site-kit-wp
 site-kit-wp copied to clipboard
site-kit-wp copied to clipboard
Introduce cyclomatic complexity lint rule to warn about overly nested code.
Feature Description
Anecdotally it feels like our code can get a bit overly complex and deeply nested at times. It would be interesting to introduce the complexity linting rule to warn if the code is nested beyond a certain depth, which could help inform potential refactors to simplify matters.
Do not alter or remove anything below. The following sections will be managed by moderators only.
Acceptance criteria
Implement the rule
- The ESLint complexity rule should be introduced to our linting rules.
- The complexity threshold should be kept at the default of 20. The level for the rule should be
error. - Any functions which are currently over the threshold should have the rule disabled to avoid linting errors.
Create the next issues
Once we've got the initial rule in place, the intention is to follow up to a) refactor functions to avoid disabling the rule, and b) iterate further, to reduce the threshold from its default of 20.
- An issue should be created for each of the functions that had the rule disabled to refactor it to a complexity within the current threshold.
- An followup issue should be created to reduce the complexity threshold, once again disabling the rule for functions above the threshold and creating further follow-up issues to refactor them.
Implementation Brief
- Check out the attached PR with the lint rule updated locally
In .eslintrc.json:
-
Add the
complexityrule to the rules object, and set it to throw an error, with the threshold set to 20. -
Run
npm lintto get a full list of code currently violating the lint rule -
Create issues for each of the violations
-
Go over the flagged files, and ignore the rule for each occurence.
- Remember to specify the
complexityrule in the ignore-comments so that other errors still get flagged (eslint-disable-next-line complexityinstead of justeslint-disable-next-line).
- Remember to specify the
Test Coverage
- No tests need to be created or updated for this issue.
QA Brief
Changelog entry
This is a nice addition that will help to improve some code quality. However my concern is that it will require a lot of refactoring of existing functions, especially those which are functional components. @techanvil do you know whether we can ignore functional components from being analysed by this rule?
Hi @eugene-manuilov, I am not aware of any out-of-the-box or trivial way to blanket exclude this rule for functional components.
The approach I would take here would be to introduce the rule at a suitable level of complexity, and manually disable it for the existing functions which go over the level, with the idea that they are candidates to refactor as time goes on.
For example, introducing at the default level of 20 would mean we'd only need to disable the rule for 9 functions (at the time of writing):
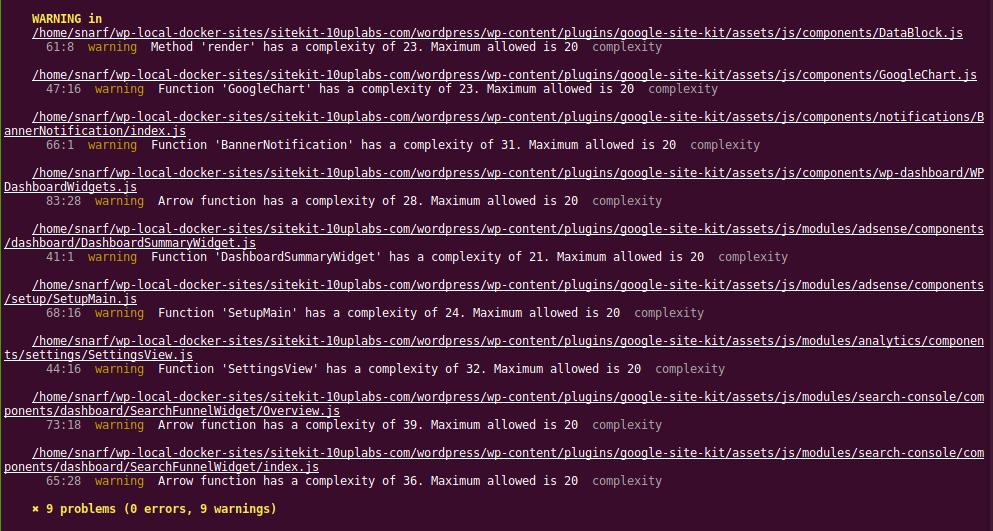
However, 20 is arguably still quite a high value. Dropping it to 10 results in 59 warnings. Maybe somewhere in the middle would be appropriate for our codebase, considering what we are used to, or maybe we should aim reasonably low for future code. It might be worth discussing in a standup or maybe a poll on Slack?
@techanvil I would be open to starting with the default level of 20 and the handful of ignores you listed. From there I think we could open a few follow-up issues to 1) refactor the ignored components to no longer be ignored and 2) reducing the threshold level to something we feel is more optimal (in the future). We can figure out what that level is by reducing it and seeing how many functions need updating and using that as a way to batch updates until we get to a level where we're satisfied with (it may take a few rounds depending on what we want and how many updates it will take). That may not work all the way, but sounds like it would work for starters. Thoughts?
Hey @aaemnnosttv, that sounds like a sensible approach to me, there's no obvious "right" value at present so iterating on it as you suggest seems like it would allow us to determine the correct value for our needs in a measured way.
@techanvil would you please add ACs for this one when you get a moment? I think the approach we discussed above would be a great place to start 👍
Thanks @aaemnnosttv, I have added ACs for this one, please take a look. Cc @felixarntz
@techanvil LGTM although let's also require that issue(s) are opened to address the areas where we've disabled the rule so these are not left ignored. Depending on the scope, this could be a single issue or perhaps one for each area or component. We don't have to open that issue now, but it could be part of the AC that the follow-up(s) are also defined.
It would also be nice to see a follow-up issue for this one to lower the threshold (and address violations) as a next step. What do you think?
@techanvil LGTM although let's also require that issue(s) are opened to address the areas where we've disabled the rule so these are not left ignored. Depending on the scope, this could be a single issue or perhaps one for each area or component. We don't have to open that issue now, but it could be part of the AC that the follow-up(s) are also defined.
It would also be nice to see a follow-up issue for this one to lower the threshold (and address violations) as a next step. What do you think?
Hey @aaemnnosttv, this is a good shout. One detail that occurs to me is, if we are going to a) refactor the functions that are over the threshold, and b) follow up with a reduction to the threshold, it could be prudent to identify the follow-up threshold (or a reasonable guess at it) and then refactor the functions to this threshold rather than the default of 20, to save refactoring them twice.
Does this sound sensible to you, or maybe it's an over-complicated approach? I've updated the AC with this approach in mind but would be happy to amend it...
One detail that occurs to me is, if we are going to a) refactor the functions that are over the threshold, and b) follow up with a reduction to the threshold, it could be prudent to identify the follow-up threshold (or a reasonable guess at it) and then refactor the functions to this threshold rather than the default of 20, to save refactoring them twice.
@techanvil I think my assumption is that whatever we do to address the high level of complexity in the refactoring would likely reduce the level below 20 rather than to 20. I'm also assuming that post-refactor the same functions would likely not be flagged again. If they were then we'd might be looking to solidify our target level. I'm not sure if we can see the complexity level of specific functions to proactively reduce them to a level which is not yet enforced. I suppose maybe this is possible with a file-level comment override or something but I'd rather not do that.
As far as this issue is concerned though, let's avoid trying to foresee what the future requirements will be too much and instead make sure we have the necessary issues in place for the next steps here, we can always add/remove/change them as they're further defined.
Thanks @aaemnnosttv, that makes sense. I have updated the AC to remove the attempt to identify the followup threshold.
@makiost Can you mention any ESLint packages and/or the rule(s) needed to be enabled in the IB? And can you fill out the test section? I guess we won't need any tests, but if that's the case it's good to mention it in the IB 🙂
I think part of the IB here should also be to create the issues for each rule violation/ignored linting instance.
If there are some that are very related (by type or by file) it's fine to group them, but the ACs here mention creating the issue, so that should be added to the IB. That probably makes this issue more like a 7 estimate to be safe, as it requires creating 5-10 issues.
QA:Eng Verified ✅
- Verified the
npm run lint:jsscript doesn't return any errors. - Verified removing the
// eslint-disable-next-line complexitylines locally and running thenpm run lint:jsshows the error.