leela-chess
 leela-chess copied to clipboard
leela-chess copied to clipboard
Analyze blunders
Important!
When reporting positions to analyze, please use the following form. It makes it easier to see what's problematic with the position:
- Id: Optional unique ID. Come up with something. :) number/word, just to make it easier to refer this position in further comments.
- Game: Preferably link to lichess.org (use lichess.org/paste), or at least PGN text.
- Bad move: Bad move with number, and optionally stockfish eval for that move
- Correct move: Good move to play, optionally with stockfish eval
- Screenshot: optional, screenshot of the position, pasted right into the message (not as link!). Helps grasping the problem without following links
-
Configuration: Configuration used, including
lc0/lczeroversion, operating system, and non-default parameters (number of threads, batch size, fpu reduction, etc). - Network ID: Network ID, very important
- Time control: Time control used, and if known how much time/nodes was spent thinking this move
- Comments: any comments that you may have, e.g. free word explanation what's happening in position.
(old text below)
There are many reports on forums asking about blunders, and the answers so far had been something along the lines "it's fine, it will learn eventually, we don't know exactly why it happens".
I think at this point it makes sense to actually look into them to confirm that there no some blind spots in training. For that we need to:
- Open position in engine and check counters
- Try several times to evaluate that move with training configuration "800 playouts, with Dirichlet noise and temperature (
--temperature=1.0 --noise)" to see how training data would look like for this position.
Eventually all of this would be nice to have as a single command, but we can start manually.
For lc0, that can be done this way: --verbose-move-stats -t 1 --minibatch-size=1 --no-smart-pruning (unless you want to debug specifically with other settings).
Then run UCI interface, do command:
position startpos moves e2e4 ....
(PGN move to UCI notation can be converted using pgn-extract -Wuci)
Then do:
go nodes 10
see results, add some more nodes by running:
go nodes 20
go nodes 100
go nodes 800
go nodes 5000
go nodes 10000
and so on
And look how counters change.
Counters:
e2e4 N: 329 (+ 4) (V: -12.34%) (P:38.12%) (Q: -0.2325) (U: 0.2394) (Q+U: 0.0069)
^ ^ ^ ^ ^ ^ ^ ^
| | | | | | | Q+U, see below
| | | | | | U from PUCT formula,
| | | | | | see below.
| | | | | Average value of V in a subtree
| | | | Probability of this move, from NN, but if Dirichlet
| | | | node is on, it's also added here, 0%..100%
| | | Expected outcome for this position, directly from NN, -100%..100%
| | How many visits are processed by other threads when this is printed.
| Number of visits. The move with maximum visits is chosen for play.
Move
* U = P * Cpuct * sqrt(sum of N of all moves) / (N + 1)
CPuct is a search parameter, can be changed with a command line flag.
* The move with largest Q+U will be visited next
Help wanted:
- Feel free to post positions that you think need analyzing (don't forget to also mention network Id used, and also all other settings are nice to know)
- Feel free to analyze what other people posted
https://lichess.org/e07JvP6g - I started analyzing this - the position after the blunder has a 0.11% policy for a move which is checkmate. Takes 20k visits to get its first look and then it obviously gets every visit. I haven't tested how that varies with noise applied.
Here's an easy one ply discovered attack tactic missed by Leela after 2K5 nodes. Position: https://lichess.org/mbWjiT93#105 Twitch recording of the thinking time/engine output: https://clips.twitch.tv/GenerousSmellyEggnogPunchTrees And as the lichess analysis says, this was "merely" the cherry on top of the multiple-mistakes cake. How to swing 15 points' eval in just 3 moves!
Further analysis requested please. How many playouts until Leela even once searches the tactic?
Edit: Tilps' position is also a discovery bug, I think Leela's policy assumes that the rook can just capture the queen, which is of course prevented by the pin = discovered attack
@mooskagh thanks for diagram.
If i wrong please correct me.
Leela's brain gets power from memorized games and positional samples she collected in self play and we call it visits.I see she has visits comes from weights instead of alfa-beta pruning.If there is a tactical opportunity in the position but leela visits an other move much she choose it.
In basic tactical positions occurs suddenly in the game and the hardest part is to teach her this. Is it necessary to play billions of games in order to learn the tactical motifs that occur during the game?
Or can you add a simple tactical search algorithm triggers on every move working independently from visits for a while.After she find tactical move with tactical search algorithm(looks for suddenly jumps to +1 +2 etc) and enter this move tree she can collect this sample to her brain too.With this way she learn playing tactically in short time and tune herself automatically.
e2e4 N: 329 (+ 4) (V: -12.34%) (P:38.12%) (Q: -0.2325) (U: 0.2394) (Q+U: 0.0069)
^ ^ ^ ^ ^ ^ ^ ^
| | | | | | | Q+U, see below
| | | | | | U from PUCT formula,
| | | | | | see below.
| | | | | Average value of V in a subtree
| | | | Probability of this move, from NN, but if Dirichlet
| | | | node is on, it's also added here, 0%..100%
| | | Expected outcome for this position, directly from NN, -100%..100%
| | How many visits are processed by other threads when this is printed.
| Number of visits. The move with maximum visits is chosen for play.
Move
* U = P * Cpuct * sqrt(sum of N of all moves) / (N + 1)
CPuct is a search parameter, can be changed with a command line flag.
* The move with largest Q+U will be visited next
I am stating the obvious, but I think that brute force engines like Stockfish and Houdini have the advantage that their evaluation is cheap, and they can search very deep, thus having great tactics.
Leela's evaluation is very expensive, and thus she cannot search deep enough to avoid blunders. I sense that if one could speed up her evaluation, so she could search deeper, her blunders would be greatly reduced.
On an Nvidia Titan V, where Leela cudnn can evaluate 8000 nodes per second, she did not seem to blunder, and even won several games against Stockfish, Komodo and Houdini: https://groups.google.com/forum/#!topic/lczero/YFMOPQ-J-q4
I recall that alpha zero evaluated around 100000 nodes per second on the deep mind supercomputer, which greatly improves its tactics. This begs the question: what nps did alpha zero use during its training process? I suspect the number of nps can greatly affect the quality of the games during Leela's training. If the cudnn version of Leela can be used for training, the quality and speed of training will likely be increased drastically.
I've added a form for problematic positions submission into the original message. Sorry for bureaucracy, but that makes it much easier to see the problem.
@chara1ampos : The DM paper says "During training, each MCTS used 800 simulations.", which is a bit ambiguous and may read as new playouts added to the tree or as visits for selected node. Thus nps is irrelevant (but for the total training time). 800 'simulations' is anyway far below 10K's of simulations you mention for match games. So, yes, AZC training may have included blunders as well, at least in early stages (like where we stand now).
- ID: 0001
- Game: https://lichess.org/FI3y76b0
- Bad move: 22. Ng4 (and 21. Rxg8+ wasn't optimal either IMHO)
- Correct move: 22. Nf1
- Screenshot:

- Configuration: Game: LCZero cuDNN 20180508 ID 263 vs Stockfish 9 18050811 Lvl 20 GUI: Arena 3.5.1 Settings: Threads/Cores: 4, Hash Memory: 64MB, Table Memory: 0MB, Ponder: Off, Own Book: Off, Book/Position Learning: Off, Book: none, EGTB: none System: Win 10 Professional, NVIDIA GTX 1070, Ryzen 7 1800X, 64 GB RAM
- Network ID: 263
- Time control: 40/12 (adjusted to CCRL)
- Comments: Game was streamed on May 8th at https://www.twitch.tv/y_sensei
@chara1ampos why anybody ask this question maybe Alpha zero just a auto tuned stockfish derivative with neural network.The traditional chess engines elo depends tuning parameters in their code.Maybe they just do that in neural network.
Stockfish 1.01 elo 2754 in 2008 Stockfish 9 elo 3444 in 2018
Look stockfish development history it gained only 700 elo in ten years with million cpu time and genius c programmers whose tuned parameters step by step.Now we wait Leela gains 500 elo with self play.Who knows maybe the road map is totally wrong.
Why i think that because someone says leela draws with stockfish ok very good news but how can you explain these blunders and tactical weakness 3000 elo program? Leela's skeleton formed after 10 million games there is no return and this is big paradox for project.
"maybe Alpha zero just a auto tuned stockfish derivative with neural network" I'm afraid this is fully wrong, in at least:
- different tree search methods (MCTS vs alphabeta)
- different heuristics/evaluation functions (NNs vs handcrafted features)
- different learning approach (zero chess specific human knowledge, but the rules, vs human knowledge based handcrafted features, even if computer-assisted approach may used for chosing final blend of parameters). But you're fully right regarding huge number of selfplay games needed. LCZ learn very slowly. Alpha-like is brute force at learning stage (10's of million games needed), then 'smarter' (at last more human like, one would say) at playing stage (far less positions explored during tree search compared to SF or other alphabeta engines, to achieve same strength). Training pipeline squeezes very little knowledge from each selfplayed game, so millions are needed. Might sound disappointing indeed. Far from the human way...
- ID: 0002
- Game: https://lichess.org/efi0R82j
- Bad move: 21. Qxg7
- Correct move: 21. Re3
- Screenshot:

- Configuration: Game: LCZero 0.9 ID 271 vs Stockfish 9 18050909 Lvl 20 GUI: Arena 3.5.1 Settings: Threads/Cores: 4, Hash Memory: 64MB, Table Memory: 0MB, Ponder: Off, Own Book: Off, Book/Position Learning: Off, Book: none, EGTB: none System: Win 10 Professional, NVIDIA GTX 1070, Ryzen 7 1800X, 64 GB RAM
- Network ID: 271
- Time control: 40/4 (adjusted to CCRL)
- Comments: Game was streamed on May 10th at https://www.twitch.tv/y_sensei
Thanks for submitted the bug reports, they were very useful.
All the blunders so far can be explained by #576. The fix is there in client v0.10, but it will take multiple network generations to recover the network.
So for a few days (until at ~300000-500000 games are generated by v0.10 client and network is trained on that), don't submit any other positions, as they are likely caused by the same bug.
After that new blunder reports are very welcome!
For now it would be the most interesting to see examples of blunders that appeared recently. E.g. if LCzero played correct move in network id270 and now blunders. That way we'd have some examples of what exactly it unlearns and could look into training data.
ID: ID288CCLSGame65
Game: https://lichess.org/8mCbbkwl#240
Bad move: 121. Rc7.
Correct Move: Many other moves
Screenshot 1:
 Screenshot 2 shows Analysis by ID288 in Arena on my machine:
Screenshot 2 shows Analysis by ID288 in Arena on my machine:
 Screenshot 3 shows Analysis by ID94 in Arena on my machine (Rc7 not listed):
Screenshot 3 shows Analysis by ID94 in Arena on my machine (Rc7 not listed):
 Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
ID: ID288CCLSGame53
Game: https://lichess.org/0YJMfRI6#260
Bad move: 131. Ra6.
Correct Move: 131. Ba1 (By Stockfish 9 on LiChess)
Screenshot 1:
 Screenshot 2 shows Analysis by ID288 in Arena on my machine:
Screenshot 2 shows Analysis by ID288 in Arena on my machine:
 Screenshot 3 shows Analysis by ID94 in Arena on my machine (Ra6 not listed):
Screenshot 3 shows Analysis by ID94 in Arena on my machine (Ra6 not listed):
 Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
Thanks posting, we are looking into those positions. Evaluation of this position is improved a lot in id291, which confirms the main explanation that we have now (value head overfitting).
ID: ID288CCLSGame72
Game: https://lichess.org/CVYOwXSK
Bad Evaluation: Drew by 3-fold repetition with an evaluation of +15.98
Screenshot:
 Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
Configuration: CCLS Gauntlet
Network ID: 288
Time control: 1 min + 1 sec (increment)
Comment: Game was streamed on May 14th 2018.
I couldn't resist one more...
ID: ID280CCLSGame7
Game: https://lichess.org/rWWqu4tx#98
Rh7 would end the game immediately by 3-fold repetition, but Leela played the losing move Kh3 instead:
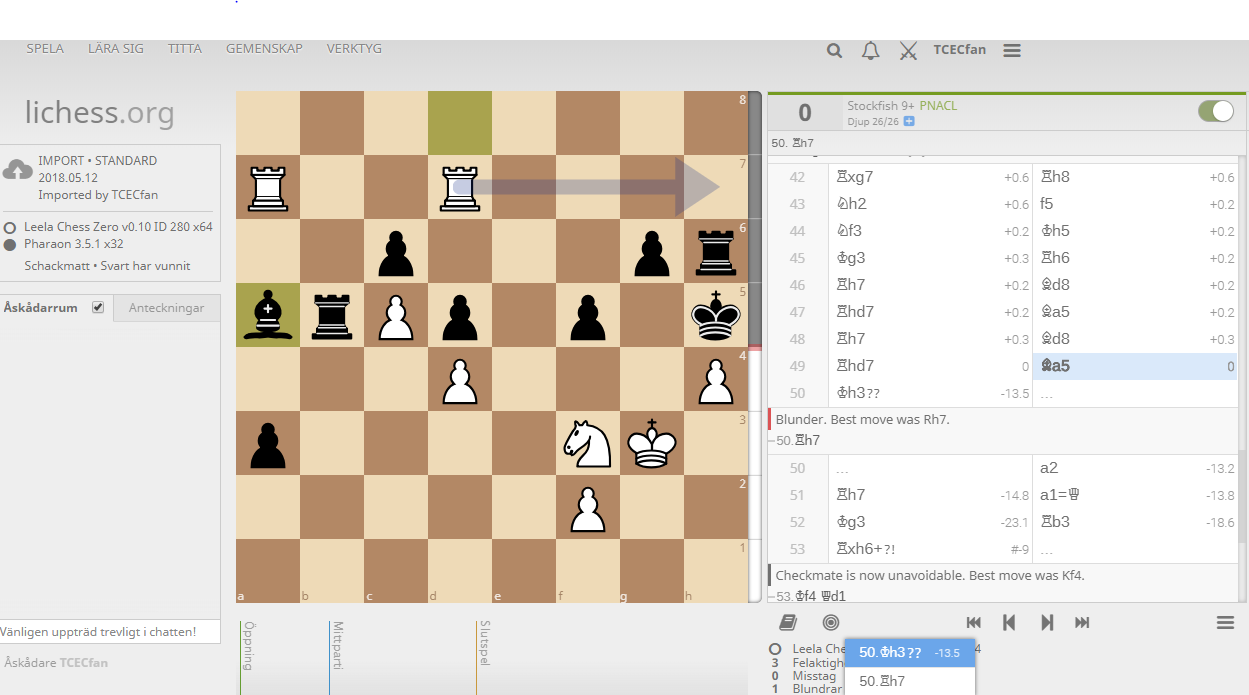 Stockfish 9 gives Rh7 as the only move
Stockfish 9 gives Rh7 as the only move
 Configuration: CCLS Gauntlet
Network ID: 280
Time control: 1 min + 1 sec (increment)
Comment: Does Leela handle 3-fold repetition correctly?
Configuration: CCLS Gauntlet
Network ID: 280
Time control: 1 min + 1 sec (increment)
Comment: Does Leela handle 3-fold repetition correctly?
Interestingly, on the Rc7?? Kxc7 and Ra6 Kxa6?? blunders above, I can reproduce them with ID288 on CPU both with game history.
With just FEN, while it doesn't play both blunders, the killing responses to both blunders are given very low probability from policy, so it's just dumb luck that the engine doesn't play the blunder.
The really interesting part is that with the FEN modified so the 50-move rule halfmove counter is set to 0, it immediately sees both killing moves with very high policy outputs.
This is also true of this recent match game: http://lczero.org/match_game/268131
With game history or FEN, 292 plays 132. Rc7??, giving the obvious capture response very, very low policy output.
With FEN altered so 50-move rule halfmove counter is set to 0, it immediately sees the capture with 99% probability from policy.
Maybe these examples are just lucky, but it seems high values for the 50-move rule halfmove counter correlate with very strange blunders.
http://lczero.org/match_game/268155
ID 292 blunders again against ID 233 near the 50-move rule coming up...
interesting bit based off of apleasantillusion's comment (tho I'm using 292).
the fen for the interesting position is "2r5/R7/8/8/5k2/8/2K5/8 w - - 85 121" where the policy net ID292 has Rc7 (wrongfully) at 99.91%.
specifically if you set it to 60 half moves (instead of 85) the policy net fro Rc7 is at .07%. At 65 half moves it's at .2%, at 66 it's at .71%, 67 it's at 1.23%, 68 it's at 6.53% (no longer considered the worst move), 69 it's at 89.47 percent.
I have no idea why the inflection point would be anywhere near where it, but it's definitely interesting and points towards a training bug corrupting the policy net.
FYI... Regarding the a7c7 rook blunder above, I think this might be explained (partially) by https://github.com/glinscott/leela-chess/issues/607 EDIT: I guess this can be disregarded since someone confirmed that Arena and most GUIs do always send moves... Regardless, leaving this here because it is interesting to see the difference in policies with and without history.
Network 288..
With history: position fen 7r/8/R7/3k4/8/8/2K5/8 w - - 77 117 moves a6a5 d5e6 a5a6 e6f5 a6a5 f5f4 a5a7 h8c8 go nodes 1000 (==> This chooses Kb3) info string Kb2 -> 0 (V: 59.51%) (N: 0.29%) PV: Kb2 info string Kd1 -> 0 (V: 59.51%) (N: 0.90%) PV: Kd1 info string Kb1 -> 2 (V: 52.08%) (N: 1.86%) PV: Kb1 Ke3 Ra3+ info string Kd2 -> 5 (V: 59.96%) (N: 2.27%) PV: Kd2 Kf5 Rb7 Kf4 info string Kd3 -> 11 (V: 60.53%) (N: 9.70%) PV: Kd3 Ke5 Re7+ Kd6 Re8 Kd5 info string Rc7 -> 381 (V: 67.65%) (N: 80.40%) PV: Rc7 Rb8 Rb7 Kf5 Rxb8 Ke6 Kd3 Kd5 Rb5+ Kc6 Kc4 info string Kb3 -> 491 (V: 83.56%) (N: 4.58%) PV: Kb3 Ke5 Rc7 Kd6 Rxc8 Kd7 Rc5 Kd6 Kc4 Ke6 info string stm White winrate 76.24%
Without history: position fen 2r5/R7/8/8/5k2/8/2K5/8 w - - 85 121 go nodes 1000 (==> This chooses Rc7) info string Kd1 -> 0 (V: 61.53%) (N: 0.00%) PV: Kd1 info string Kd2 -> 0 (V: 61.53%) (N: 0.00%) PV: Kd2 info string Kb2 -> 0 (V: 61.53%) (N: 0.00%) PV: Kb2 info string Kb3 -> 0 (V: 61.53%) (N: 0.00%) PV: Kb3 info string Kd3 -> 0 (V: 61.53%) (N: 0.00%) PV: Kd3 info string Kb1 -> 0 (V: 61.53%) (N: 0.01%) PV: Kb1 info string Rc7 -> 500 (V: 70.63%) (N: 99.98%) PV: Rc7 Rb8 Rb7 Kf5 Rxb8 Ke6 Kd3 Kd5 Rb5+ Kc6 Kc4
As to the a7c7 blunder above, I think the history's only part of the problem... The other part of the issue is that the All Ones plane (last input plane) bug really messed up policies.
Good input data was being trained on a bad policy. Consider the effect of the negative log loss/cross entropy in these examples (non-buggy network with low outputs getting trained on a buggy high output).
Here's output from network ID 280. Notice that the a7c7 move only has high probability when the all ones input plane was buggy. Essentially, I think it was bad data like this that kept messing things up.
History + AllOnesBug Policy ('a7c7', 0.8687417), ('c2d3', 0.046122313), ('c2b3', 0.034792475), ('c2d2', 0.03021726), ('c2d1', 0.0111367665), ('c2b1', 0.006555821), ('c2b2', 0.0024336604), Value: 0.5331184417009354
History + NoBug ('c2d3', 0.47858498), ('c2b3', 0.13757008), ('c2d2', 0.13545689), ('c2d1', 0.08749167), ('c2b1', 0.08396132), ('c2b2', 0.07649834), ('a7c7', 0.000436759), Value: 0.5014338248874992
NoHistory + AllOnesBug Policy: ('a7c7', 0.99920577), ('c2d2', 0.00019510729), ('c2b3', 0.00015975242), ('c2d3', 0.00015850786), ('c2b1', 0.0001421545), ('c2d1', 7.9948644e-05), ('c2b2', 5.882576e-05)]), Value: 0.5555554553866386
NoHistory+NoBug ('c2d3', 0.34282845), ('c2b3', 0.22524531), ('c2d2', 0.14119184), ('c2b2', 0.09196934), ('c2d1', 0.09108826), ('c2b1', 0.08420463), ('a7c7', 0.023472117), Value: 0.49658756237477064
Now look how all of that changed by network 286, below - now the input with missing history is starting to show the bad policy:
History+AllOnesBug ('a7c7', 0.88481957), ('c2d3', 0.043222357), ('c2d2', 0.030274319), ('c2b3', 0.017787572), ('c2b1', 0.011131173), ('c2b2', 0.011077223), ('c2d1', 0.0016878309), 0.8049132525920868)
History+NoBug (OrderedDict([('c2d3', 0.35683072), ('c2b3', 0.17884524), ('c2d2', 0.15325584), ('c2b2', 0.1069537), ('c2d1', 0.10222348), ('c2b1', 0.10148263), ('a7c7', 0.00040832962)]), 0.5084156421944499)
NoHistory+AllOnesBug ('a7c7', 0.9984926), ('c2d3', 0.00064814655), ('c2b1', 0.00030561475), ('c2d2', 0.00022950297), ('c2b3', 0.00016663132), ('c2d1', 8.821991e-05), ('c2b2', 6.930062e-05)]), 0.8271850347518921)
NoHistory+NoBug ('c2b3', 0.35689142), ('a7c7', 0.227083), ('c2d2', 0.1410887), ('c2d3', 0.10505199), ('c2b1', 0.078001626), ('c2d1', 0.0670605), ('c2b2', 0.024822742)]), 0.49565275525674224)
By the time it got to network 288, the policy was really bad in this particular spot: History+AllOnesBug ('a7c7', 0.81777406), ('c2b1', 0.0735284), ('c2d3', 0.045673266), ('c2d2', 0.044812158), ('c2d1', 0.011020878), ('c2b3', 0.0059179077), ('c2b2', 0.0012732706), 0.9999993741512299)
History+NoBug ('a7c7', 0.8040016), ('c2d3', 0.0970014), ('c2b3', 0.04580218), ('c2d2', 0.022658937), ('c2b1', 0.018647738), ('c2d1', 0.008990083), ('c2b2', 0.0028980032), 0.5951071679592133
NoHistory+AllOnesBug ('c2b1', 0.30733383), ('a7c7', 0.25477663), ('c2d2', 0.19509505), ('c2d3', 0.17735933), ('c2d1', 0.037348717), ('c2b3', 0.02388807), ('c2b2', 0.004198352), 0.9999998211860657
NoHistory+NoBug ('a7c7', 0.99980253), ('c2b1', 6.103614e-05), ('c2d3', 4.706335e-05), ('c2b3', 3.6989695e-05), ('c2b2', 2.2621784e-05), ('c2d2', 1.6375083e-05), ('c2d1', 1.3423687e-05), 0.6152948960661888
Now, at network 294, this is the current situation (ignoring buggy input plane, as it's no longer relevant): History+NoBug ('c2d3', 0.32457772), ('c2b1', 0.19262017), ('c2d1', 0.15003791), ('c2b3', 0.12282815), ('c2d2', 0.10260171), ('c2b2', 0.08874603), ('a7c7', 0.018588383), 0.46542854234576225)
NoHistory+NoBug ('a7c7', 0.99916804), ('c2b1', 0.00017883514), ('c2d1', 0.00016860983), ('c2d3', 0.00016126267), ('c2b2', 0.00012590773), ('c2d2', 0.00010842814), ('c2b3', 8.8898094e-05)]), 0.43435238301754)
Does it still blunder in those positions if you use --fpu_reduction=0.01 (instead of default 0.1) ?
In the game nelsongribeiro posted, the same pattern holds true (tested with 292).
With history, she plays 124.Ke7 with a very high probability from policy (84.89%), and the response Qxd5 just taking the hanging queen is given only a 2.93% from policy.
Without history at the root, just FEN, she again plays Ke7 with high probability from policy (95.83%), and the Qxd5 response taking the hanging queen is given only 2.33% from policy.
With the FEN modified in only one way, setting 50-move rule counter to 0, Ke7's policy drops to 37.34%, and Qxd5 after Ke7 jumps to 95.07%
Now, from a purely objective standpoint in this particular position, none of this matters so much, since the position is losing to begin with, although forcing black to find the winning idea in the king and pawn ending is a much stronger way of playing than just hanging the queen.
Also, independently of that, the fact that taking a hanging queen is only ~2% from policy when the 50-move rule counter is high is a bit disturbing and is in line with the other examples I cited above.
In general, the variation in probability for Qxd5 based on the 50-move rule counter is quite odd.
In that exact position with black to move (6q1/4K2k/6p1/3Q1p1p/7P/6P1/8/8 b - - 0 0), here are probabilities for Qxd5 with different values of 50-move rule counter:
0: 68.26% 1: 76.71% 5: 89.40% 10: 91.63% 20: 92.48% 30: 94.28% 40: 89.57% 50: 77.83% 60: 83.95% 70: 52.39% 80: 66.84% 90: 11.43% 99: 1.06%
The really bad move is the move made just before that position: The FEN position is (4K3/6qk/3Q2p1/5p1p/7P/6P1/8/8 w - - 94 123).
Its a draw at this point, on move 123, ID 292 played 123. QD5 intead of 123. QE6
Last time that a pawn was moved was at 75...f5 , what makes this the 48th move after that.
EDIT: best move was wrong before..
Just to add to this, the Rxf3+ that's being tracked in the sheet at https://docs.google.com/spreadsheets/d/1884-iHTzR73AgFm19YYymg2yKnwhtHdaGyHLVnffLag/edit#gid=0 shows the same behavior.
With net 297, probability with various 50-move counter rule values:
0: 0.07% 10: 1.88% 25: 10.23% 50: 1.11% 90: 1.72% 99: 6.97%
That's some heavy variation just from changing the 50-move rule counter.
Also, the pattern is different with this one. In all the others, probabilities were worst at the very high counts, a bit better at very low counts, and best at counts around 30. Here that last trend maintains, but the other is more muddled.
I don't know if it is a consequence of the bug, or the new PUCT values which inhibit tactics, but the latest versions (I am watching 303 right now) have some appallingly weak ideas of king safety and closed positions. I am playing a match against id223 at 1m+1s and it is more than a tactical weakness issue, it is one of completely wrong evaluations, which 223 did not have, that is leading it to happily let its king be attacked until it is too late to save itself. I also saw more than one case where it thought a dead drawn blocked game, with no entry or pieces, was +2, while 223 thought it about equal. The result was that 303 preferred to sacrifice a pawn or two to not allow a draw, and then lost quickly thanks to the material it gave away.

id303 is white, and id223 is black. Both are playing with v10 (different folders) with default settings.
@ASilver I have watched many games from many of the CCLS gauntlets, and my overall view (from the perspective of spectator) is that her style changed markedly following the release of v0.8. In particular, she started showing:
Type 1: unstable or poor evaluations, and inflexible play.
Type 2: "buggy-looking" play in closed positions in which both engines are shuffling, in repeated positions (especially 3-fold), and in positions where the 50-move rule is key.
In my view, Type 1 has "followed the trajectory of the value head", whereas Type 2 has seemed to persist even as "the value head has partially recovered".