How can we ensure 100% uptime?
We have faced issues during k8s upgrade in past and then I believe upgrading Postgresql schema would require a downtime. So how can we ensure 100% uptime of registry?
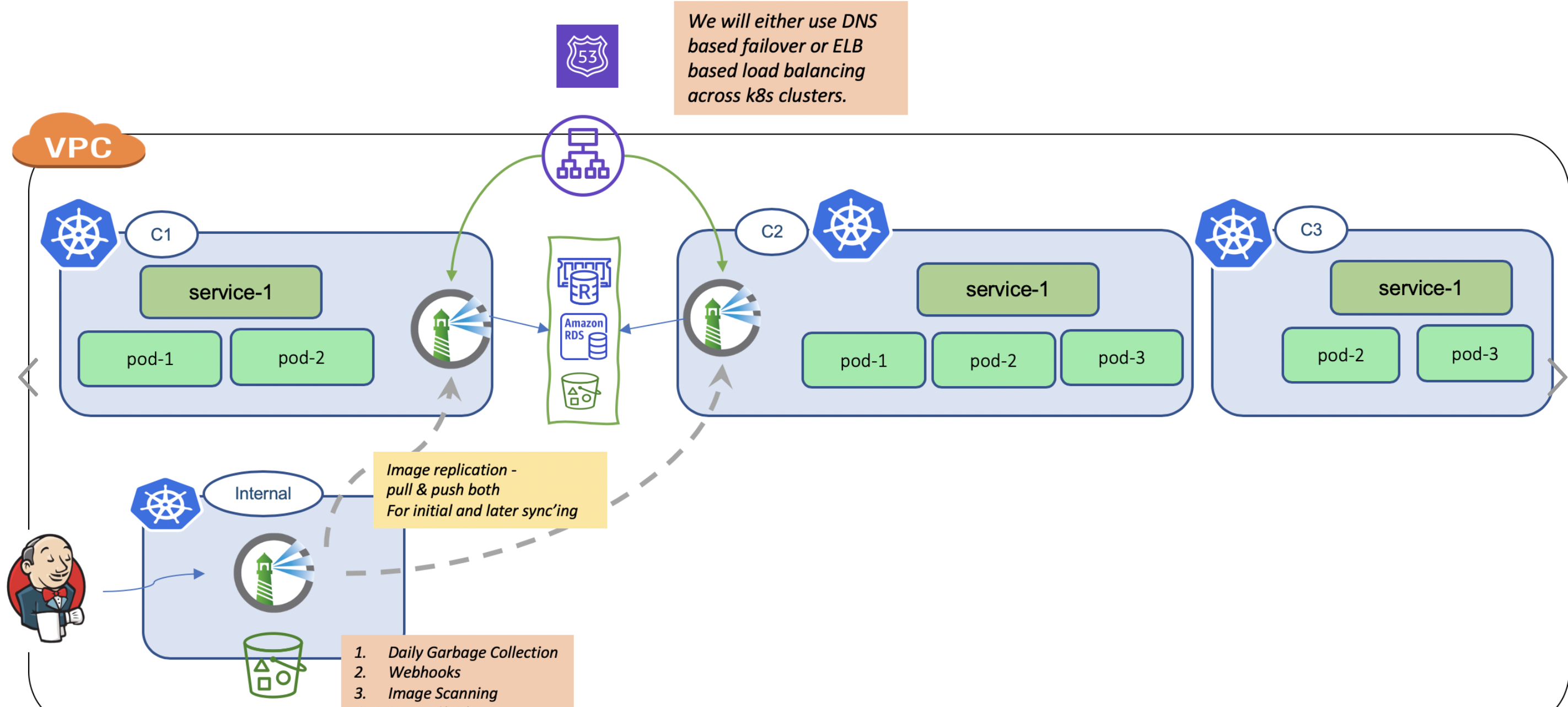
How about a redundant k8s cluster hosting a copy of harbor and make this point back to the same S3? Can this redundant harbor share the same rds/postgresql and redis?
Do you recommend running harbor on same k8s as we host our microservices?
Maybe I can add redundant harbor instance on another k8s and use replication to keep them in sync?
Considering Harbor's HA Deployment (ie. with external postgres & redis), which of the below deployment models would make most sense?
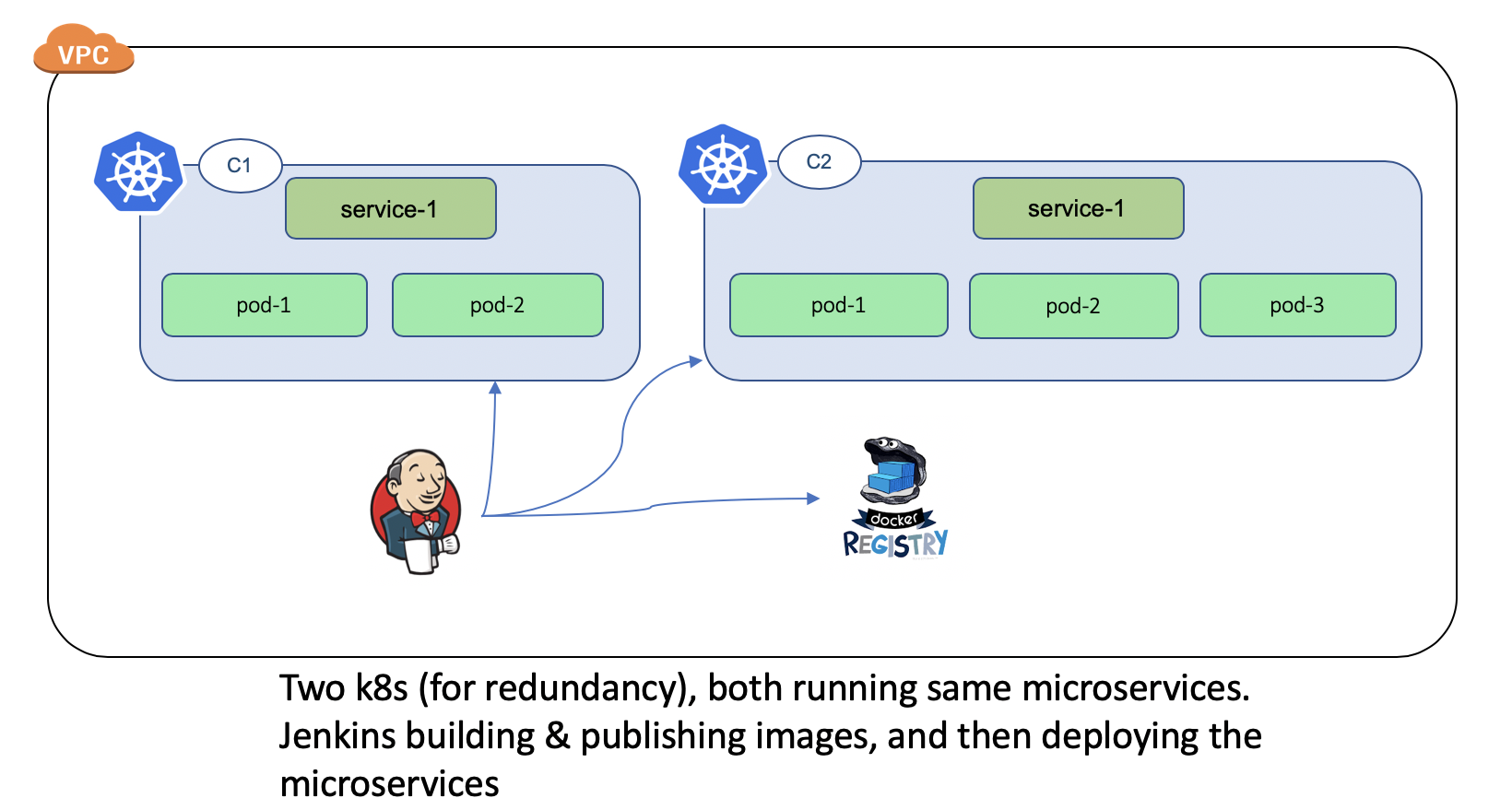
Current Deployment Model
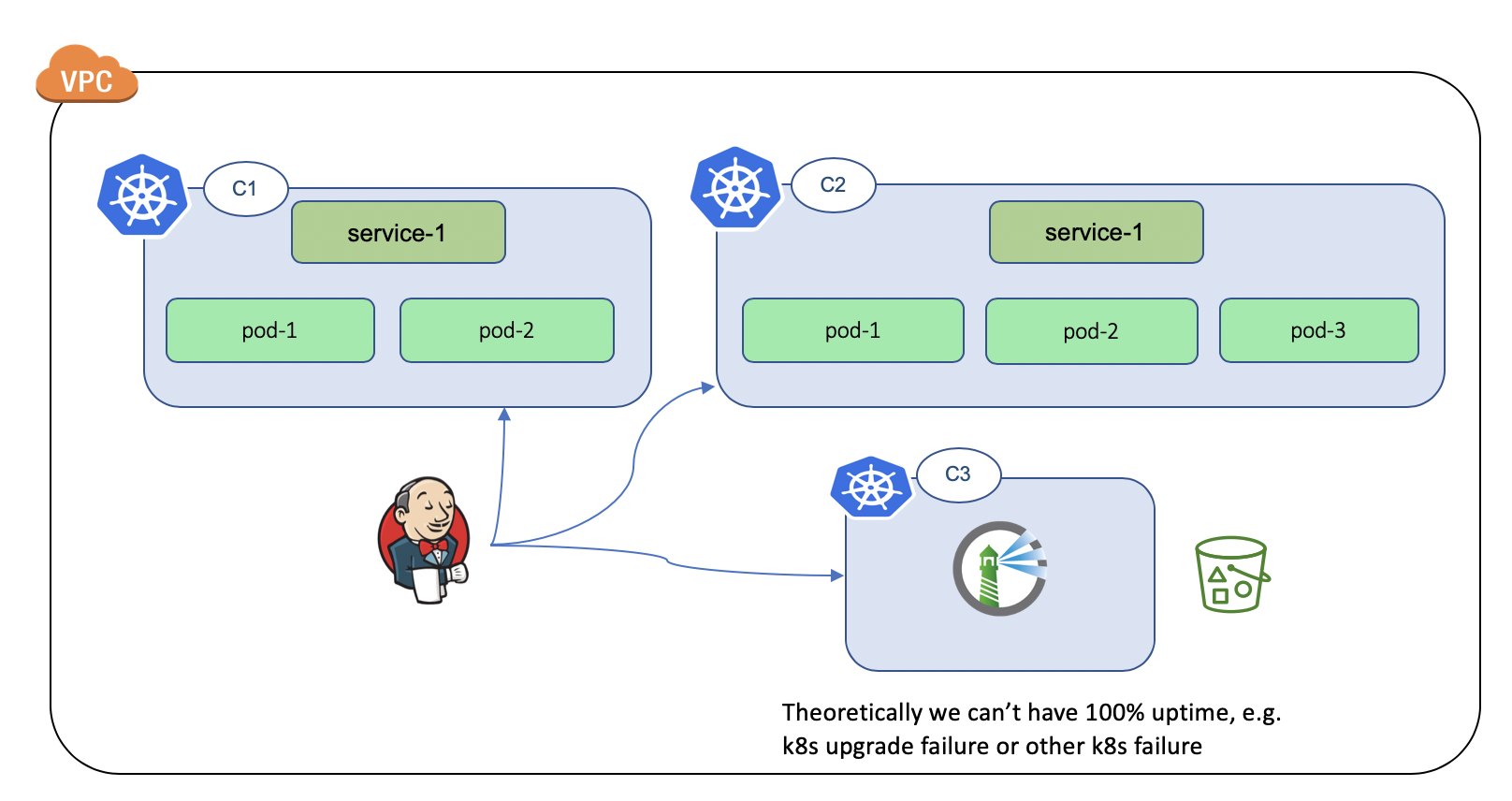
Option-1: Dedicated k8s for harbor
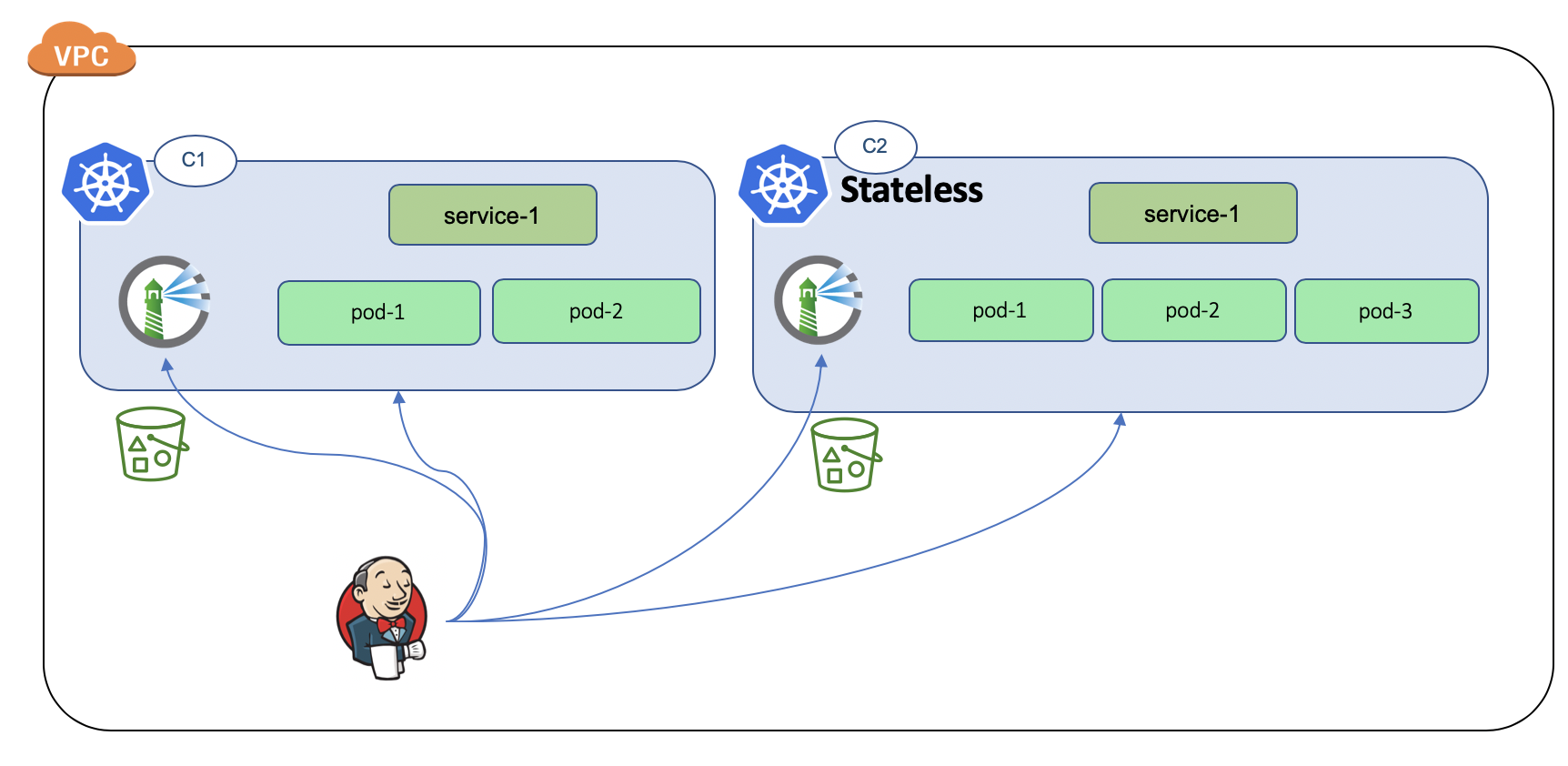
Option-2: Harbor sharing k8s with other production workloads.
Option-3: Readonly Harbor instances sharing k8s with other production workloads
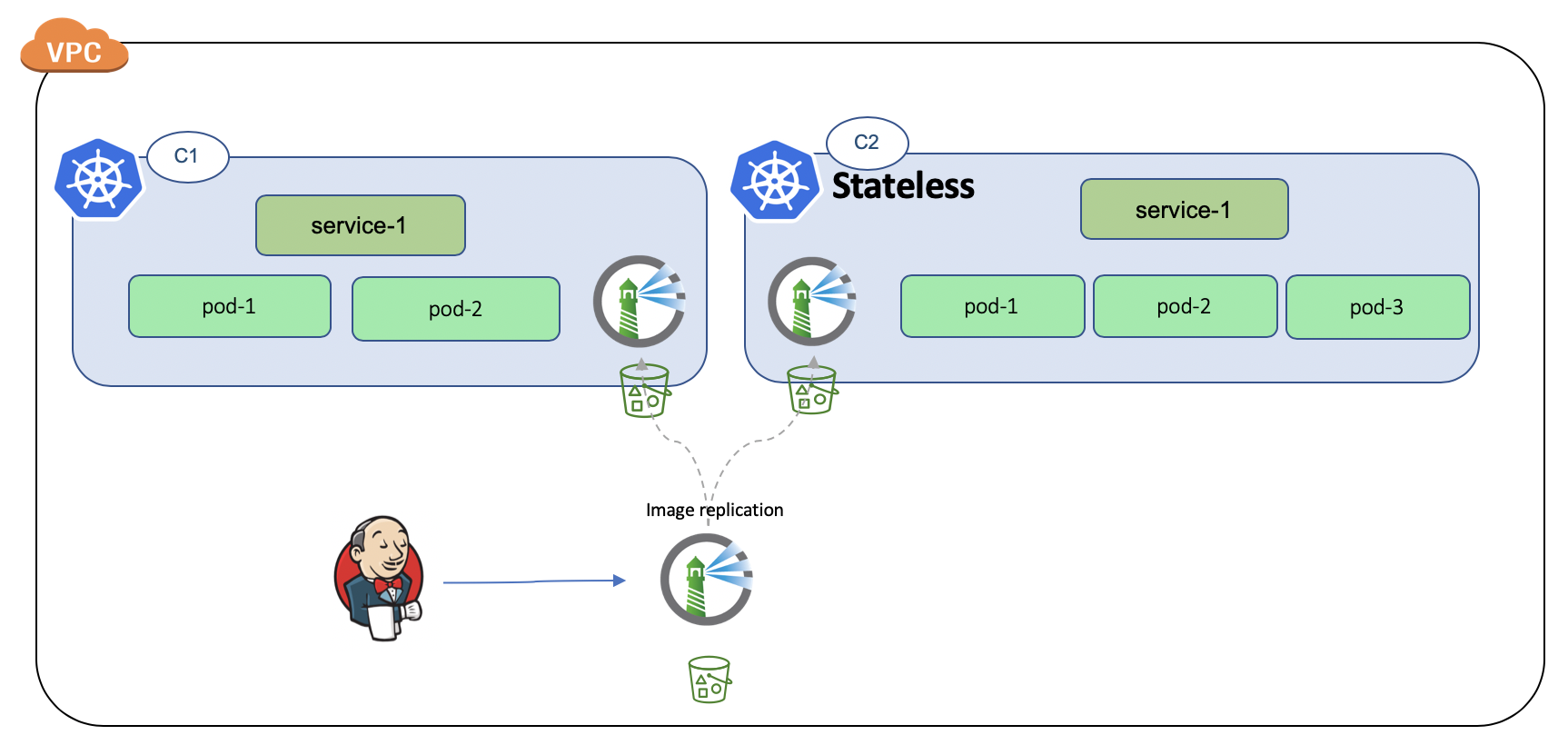
Question: Can multiple harbor instances in the same region or AZ share the S3 bucket? Can there be any write conflicts?
@hainingzhang this definitely requires some attention. what's your thought on this?
@bjethwan
By 100% uptime, we have to clarify what's the expectation.
given we can’t ensure backward compatibility of the schema, and upgrading schema requires downtime, we need to be clear what data change happened on slave Harbor must be visible on master after master finish the upgrade.