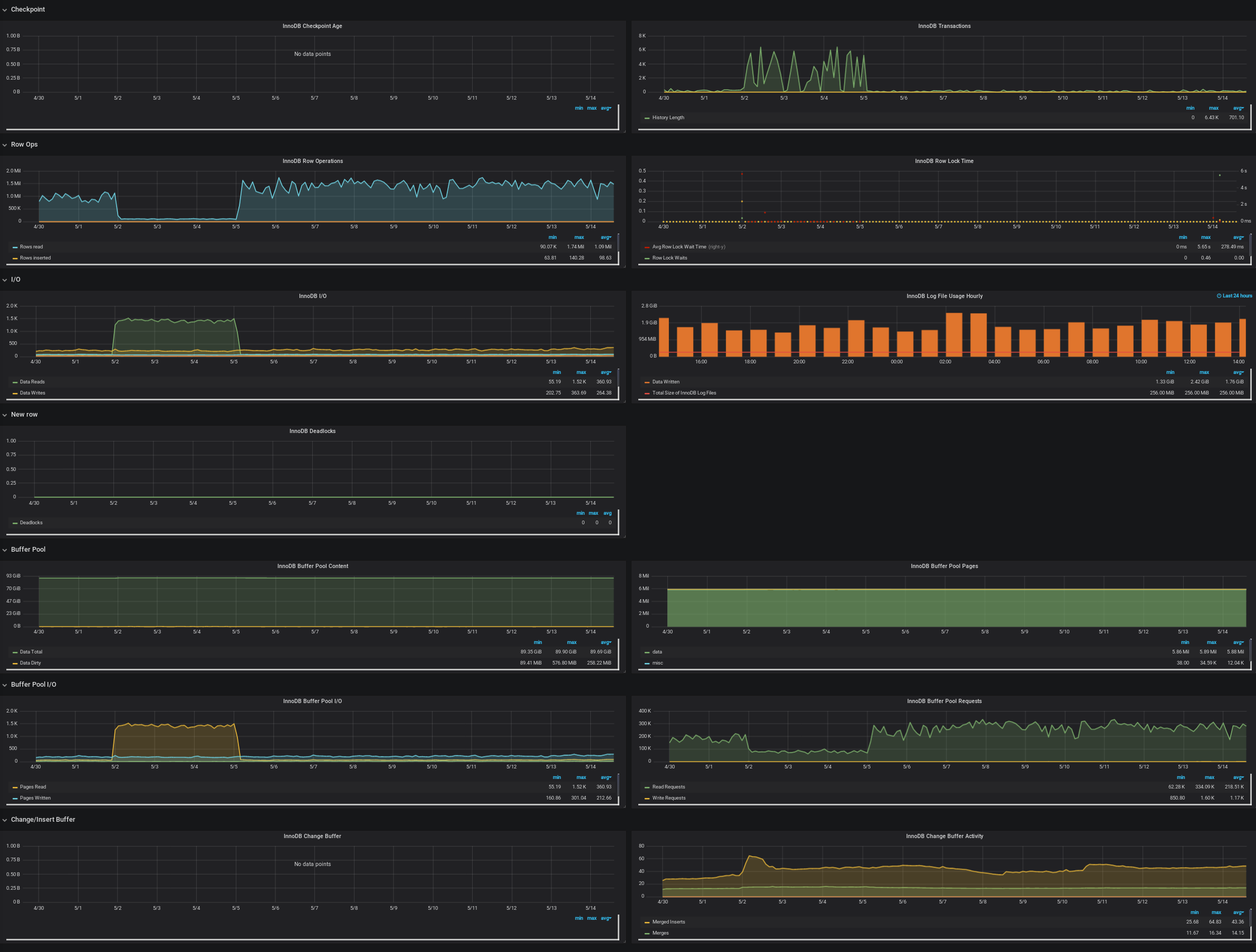
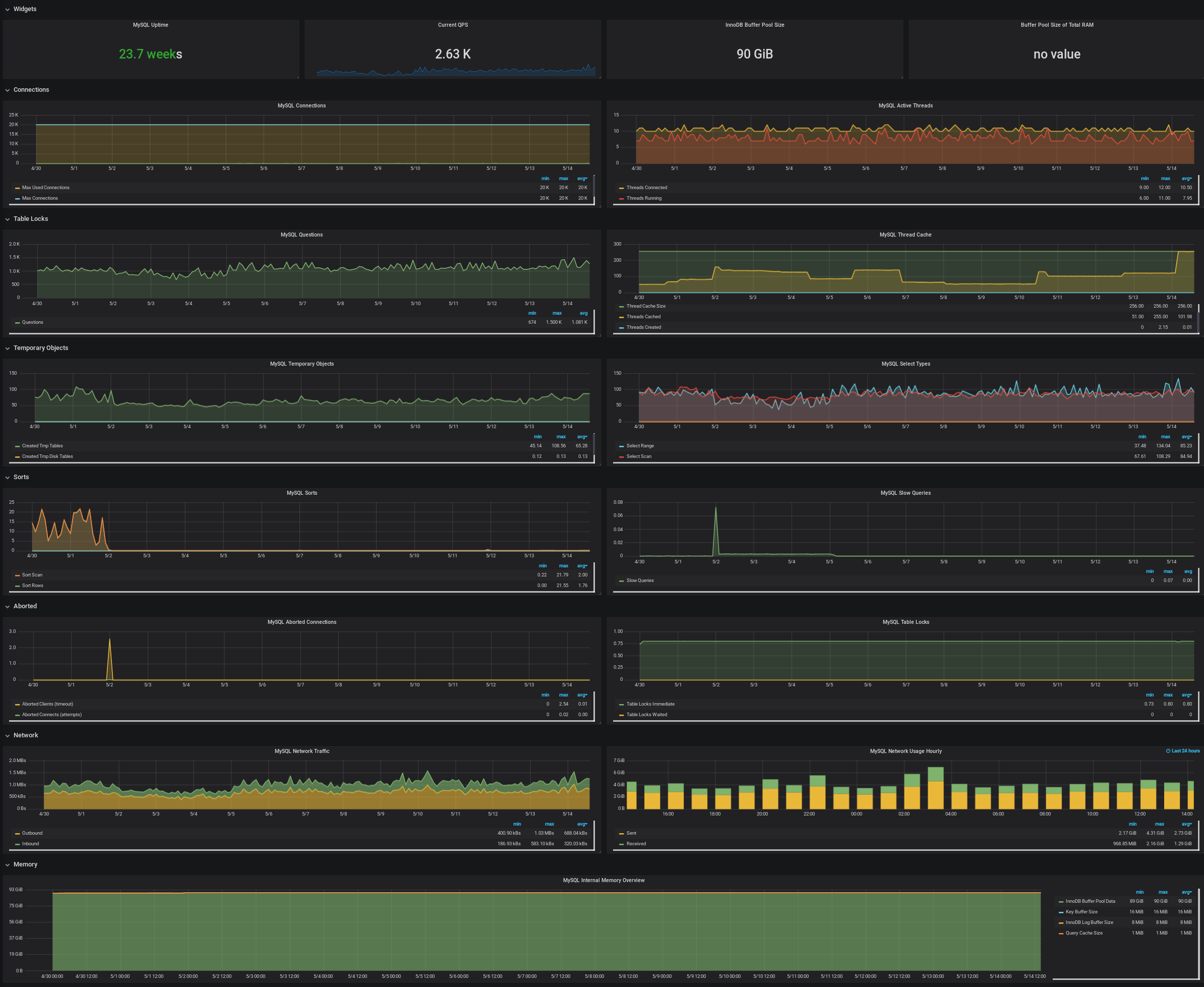
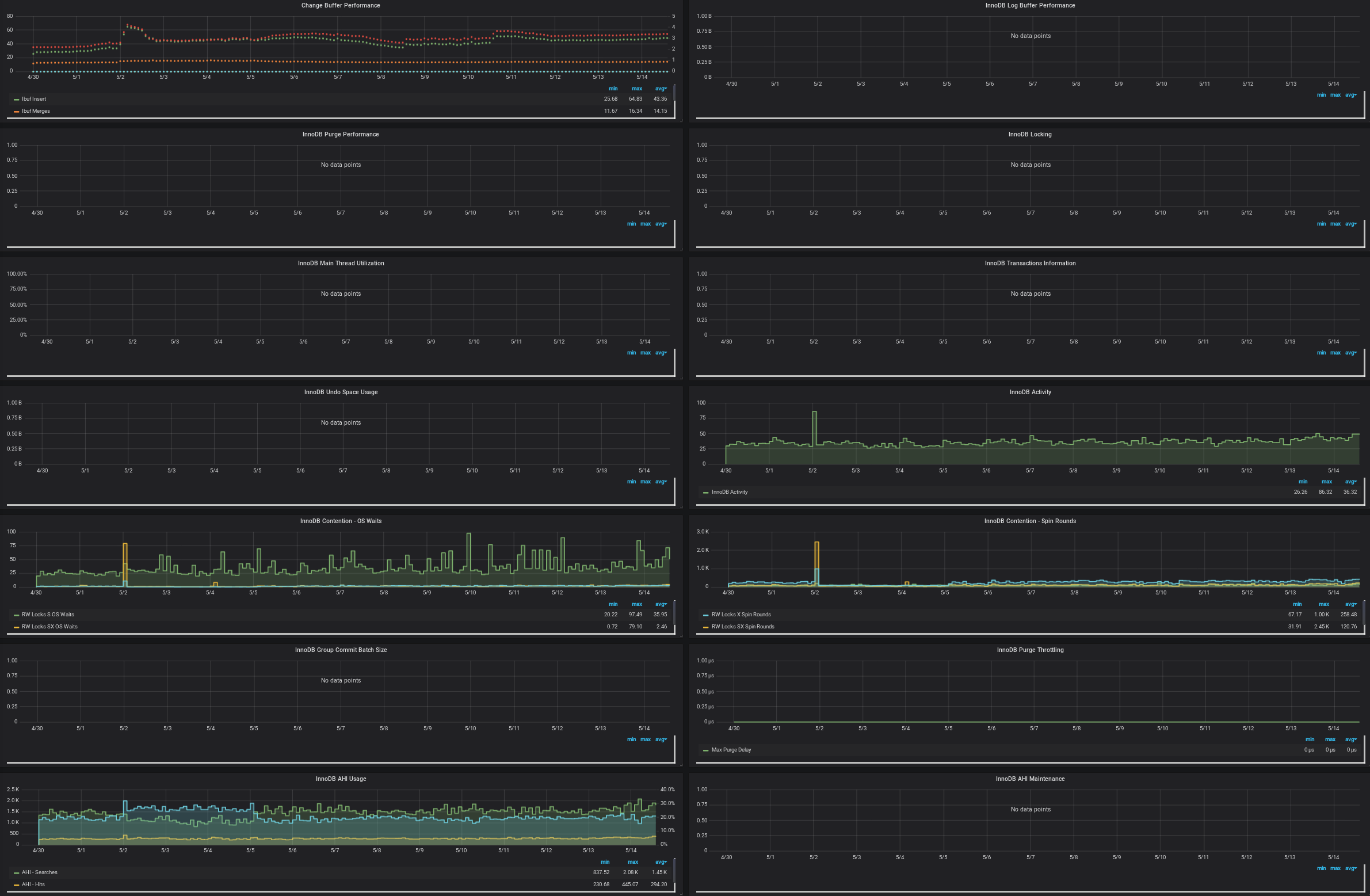
We're encountering some oddities with a particular log. We see the log_signer processing speedily right until a select statement gets stuck and the log_signer halts. The select eventually times out at 300s per our connection config. Once the query times out, the following goroutine information is dumped to the log, a rollback occurs, and the log_signer begins processing again. It's unclear why the log_signer cruises along right until it hits a wall.
I0515 22:11:15.082392 1 log_operation_manager.go:454] Group run completed in 0.02 seconds: 3 succeeded, 0 failed, 3 items processed
I0515 22:11:15.110065 1 sequencer.go:472] 1045204392378480099: sequenced 1 leaves, size 210937358, tree-revision 24322870
I0515 22:11:15.110078 1 log_operation_manager.go:435] 1045204392378480099: processed 1 items in 0.02 seconds (43.67 qps)
I0515 22:11:15.110091 1 log_operation_manager.go:454] Group run completed in 0.02 seconds: 3 succeeded, 0 failed, 1 items processed
I0515 22:11:15.156972 1 sequencer.go:472] 1045204392378480099: sequenced 1 leaves, size 210937359, tree-revision 24322871
I0515 22:11:15.156985 1 log_operation_manager.go:435] 1045204392378480099: processed 1 items in 0.02 seconds (45.00 qps)
I0515 22:11:15.156994 1 log_operation_manager.go:454] Group run completed in 0.02 seconds: 3 succeeded, 0 failed, 1 items processed
W0515 22:12:15.177265 1 tree_storage.go:224] Failed to get merkle subtrees: context deadline exceeded
W0515 22:12:15.177352 1 tree_storage.go:429] TX rollback error: sql: transaction has already been committed or rolled back, stack:
goroutine 2329070 [running]:
runtime/debug.Stack(0xc000222380, 0x10a5e20, 0xc000142950)
/usr/local/go/src/runtime/debug/stack.go:24 +0xa7
github.com/google/trillian/storage/mysql.(*treeTX).rollbackInternal(0xc000176280, 0xf94dd0, 0xc000af2368)
/go/src/github.com/google/trillian/storage/mysql/tree_storage.go:429 +0x5c
github.com/google/trillian/storage/mysql.(*treeTX).Close(0xc000176280, 0x0, 0x0)
/go/src/github.com/google/trillian/storage/mysql/tree_storage.go:440 +0x82
github.com/google/trillian/storage/mysql.(*mySQLLogStorage).ReadWriteTransaction(0xc00040e690, 0x10b9080, 0xc0009d22a0, 0xc0007941e0, 0xc000412e70, 0x10a5e20, 0xc0002b4e30)
/go/src/github.com/google/trillian/storage/mysql/log_storage.go:280 +0x164
github.com/google/trillian/log.Sequencer.IntegrateBatch(0x10b92c0, 0xc00013aee8, 0x10ac1e0, 0x187f360, 0x10bc600, 0xc00040e690, 0xc0007eacf0, 0x10b93c0, 0xc0005a83c0, 0x10b9080, ...)
/go/src/github.com/google/trillian/log/sequencer.go:323 +0x26e
github.com/google/trillian/server.(*SequencerManager).ExecutePass(0xc00036a090, 0x10b9080, 0xc0009d22a0, 0xe814fdb6d65b5e3, 0xc00041e280, 0xc00039c930, 0x100, 0x0)
/go/src/github.com/google/trillian/server/sequencer_manager.go:87 +0x5d8
github.com/google/trillian/server.(*logOperationExecutor).run.func1(0xc000d34130, 0xc000148100, 0x10b9040, 0xc00018fec0, 0xc000d34140, 0xc000d34128, 0xc000d34148)
/go/src/github.com/google/trillian/server/log_operation_manager.go:423 +0x14d
created by github.com/google/trillian/server.(*logOperationExecutor).run
/go/src/github.com/google/trillian/server/log_operation_manager.go:413 +0x23a
W0515 22:12:15.177364 1 tree_storage.go:442] Rollback error on Close(): sql: transaction has already been committed or rolled back
E0515 22:12:15.177373 1 log_operation_manager.go:425] ExecutePass(1045204392378480099) failed: failed to integrate batch for 1045204392378480099: 0e814fdb6d65b5e3: failed to fetch nodes: failed to get Merkle nodes: context deadline exceeded
E0515 22:13:06.473410 1 log_operation_manager.go:425] ExecutePass(1045204392378480099) failed: failed to integrate batch for 1045204392378480099: 1045204392378480099: Sequencer failed to load sequenced batch: 1045204392378480099: Sequencer failed to dequeue leaves: Error 1205: Lock wait timeout exceeded; try restarting transaction
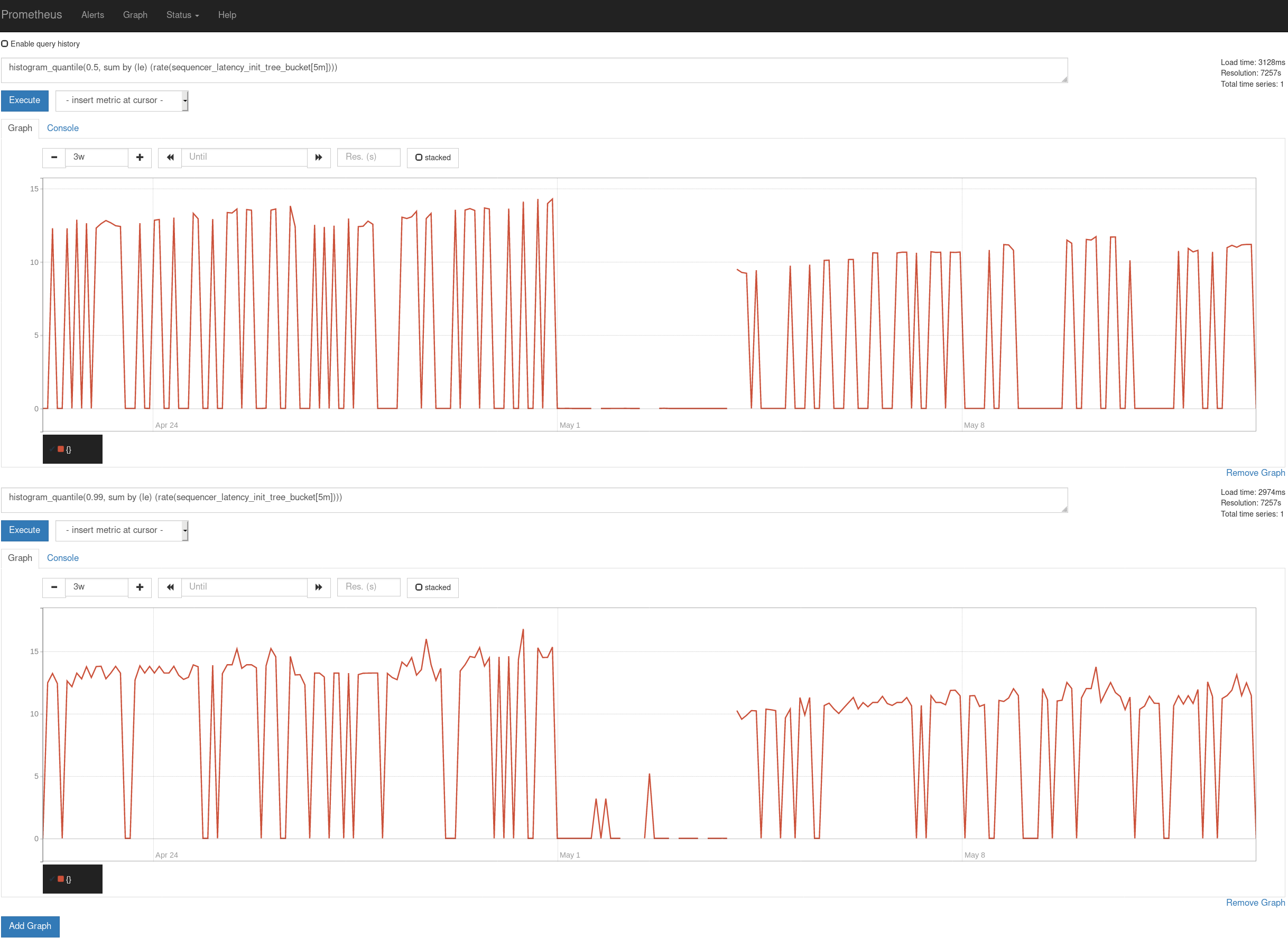
Here's a corresponding slow query. To note here is Rows_examined: 49094613 which seems very high because this tree has 200M certificates stored.
# Time: 190515 20:00:02
# User@Host: logsigner[logsigner] @ [10.96.12.104]
# Thread_id: 153017879 Schema: oak QC_hit: No
# Query_time: 300.001089 Lock_time: 0.000023 Rows_sent: 1 Rows_examined: 49094613
# Rows_affected: 0 Bytes_sent: 1327
use db;
SET timestamp=1557950402;
SELECT x.SubtreeId, x.MaxRevision, Subtree.Nodes
FROM (
SELECT n.SubtreeId, max(n.SubtreeRevision) AS MaxRevision
FROM Subtree n
WHERE n.SubtreeId IN ('\0\0\0\0\d','\0\0\0\0\','\0\0\0\0','\0\0\0\0') AND
n.TreeId = 1045204392378480099 AND n.SubtreeRevision <= 24319872
GROUP BY n.TreeId, n.SubtreeId
) AS x
INNER JOIN Subtree
ON Subtree.SubtreeId = x.SubtreeId
AND Subtree.SubtreeRevision = x.MaxRevision
AND Subtree.TreeId = 1045204392378480099;
/rdsdbbin/mysql/bin/mysqld, Version: 10.3.8-MariaDB-log (Source distribution). started with:
Tcp port: 3306 Unix socket: /tmp/mysql.sock
Time Id Command Argument
Below you'll find slowquery we hacked apart with hex and unhex.
+------+-------------+------------+--------+---------------+---------+---------+---------------------------------+--------+---------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+------+-------------+------------+--------+---------------+---------+---------+---------------------------------+--------+---------------------------------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 719802 | Using where |
| 1 | PRIMARY | Subtree | eq_ref | PRIMARY | PRIMARY | 269 | const,x.SubtreeId,x.MaxRevision | 1 | |
| 2 | DERIVED | n | range | PRIMARY | PRIMARY | 269 | NULL | 959736 | Using where; Using index for group-by |
+------+-------------+------------+--------+---------------+---------+---------+---------------------------------+--------+---------------------------------------+
3 rows in set (0.008 sec)
When debugging these queries, one thing that is difficult for us is that inflight queries from show processlist contain binary data which doesn't copy/paste well. Would the trillian team be open to generating the queries in unhex form if the performance overhead isn't too high?
A final thing to note is that our sequencer config contains -sequencer_interval=20ms -num_sequencers=20 -batch_size=10000. Is the value sequencer_interval=20ms a good value for a 200M+ cert log? This same configuration on a larger log does not cause issues like this.
We deployed trillian commit 4831a21 this afternoon and since then have seen ~100 messages spaced 50s apart.
Sequencer failed to load sequenced batch: 1045204392378480099: Sequencer failed to dequeue leaves: Error 1205: Lock wait timeout exceeded; try restarting transaction"
Starting May 2nd on commit 07c5829 we began seeing the following with a sharp increase today.
failed to integrate batch for 1045204392378480099: 0e814fdb6d65b5e3: failed to fetch nodes: failed to get Merkle nodes: (invalid connection|context deadline exceeded|context canceled)
Our database connection string is
-mysql_uri=user:pass@tcp(mysql:3306)/db?readTimeout=28s&max_statement_time=25
@pgporada @rolandshoemaker Have you found a workaround for this?
If not, here is what should help. Each "tile" of the Merkle tree has potentially many revisions, hence the slow query in your comment. For log trees, only the last revision of each tile is used. So, you could run a one-time "garbage collection" removing from Subtree table with SubtreeRevision < MAX(SubtreeRevision).
We are discussing this internally, for storage savings purposes, but I think it should also make queries faster.
Please let me know if you are interested in doing this. I still need to double check whether this is safe, and no code uses earlier revisions of the tiles.
I was led to understand that, on an active log, there might be some revisions that are greater than the latest TreeRevision in the TreeHead table, while sequencing is happening? Those should be kept, as well.
We have not found a solution or workaround yet. I'm interested in the garbage collection step. I returned from paternity leave last week and have just now gotten back up to speed on that state of our CT logs.
@pgporada The fix #2568 should solve this to a large extent for newly created logs. It should limit the number of rows that the above query scans to 256. Not for already existing trees; for them a garbage collection is still needed.
@pgporada Which Trillian version are you currently running? Is it v1.4.0? For rolling out #2568 flawlessly it is recommended to be on v1.4.0 first (see comments in that pull request).
@pavelkalinnikov
We're running 4faa902f which is quite old now. Thanks for the heads up.
@pgporada The fix is now committed. It is hidden behind a flag now, we are going to try it gradually. In case you are interested in helping, I wonder if you could repeat your performance test like you did in comments above: https://github.com/google/trillian/issues/1188#issuecomment-492265617. Specifically, I think the monster query from https://github.com/google/trillian/issues/1188#issuecomment-492878267 should go away (on a new log).
I observe that the root tile is still written at every revision. Investigating.
Upd: I suspect that #2568 incorrectly handles flags. Flag parsing happens in main(), later than init. The current implementation is a no-op.
Upd: Fixed in #2755.
@pgporada The fix to reduce re-writing revisions has been released as the default behavior in v1.5.0. The now-deprecated flag --tree_ids_with_no_ephemeral_nodes controls the behavior, and it will be removed in a future release.
The Google CT team has been running with it in production without issue. Please let us know if you have any trouble adopting it.