jax

jax copied to clipboard
Move GPU computation dispatch into a separate thread.
On GPU we dispatch XLA computations synchronously inline on the main Python thread. Frequently we find that GPU computation dispatch is slow and can take time comparable to the execution time of a step on device. For example, consider the following T5X model step on V100 GPU:
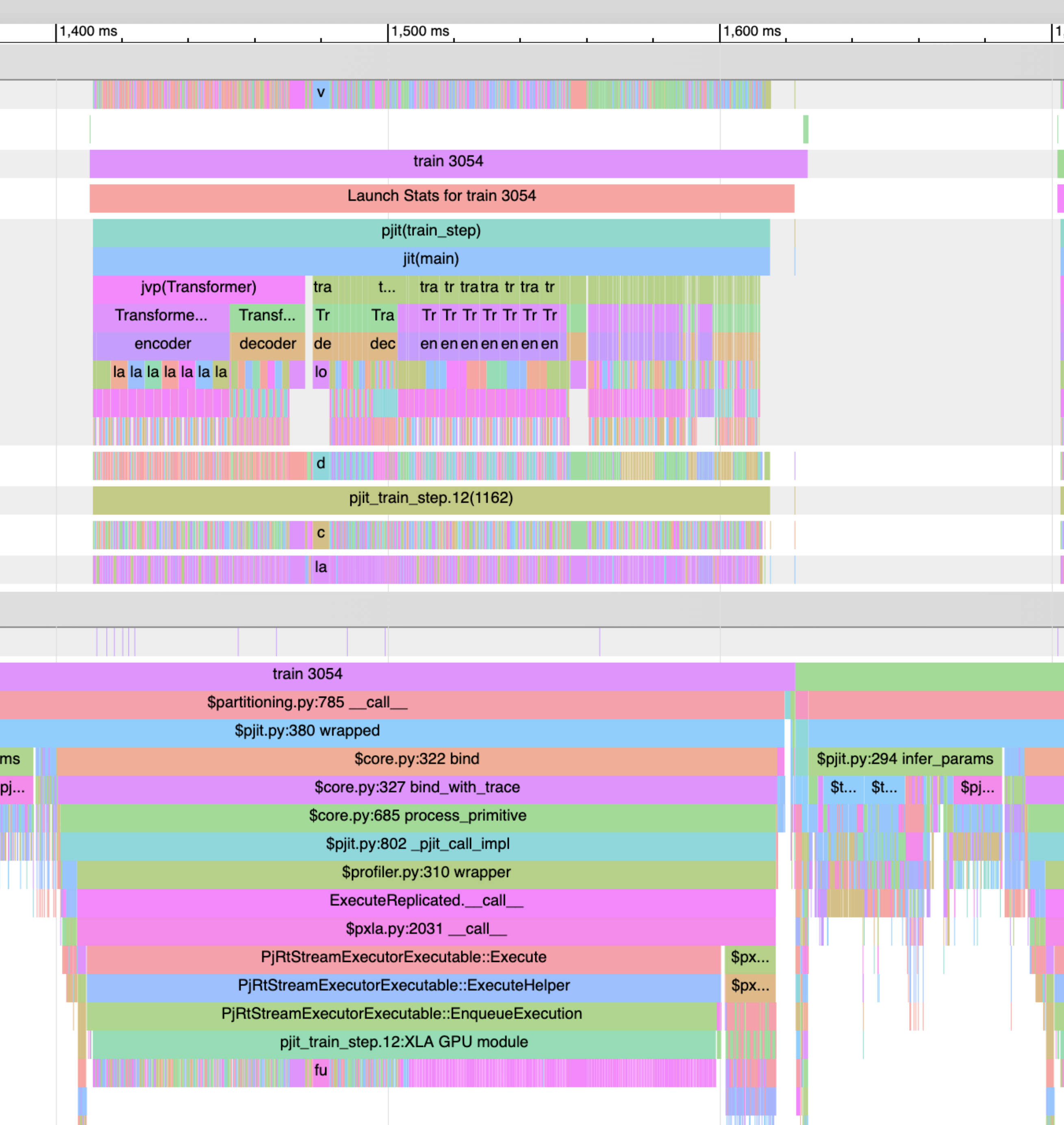
If we were to change PJRT to move the work of dispatching the XLA:GPU kernels onto a subthread, we could unblock the main Python thread to allow it to enqueue more work.
A few observations:
- We must preserve ordering between computations, so a worker thread that processes computations in FIFO order would work.
- We may want to avoid the thread hop for trivial computations, although the time for a thread hop is comparable to a single GPU kernel dispatch (a handful of microseconds) so presumably it doesn't matter a whole lot.
- We would need to do any allocation on the main thread, together with any buffer definition event tracking for the buffers produced by a computation.