whisper.cpp
 whisper.cpp copied to clipboard
whisper.cpp copied to clipboard
(Large) Quality >>, - and repetition
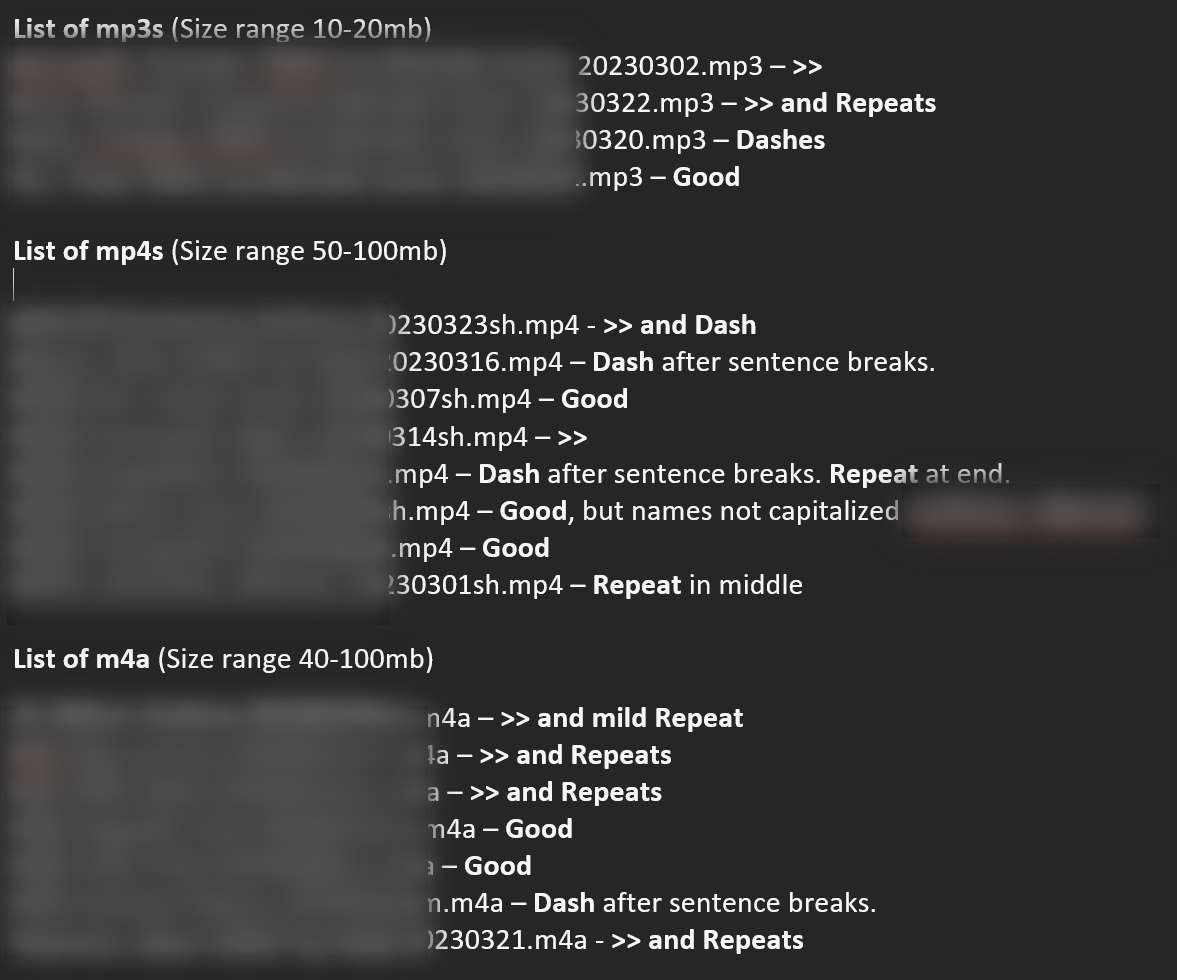
Hi All, Thank you ggerganov for your hard work on this. We're looking to improve our whisper transcriptions consistency. So far I've run 17 files on a Mac roughly 1 hour each, and the results vary quite a bit. We're manually proofing our whispers, so we get up close and personal with their accuracy while listening to the recording. Files started as .mp3, .mp4, and m4a, and were then converted to wav using Easy Wav Converter Lite (open to ideas here).
Rarely, like for half a page every 10 pages, there will be a lot of mistakes. And rarely a few sentences will be missing here or there.
I tried to track the other errors down to the initial format type, but there seems to be little to no correlation. The mp4s 'seem' best with fewer of the following negative things, and mp3s seem worst, but this is likely too small a batch to fairly judge them.
I haven't changed any of the code while making these.
- 5 of them are Good. They transcribed well, no additional comments.
- 7 of them have a lot of >> a space after paragraph breaks.
- 5 of them have a dash, - a space after paragraph breaks.
- 5 of them have repeats. 2 of them were massive, like 5 pages of the same sentence.
Here's a code example from one. I'm not sure what's helpful on your end for troubleshooting. Happy to help in any way I can.
Examples of data: Top Candice's-iMac:whisper.cpp candice$ ./main -m models/ggml-large.bin --output-txt -of NAME_20230216cm_whisper -f samples/NAME_20230216cm.wav whisper_init_from_file: loading model from 'models/ggml-large.bin' whisper_model_load: loading model whisper_model_load: n_vocab = 51865 whisper_model_load: n_audio_ctx = 1500 whisper_model_load: n_audio_state = 1280 whisper_model_load: n_audio_head = 20 whisper_model_load: n_audio_layer = 32 whisper_model_load: n_text_ctx = 448 whisper_model_load: n_text_state = 1280 whisper_model_load: n_text_head = 20 whisper_model_load: n_text_layer = 32 whisper_model_load: n_mels = 80 whisper_model_load: f16 = 1 whisper_model_load: type = 5 whisper_model_load: mem required = 3336.00 MB (+ 71.00 MB per decoder) whisper_model_load: kv self size = 70.00 MB whisper_model_load: kv cross size = 234.38 MB whisper_model_load: adding 1608 extra tokens whisper_model_load: model ctx = 2950.97 MB whisper_model_load: model size = 2950.66 MB
system_info: n_threads = 4 / 4 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | VSX = 0 |
main: processing 'samples/NAME_20230216cm.wav' (18453984 samples, 1153.4 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
Bottom of transcript to end [01:23:46.000 --> 01:23:47.000] It just got dark. [01:23:47.000 --> 01:23:48.000] >> All right. [01:23:48.000 --> 01:23:49.000] Yeah, it's about 2:30 here. [01:23:49.000 --> 01:23:50.000] >> Yeah.
output_txt: saving output to 'NAME_20230323hm_whisper.txt'
whisper_print_timings: fallbacks = 2 p / 2 h whisper_print_timings: load time = 10919.42 ms whisper_print_timings: mel time = 21016.19 ms whisper_print_timings: sample time = 13002.72 ms / 18843 runs ( 0.69 ms per run) whisper_print_timings: encode time = 4586758.00 ms / 201 runs (22819.69 ms per run) whisper_print_timings: decode time = 2825893.75 ms / 18835 runs ( 150.03 ms per run) whisper_print_timings: total time = 7460920.00 ms
So any advice for more consistent syntax with whisper or anything else is welcome. Thank you for your time.