Update documentation wrt load_config_file
Issue
The provider does not correctly use the specified exec and connection details if the load_config_file attribute is not explicitly set to false.
Example
This works, IF the environment variable KUBECONFIG is also set to a valid kubernetes config, and will use the settings provided below (from all appearances).
provider "kubectl" {
host = var.eks_endpoint
cluster_ca_certificate = base64decode(var.eks_ca_certificate)
token = data.aws_eks_cluster_auth.cluster.token
exec {
api_version = "client.authentication.k8s.io/v1alpha1"
args = ["eks", "get-token", "--cluster-name", var.eks_cluster_name, "--region", data.aws_region.current.name]
command = "aws"
}
}
If the KUBECONFIG environment variable is not set, the above will generate an error like the below when you try to apply any manifests using the provider.
failed to create kubernetes rest client for read of resource: Get "http://localhost/api?timeout=32s": dial tcp [::1]:80: connect: connection refused
Resolution This can be resolved by explicitly adding
load_config_file = false
to the kubectl provider definition above.
Requested change Explicitly warn/document about the above behaviour or the priority order of the usage of the provider attributes.
Thank you for this - I been struggling for a few days trying to work out what was happening. The kubernetes provider accepts the data token perfectly and this refuses it. But the mentioned solution works. Thanks
Can confirm. Setting this config on the provider also solved my problem +1
@gavinbunney this would be crucial to add as documentation or fix, caused a lotta grief for us 😢
In v1.14.0 explicitly setting load_config_file to false and using the exec block doesn't appear to have an effect on the provider's desire to use the local kubeconfig file.
No kubeconfig file is present in ~/.kube
total 16
drwxr-x--- 4 webdog staff 128 Nov 10 2021 cache
drwxr-xr-x 4 webdog staff 128 Nov 26 2021 config.d
-rw-r--r-- 1 webdog staff 1066 Feb 15 10:28 hashicorpTutorialCert.crt
drwxr-x--- 67 webdog staff 2144 Jun 13 21:30 http-cache
env shows $KUBECONFIG is not set:
✘ env
TERM_SESSION_ID=
SSH_AUTH_SOCK=
LC_TERMINAL_VERSION=3.4.12
COLORFGBG=15;0
ITERM_PROFILE=Default
XPC_FLAGS=0x0
LANG=en_US.UTF-8
PWD=
SHELL=/bin/zsh
__CFBundleIdentifier=com.googlecode.iterm2
SECURITYSESSIONID=
TERM_PROGRAM_VERSION=3.4.12
TERM_PROGRAM=iTerm.app
PATH=/Users/webdog/anaconda3/bin:/usr/local/Caskroom/google-cloud-sdk/latest/google-cloud-sdk/bin:/usr/local/opt/node@14/bin:/Users/webdog/anaconda3/bin:/usr/local/opt/openssl@3/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/share/dotnet
LC_TERMINAL=iTerm2
COLORTERM=truecolor
COMMAND_MODE=unix2003
TERM=xterm-256color
HOME=/Users/webdog
TMPDIR=
USER=webdog
XPC_SERVICE_NAME=0
LOGNAME=webdog
LaunchInstanceID=
__CF_USER_TEXT_ENCODING=0x0:0:0
ITERM_SESSION_ID=
SHLVL=1
OLDPWD=
ZSH=/Users/webdog/.oh-my-zsh
PAGER=less
LESS=-R
LSCOLORS=Gxfxcxdxbxegedabagacad
ZSH_TMUX_TERM=screen-256color
ZSH_TMUX_CONFIG=/Users/webdog/.tmux.conf
_ZSH_TMUX_FIXED_CONFIG=/Users/webdog/.oh-my-zsh/plugins/tmux/tmux.extra.conf
LC_CTYPE=en_US.UTF-8
TIME_STYLE=long-iso
_=/usr/bin/env
```shell
Error: default/service-name failed to create kubernetes rest client for update of resource: Get "http://localhost/api?timeout=32s": dial tcp [::1]:80: connect: connection refused
│
│ with kubectl_manifest.hashicups_service_intentions["service-name"],
│ on modules/eks/consul-crd-service_intentions.tf line 1, in resource "kubectl_manifest" "hashicups_service_intentions":
│ 1: resource "kubectl_manifest" "hashicups_service_intentions" {
The localhost error seems to indicate usage of the kubeconfig.
Configuration:
terraform {
required_providers {
kubectl = {
source = "gavinbunney/kubectl"
version = "1.14.0"
}
}
}
data "aws_eks_cluster" "this" {
name = module.eks.cluster_id
}
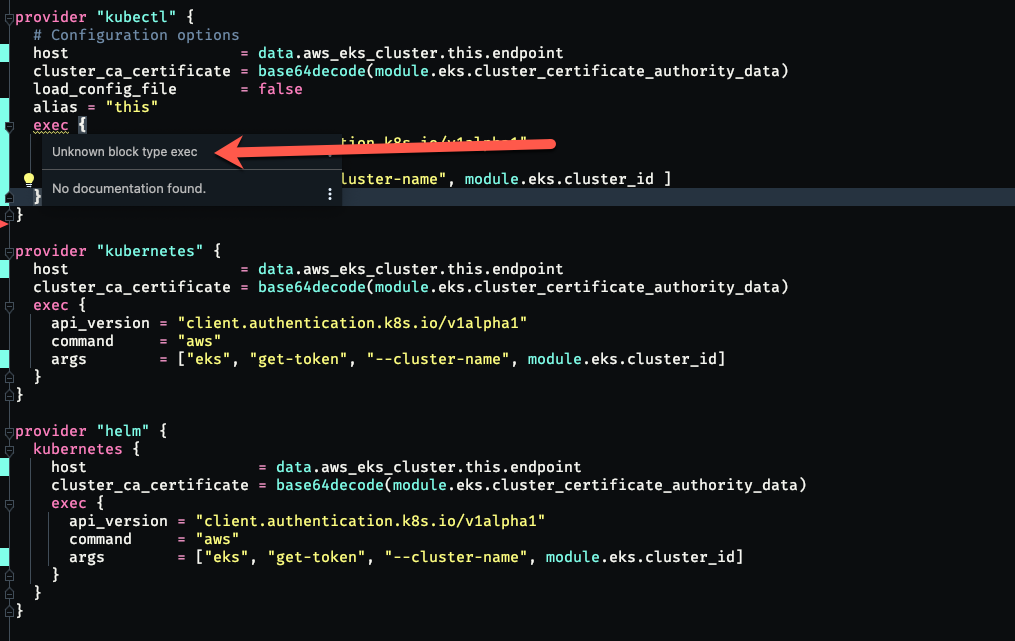
provider "kubectl" {
# Configuration options
host = data.aws_eks_cluster.this.endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
load_config_file = false
exec {
api_version = "client.authentication.k8s.io/v1alpha1"
command = "aws"
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_id]
}
}
# Other working providers shown below as an example:
provider "kubernetes" {
host = data.aws_eks_cluster.this.endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1alpha1"
command = "aws"
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_id]
}
}
provider "helm" {
kubernetes {
host = data.aws_eks_cluster.this.endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1alpha1"
command = "aws"
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_id]
}
}
}
After updating the kubeconfig to include this cluster, everything seems to work with the kubectl provider. Without the kubeconfig, I was still able to use and deploy resources with the kubernetes and helm providers inside this submodule.
❯ ✘ aws eks update-kubeconfig --region us-east-1 --name $NAME
Added new context arn:aws:eks:us-east-1:$AWS_ACCOUNT:cluster/$NAME to /Users/webdog/.kube/config
Something of note (but maybe a red herring), the exec block is showing in my IDE as unknown in context of the kubectl provider. But the exec plugin is known to the other providers. (The 'alias' attribute was removed after this screenshot, having no effect on the behavior reported).
Along those lines, the kubectl_manifest never shows up as an available resource in autocompletion, even though terraform renders the infrastructure code and deploys it as valid.
As I understand it, the helm and kubernetes providers have had issues with retrieving cluster info during an apply because of apply-time provider issues. Specifically, I ran into issues with the kubernetes provider's kubernetes_manifest resource not being able to capture the OpenAPI schema for the manifest during the initial apply. I found this provider as an alternative for my use case.
In the case of this infrastructure, both the kube and helm providers are able to capture the EKS token during terraform apply, creating resources inside the EKS cluster.
This comment seems to be related: https://github.com/gavinbunney/terraform-provider-kubectl/issues/114#issuecomment-858561862
...in my case, the version is pinned, and these resource's providers are defined in a submodule already.