gvisor
 gvisor copied to clipboard
gvisor copied to clipboard
tmpfs: populate memory in fallocate to avoid page faults when read/write
For linux implementation, when we call fallocate to tmpfs, the linux kernel will allocate physical pages directly.
For earlier gvisor implementation, when we call fallocate to tmpfs, the gvisor kernel only ftruncate and mmap memory region. This will cause page fault for each page read/write in tmpfs, which hurts the performance.
So to keep consistent with linux as well as improve read/write performance, we use mmap(MAP_POPULATE) to populate (prefault) page tables for mapping.
Signed-off-by: Chen Hui [email protected]
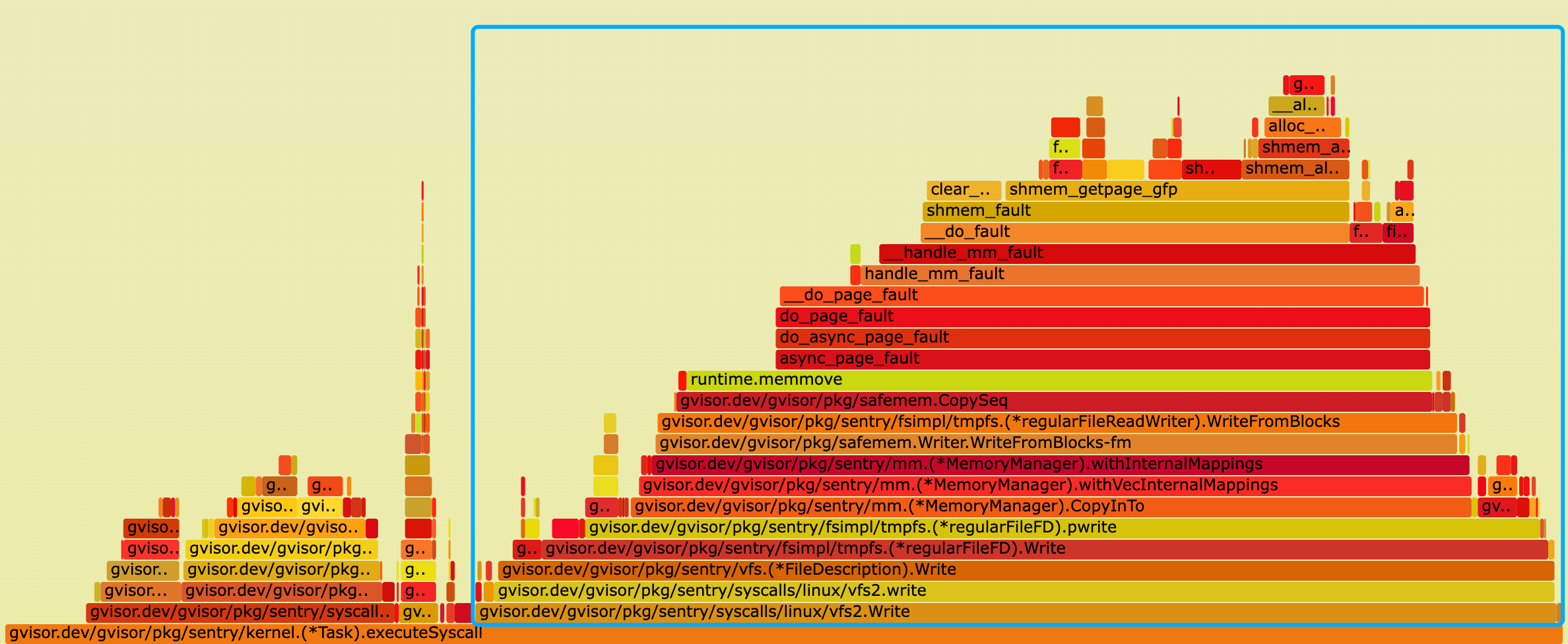
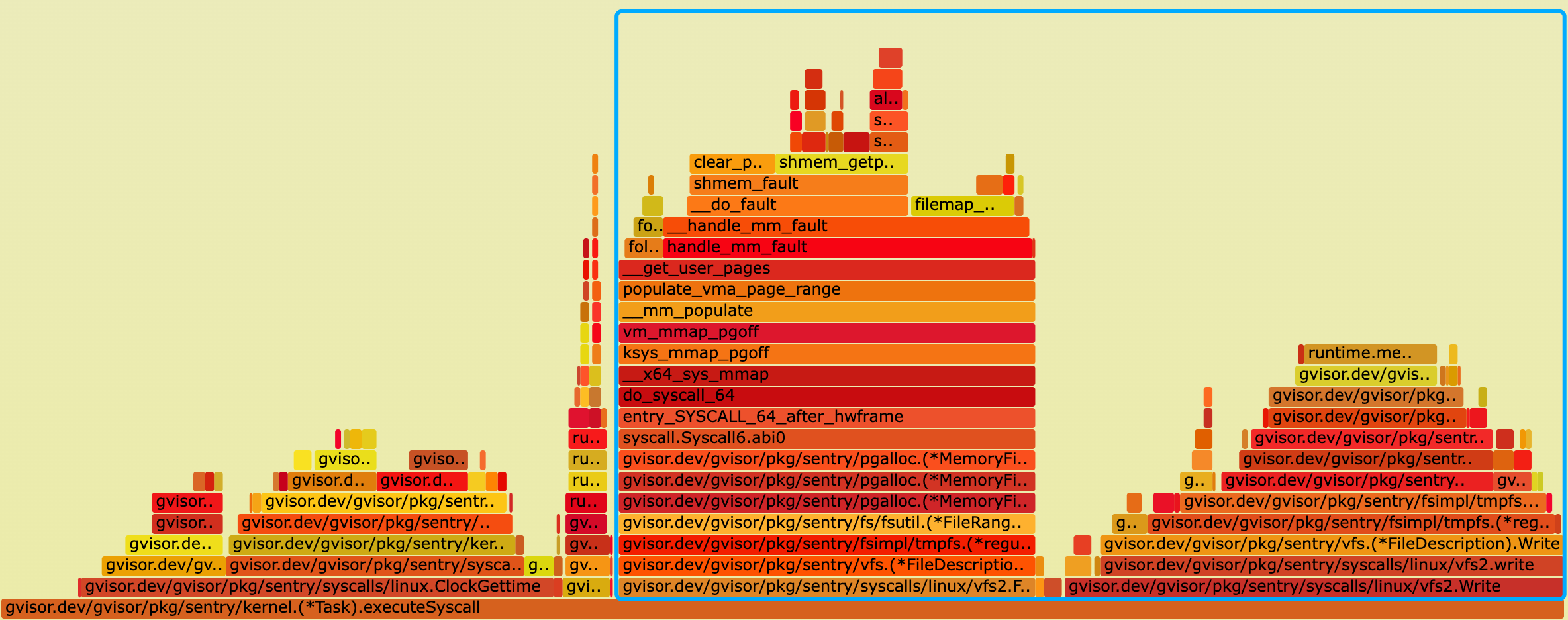
Thanks for your contribution, flame graph looks great. Can you tell the % CPU time reduction in the sentry?
@ayushr2 Sure.
- From the flame graph, the cpu time of sentry reduce from 54.62% to 53.08%, improved by 1.54%.
- From the fio tmpfs benchmark, the bw increase from 35701 to 36591, improved by 2.4%.
id=$(docker run -d --runtime=ptrace --mount type=tmpfs,destination=/data gvisor.dev/images/benchmarks/fio sleep 10000000)
docker exec -ti $id fio --output-format=json --ioengine=sync --name=write --size=10G --blocksize=4K --filename=/data/data.test --iodepth=4 --rw=write
Looks not not very huge improvement. But it's mainly because the heavy overhead of ptrace context switch. Assume https://github.com/google/gvisor/pull/7975 is merged, the the fio tmpfs bw will improve 11% with this patch.
Looks not not very huge improvement. But it's mainly because the heavy overhead of ptrace context switch.
Makes sense, for benchmarking I try to use the KVM platform on bare metal (not inside a VM already). KVM has much lesser overhead that ptrace. Benchmarking with ptrace is often very noisy.
Just a heads up on this change.
-
Any changes to seccomp filters need someone with security review permissions to review. I think we can do this on the gVisor team, but heads up regardless.
-
Any concerns on this significantly growing the memory footprint of sandboxes? Does MAP_POPULATE mean we allocate memory immediatly despite it being touched? We have some reviewers more familiar with this than I, but that's discussion. Any thoughts on this?
Any concerns on this significantly growing the memory footprint of sandboxes? Does MAP_POPULATE mean we allocate memory immediatly despite it being touched? We have some reviewers more familiar with this than I, but that's discussion. Any thoughts on this?
From my understanding, this is consistent with what Linux does. Allocations in tmpfs actually allocate host pages and populate the page tables. When the application calls fallocate(2), it does expect the backing pages to be allocated. From the man page of fallocate(2):
fallocate is used to manipulate the allocated disk space for a file, either to deallocate or preallocate it.
The other cases in which pages will be preallocated for tmpfs is:
- write(2). In this case the pages are anyways going to be touched so preallocation does not make a difference.
- page fault via
Mappable.Translate. In this case too, the application is touching this file range and so preallocation is not bad.
This preallocation helps avoid the repeated page faults.
I just took a cursory glance and had one thought: if populate is set then we could also proactively update the usage set. Then again, I don’t think it causes any issues either way, so it may make more sense to leave this (effectively deferring to when someone calls the relevant update function, which may never happen at all).
Anyway, let's summarize.
Pros of this patch:
- keep consistent with linux kernel behavior, as also mentioned by ayushr2
- improve the performance of tmpfs write after fallocate (for fio benchmark in kvm platform, the bw increase from 304005 to 442810, improved by 45.65%)
id=$(docker run -d --runtime=kvm --mount type=tmpfs,destination=/data gvisor.dev/images/benchmarks/fio sleep 10000000) docker exec -ti $id fio --output-format=json --ioengine=sync --name=write --size=10G --blocksize=4K -- filename=/data/data.test --iodepth=4 --rw=write
Cons of this patch:
- will increase the memory footprint (RSS) after fallocate, which is also the same as linux
- will increase the memory footprint (RSS) after fallocate, which is also the same as linux
pgalloc.FileMem maps 1 GB (= chunkSize) regions of the memfd into its own address space at a time; this amortizes the cost of mmapping over a large number of mapped pages, reduces the number of VMAs the sentry creates on the host (with smaller chunkSizes we have had problems with hitting vm.max_map_count, the Linux limit on the number of VMAs per process), and supports the usually-cache-dirty-free mapping-reuse pattern seen in MemoryFile.forEachMappingSlice(). The implications of this for this CL are:
-
The optimization won't always work: if a sentry mapping already exists for the chunk containing a new tmpfs allocation (due to reuse of deallocated memory), host
mmapwill not be called again. I think this is ok since it's just an optimization. -
A 1-byte tmpfs file, rounded up to a 1-page
pgalloc.MemoryFileallocation, canMAP_POPULATE1 GB of memory. This is going to be an unacceptable OOM risk.
I don't know of any syscall that will achieve the effect of MAP_POPULATE on an existing range of mappings, which I think is what we really want here.
A 1-byte tmpfs file, rounded up to a 1-page pgalloc.MemoryFile allocation, can MAP_POPULATE 1 GB of memory. This is going to be an unacceptable OOM risk.
@nixprime I see, it is a problem.
How about we populate when the whole new chunk can be wrapped by file range?
diff --git a/pkg/sentry/pgalloc/pgalloc.go b/pkg/sentry/pgalloc/pgalloc.go
index 7e4692204..2359febdb 100644
--- a/pkg/sentry/pgalloc/pgalloc.go
+++ b/pkg/sentry/pgalloc/pgalloc.go
@@ -761,7 +761,8 @@ func (f *MemoryFile) forEachMappingSlice(fr memmap.FileRange, populate bool, fn
m := atomic.LoadUintptr(&mappings[chunk])
if m == 0 {
var err error
- mappings, m, err = f.getChunkMapping(chunk, populate)
+ // Populate when the whole new chunk can be wrapped by file range.
+ mappings, m, err = f.getChunkMapping(chunk, populate && (chunkStart+chunkSize < fr.End))
if err != nil {
return err
}
I think that does solve the memory usage blowup problem, but at the cost of making the optimization very narrowly applicable (almost exclusively to tmpfs fallocate(>= 1 GB)). Can you test if #8003 also solves this performance problem in your application?
I think that does solve the memory usage blowup problem, but at the cost of making the optimization very narrowly applicable (almost exclusively to tmpfs fallocate(>= 1 GB)). Can you test if #8003 also solves this performance problem in your application?
@nixprime The performance is pretty good. I like the idea of mlock and munlock, while my only concern is if the RLIMIT_MEMLOCK setting has bad influence, like security issue?
Hi @ayushr2 @nixprime , any conclusions about this pr and https://github.com/google/gvisor/pull/8003? I will be ok if either get merged.
As https://github.com/google/gvisor/pull/8003 is merged, this pr can be closed.