trax
 trax copied to clipboard
trax copied to clipboard
Create a notebook explaining TransformerLM / Transformer
It would be great to have a nice notebook explaining TransformerLM and maybe even full Transformer in models/ -- both to explain the code and if possible with illustrations clarifying the concepts.
Wonderful. I'm on this. I'll post drafts here for team and community feedback.
I'm checking in with the first draft: https://colab.research.google.com/github/jalammar/jalammar.github.io/blob/master/notebooks/Trax_TransformerLM_Intro.ipynb
I still want to add two extra sections. One to go over the components of the Trax TransformerLM at a high level (tl.Serial and tl.Layers). I also want this section to give some intuition into the initialization parameters of TransformerLM (n_layers, d_model, d_ff, n_heads).
I'd love for the final section (or for a follow-up notebook) to be text generation (+training). I'm considering it to be character-level just to save energy and compute while introducing the concept of tokenization.
All feedback welcome!
Wow, I love this. I'm curious, what are you using to make those pics, especially the animated one?
Thanks! It's still an early draft.
I use Keynote. I'll upload the final Keynote file so people can later update it when necessary.
I'm currently looking at the reformer generation notebook and it's likely the best next step to point the reader. So I think I'll hold off from the generation section for now and focus conceptual illustration of TransformerLM as the final section in the notebook.
Checking in with the second draft. This version expands on the concepts of Trax layers, Serial, and Branch. It shows the parameters used creating a TransformerLM model. And ends with more advanced concepts such as the residual layer:
https://github.com/jalammar/jalammar.github.io/blob/master/notebooks/Trax_TransformerLM_Intro.ipynb
The "Transformer vs. TransformerLM" section could be supplemented with reasons of why to choose one vs. the other.
Once again, all feedback/corrections welcomed!
Side note: I really liked the advanced example for Branch in the docs. I couldn't fit it in the notebook, but I've created these illustrations for it:
For example, suppose Branch has three layers:
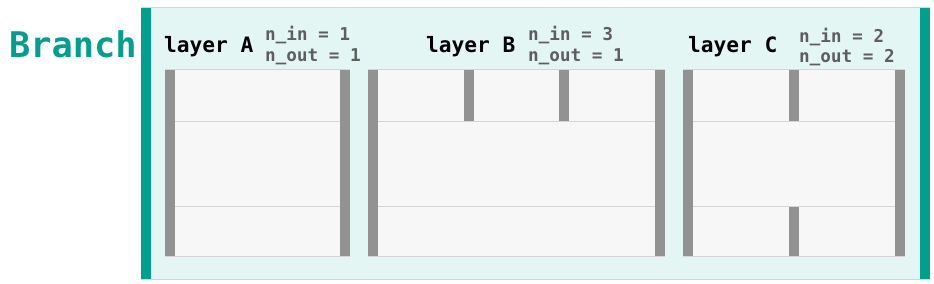
Then it will take three inputs:
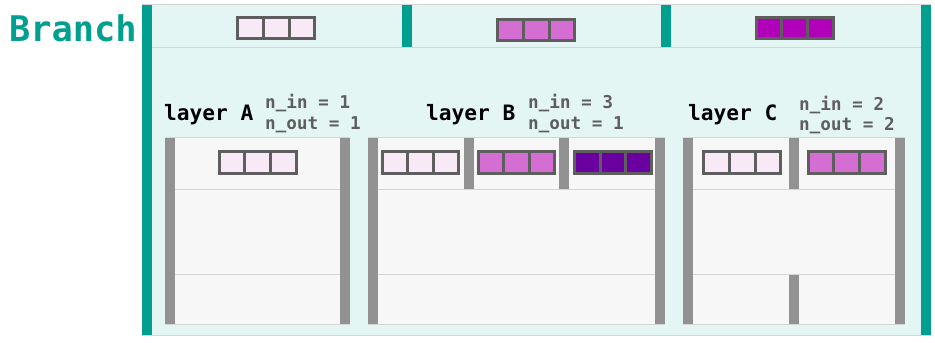
And it will give four outputs:
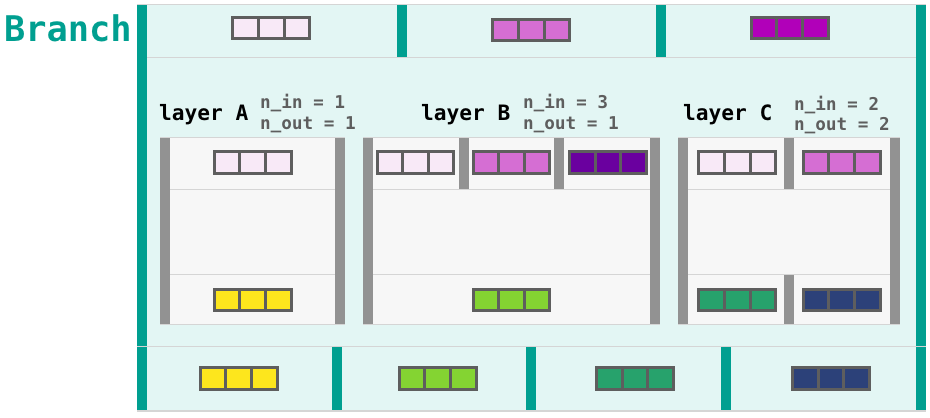
I also find myself intrigued with the data stack of the Serial combinator. There's room to explain its inner-workings visually as well.
@jalammar many thanks for this. It is very useful to me. Very well explained. ( i am a very newcomer here)
I have two silly doubts now
-
Data pipeline: at least for me it remains unclear how to do the data pipeline when a) Each instance it is a file itself (for example, using images) b) When I have a file, with all the data. (For example, a csv file where each row is a sentence)
-
In the prediction, this line of code keeps obscure to me predict_signature = trax.shapes.ShapeDtype((1,1), dtype=np.int32)
Thank you so much again :+1:
Thanks for your comments @facundodeza! Agreed that more examples on data pipeline would be a great addition to the docs. Noted on predict_signature. Thanks again!
Hi Jay. I'm starting to play with your notebook and really like it! As I dig in further, I can take notes and share them with you :-). Would you like that to happen in this thread, or does some other way work better for you?
Cheers, Jonni
Hi @jalammar,
Here are some first-pass suggestions/comments/context, focusing on the layers material later in the notebook. Use or don't use any of it as you see fit :-).
Typos and orthographic nits:
- "ReLu" --> "ReLU" when talking about the concept
- "ReLu" --> "Relu" when referring to the layer type in Trax
- "activaiton" --> "activation"
- "toegther" --> "together"
- "understaing" --> "understanding"
- "TranformerLM" --> "TransformerLM"
More concept-motivated suggestions:
-
"an input token has to go through a large array of computation and transformation ..."
--> "input tokens pass through many steps of transformation and computation ..."
[Idea/context: Once past the embedding layer, information from individual tokens gets blended by the network, and tokens cease to exist as individual, traceable things in the network.]
-
"At the very least, a layer must declare the number of input tensors and output tensors ..."
--> "Each layer you use or define takes a fixed number of input tensors and returns a fixed number of output tensors (n_in and n_out respectively, both of which ..."
[Idea/context: Explicitly declaring n_in and n_out for layers is not a common use case, but all users should have the model in mind of layers as functions, each with its own fixed n_in and n_out, and most with the default values n_in = n_out = 1.]
-
"which chains two layers toegther, and hands over the output of a layer to the following layer"
--> "which, in simple cases, chains two or more layers ..."
[Idea/context: When n_in = n_out = 1 for all layers inside a Serial layer, then the data flows as described -- output of one layer is the input to the following layer. This is a common use case and good for introducing what Serial does. Minor wording tweaks might keep the exposition simple yet leave the door open for more general/complex cases. That's the motivation behind suggesting "in simple cases" and "two or more".]
-
"It passes copies of the inputs it gets to its sublayers." [Branch]
--> "It supplies input copies to each of its sublayers."
[Idea/context: The Branch combinator can have different sublayers requiring different numbers of inputs. Branch accordingly takes as its inputs the maximum number required by any of its sublayers, and then gives each sublayer a copy of however many inputs that sublayer requires. It's a nonobvious pedagagogical choice how much of this fuller picture to expose at the current point in the notebook :-).
Graphics suggestion:
-
In illustrations for layers, consider moving the input and output values/vectors outside the visual box containing the layer proper.
[Idea/context: It's useful to think of / represent data as flowing between layers, hence placed outside of the visual blocks representing the layers. This helps in more complex cases, such as data flowing through multiple layers, especially when parallel flows and fuller data stack semantics are needed. As a specific example, in the Serial(Dense, Relu) diagram, this would replace the duplication of yellow data vector (output of Dense, input to Relu) with a single data vector in between the Dense and Relu visual blocks. This way is also consistent with the placement of data vectors in the Decoder diagrams near the end of the notebook.]
@j2i2 Thanks for the amazing feedback, Johni! I have incorporated all of your comments in the text of the latest version of the notebook. I'll update the graphics for Relu shortly as well. I do see your point about moving the inputs and outputs outside the visual box. It's why the input and output section are seperated by a faint line from the body of the layer. This choice was mainly to be able to show layers that expect two tensors. Sort of like the top part of concatenate:
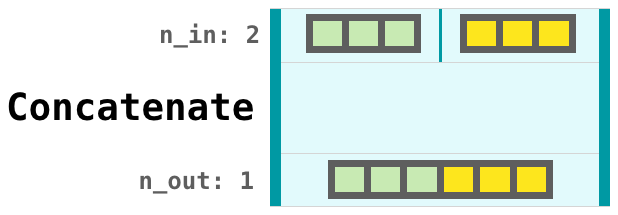
This especially factors in explaining Branch (like in the images above in this thread). With those ideas established, I do see the value of having the tensors outside for more advanced future concepts. What do you think?
Thank so much again for the great feedback! please let me know if there's anything else.
@jalammar Glad you found the feedback useful, Jay! I'll keep reading through and send more suggestions as they arise.
As for layer inputs and outputs, I tend to think of them as pipes/channels through which streams of data enter and exit the layers. Is there something graphical along those lines that appeals to you? You could keep the data graphics visually outside the layer, and the layer graphic itself would have an explicit indication of its input and output requirements -- like small nubs or pipe mouths, but cleaner to fit in the nice clean style of your layer graphics. (So the Concatenate graphic could have two visual indicators on top for its inputs and one on bottom for its single output.)
Cheers, Jonni
@jalammar Hi Jay,
Here are some further general comments/suggestions. Will look next at your specific data/training example.
Best, Jonni
Typos and orthographic nits:
- "fedback" --> "fed back"
- "challeneged" --> "challenged"
- "an decoder stack" --> "a decoder stack"
- "both of which default to 1." --> "both of which default to 1)."
- "compononet" --> "component"
More concept-motivated suggestions:
-
"by choosing the highest probability item as the next item in the sequence ..."
--> "by probabilistically choosing the next item in the sequence (often the highest probability one) ..."
[Idea/context: The text in the doc is accurate for the decoding used in this notebook (autoregressive with 0 temperature), but risks giving the reader the impression that this specific type of decoding is how language models work in general.]
-
"If we're to think of a simple model that takes the sequence 1, 2 and returns ..."
[Would this example be better for a full Transformer, which translates an input sequence to an output sequence? Could you put a simpler language model example here instead, e.g., decoding starting from nothing but a
symbol?] -
"Causal attention only allows the incorporation of previous tokens."
--> "Causal attention allows only the incorporation of information from nonfuture positions." [Or perhaps something a little less stiffly worded.]
[Idea/context: In causal attention, only the "future" positions are masked out, allowing attention to preceding positions as well as the current position. (Note also a preference for describing attention in terms of positions rather than tokens, since a given transformer position can blend/transmute information from many underlying tokens.)]
-
"The self-attention layer, for example, inside the Decoder Block has a residual connection around it:"
--> "Inside a Decoder Block, both the causal-attention layer and the feed-forward layer have residual connections around them:"
[Idea/context: Keep causal attention (used in decoders) distinct from full self attention (used in encoders). Also, good to mention/diagram the residual connection around the feed-forward layer, lest the reader mistakenly infer from the discussion/diagram that only the attention layer is part of a residual connection.]
Thanks @j2i2! Updated.
Also, good to mention/diagram the residual connection around the feed-forward layer
Good point. I'll add that to the graphic.
Would this example be better for a full Transformer, which translates an input sequence to an output sequence? Could you put a simpler language model example here instead, e.g., decoding starting from nothing but a symbol?
There's room for a full transformer graphic but not sure it belongs in this tutorial. Maybe if we expand the TransformerLM vs. Transformer section we can incorporate it. I'm all for making it simpler with an example of non-conditional generation first, totally.
@jalammar Cool; my comment on the TransformerLM example was more about the non-conditional generation ... agree about not complicating this tutorial with a full transformer graphic.
I spoke with Lukasz a little while back about this question, and he mentioned a nice example I think he had seen before, based on learning a Fibonacci sequence, or Fibonacci-like sequence. Would something like that appeal to you?
On a different note, the Trax library will be phasing out trax.supervised.trainerlib.* in favor of trax.supervised.training.*. In particular, you can replace trainerlib.Trainer with training.Loop. A relevant code sample is here.
Thanks again for your excellent work on this; I'll stay tuned for any further questions or discussion :-).
Wonderful. Fibonacci sounds great. Kinda like this?
Noted on Trainer => Loop. I'll update the code accordingly. I noticed the transition so I didn't feature Trainer in the visuals prominently. Thanks for listing the example!
Yes; with the possible tweak of a different starting value, such as:
- input 10, output 16, (copy 16 to input), output 26, (copy 26 to input), output 42, ...
which would help distinguish what the network is doing from other interpretations, e.g.,
- the network isn't just creating an arithmetic sequence (1, 2, 3, ...)
- the network didn't just memorize the actual Fibonacci sequence :-)
@j2i2 Wonderful! Checking in with the updated version here: https://github.com/jalammar/jalammar.github.io/blob/master/notebooks/Trax_TransformerLM_Intro.ipynb
- The animation now shows the Fibonacci sequence starting from 3 (seen below)
- Added an illustration showing the residual connection around the feedforward network (seen below)
- The code example now uses Loop instead of Trainer.
- Associated with the Trainer => Loop change, the input sequence is now packaged into an input Task and an evaluation Task.
- I have uploaded the Keynote file containing all the illustrations and animation here so they can be extended in the future as needed.
Animation:
![]()
Residual:
![]()
@jalammar hi jalammar, i'm glad to see you here.
i am reading your blog and trax code to know about transformer, both are excellent.
But I seem to have a problem. Your blog and the trax code are somewhat inconsistent in the description of Multi Head Attention.
Yours:

Trax code:
 the x in above trax code is Q or K or V, it is x only rerange and not like in your blog.
the x in above trax code is Q or K or V, it is x only rerange and not like in your blog.
can you tell me why is it?