Daily-Arxiv-Tracking-Automation
 Daily-Arxiv-Tracking-Automation copied to clipboard
Daily-Arxiv-Tracking-Automation copied to clipboard
Automatically download the all pdfs from a daily rss
![]()
DARTA: Daily Arxiv Tracking Automation
How to use?
- on web: visit https://arxiv-searcher.onrender.com
- on your local machine:
git cloneandsh run_app.sh
Features
1. Automatically parse a daily arxiv rss
- a.
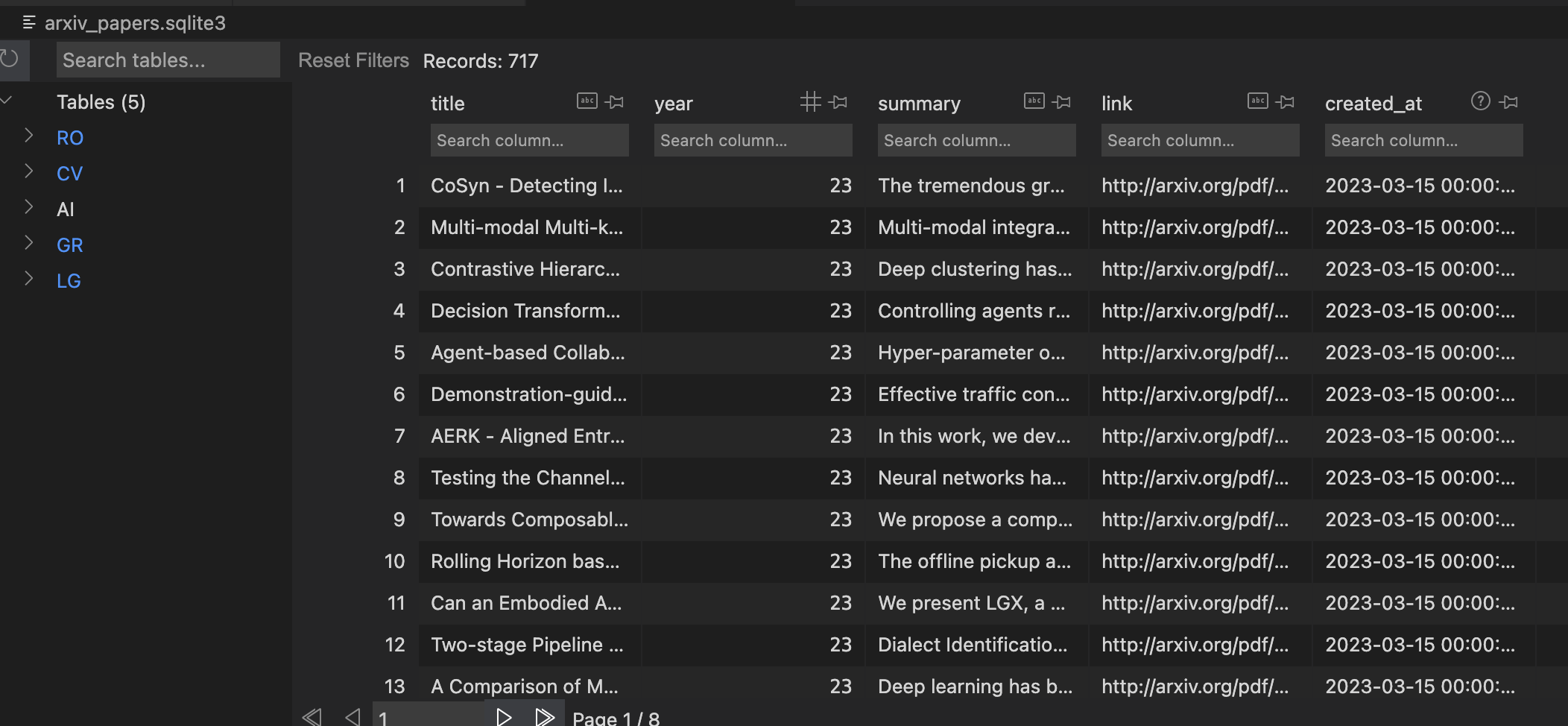
python3 arxiv_saver_to_db.py: parse information and save into the database (sqlite3)- This DB is automatically growing (appending) via Github Action.
- example
-
- b. (optional)
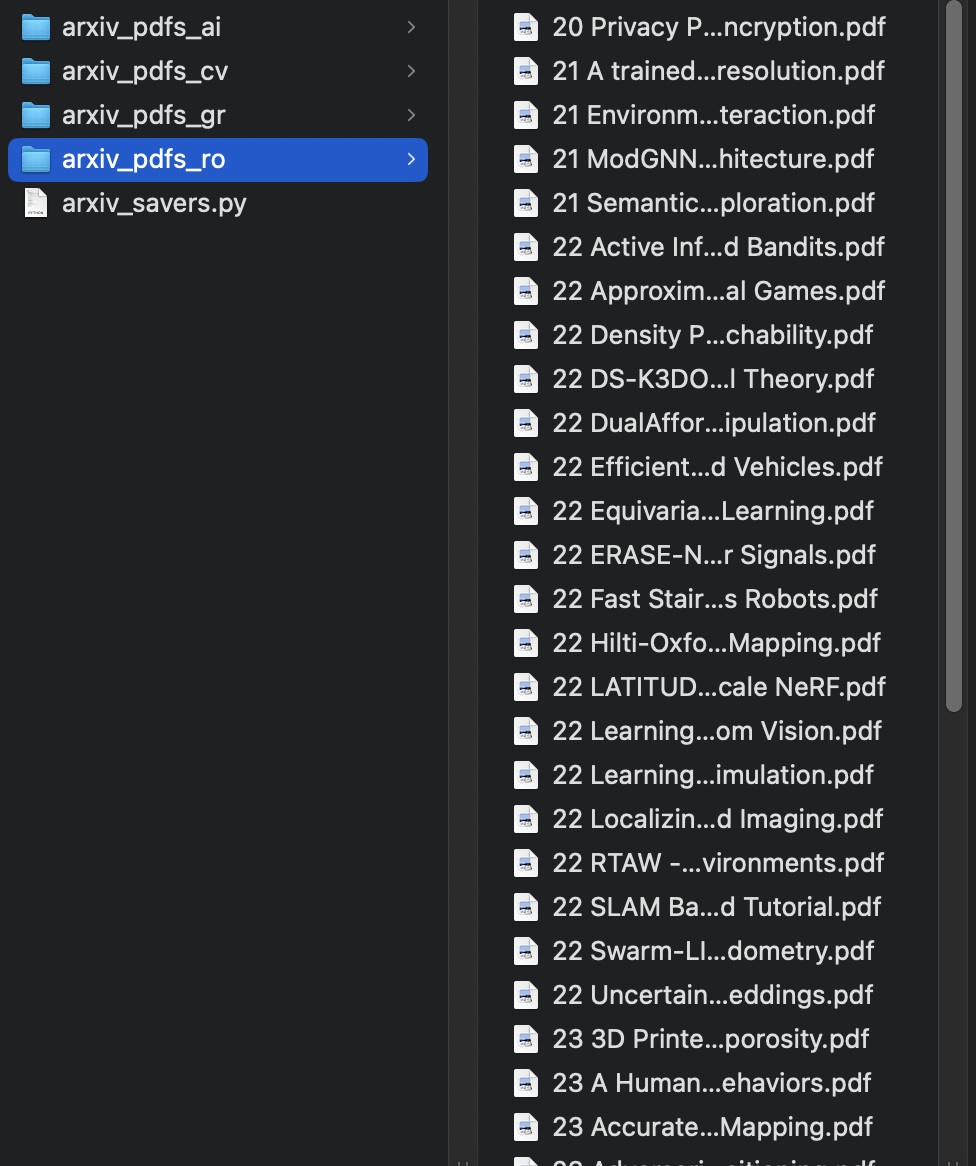
python3 arxiv_saver_as_pdf.py: download the all pdfs- with auto-naming as {YY} {Title}
- example
-

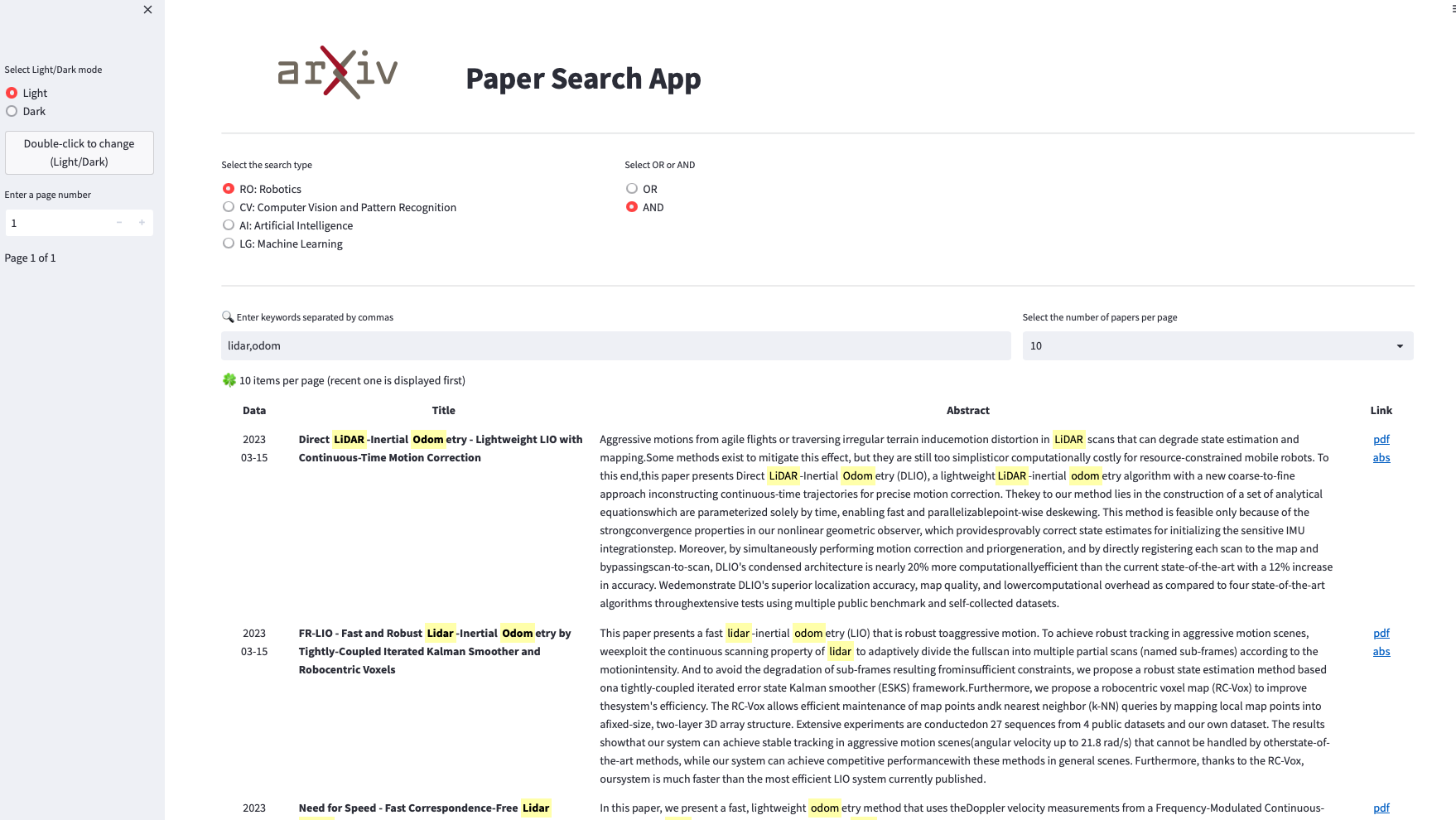
2. Search web app
- Just do
run_app.sh- The dependencies: fastapi, uvicorn, and streamlit
- example
- The image of the top!
Tips
- To make a requirements.txt file,
pipreqs --encoding=utf8would be helpful.
TODO
- sqlite3 파일을 github repository (100mb 제한) 가 아닌 원격 저장소에서 pull해오고 push하기