Accidental CA/MCM Overprovisioning/-compensation
When I create load (e.g. by scaling up a deployment that requires a machine/node per replica), I get the expected number of machines/nodes. However, if I accidentally delete some portion of it, CA/MCM overcompensate and instead of recreating the deleted portion, I see more machines/nodes.
In the example below, the muscle deployment requires one machine/node per replica. I scaled up to 3, got 3 machines/nodes, then deleted 2 of them by tweaking the machinedeployment and instead of 2 being recreated, 4 were recreated. Unfortunately, my max setting for the worker pool was 5, so I don't know whether it stopped there because I hit the max setting or not.
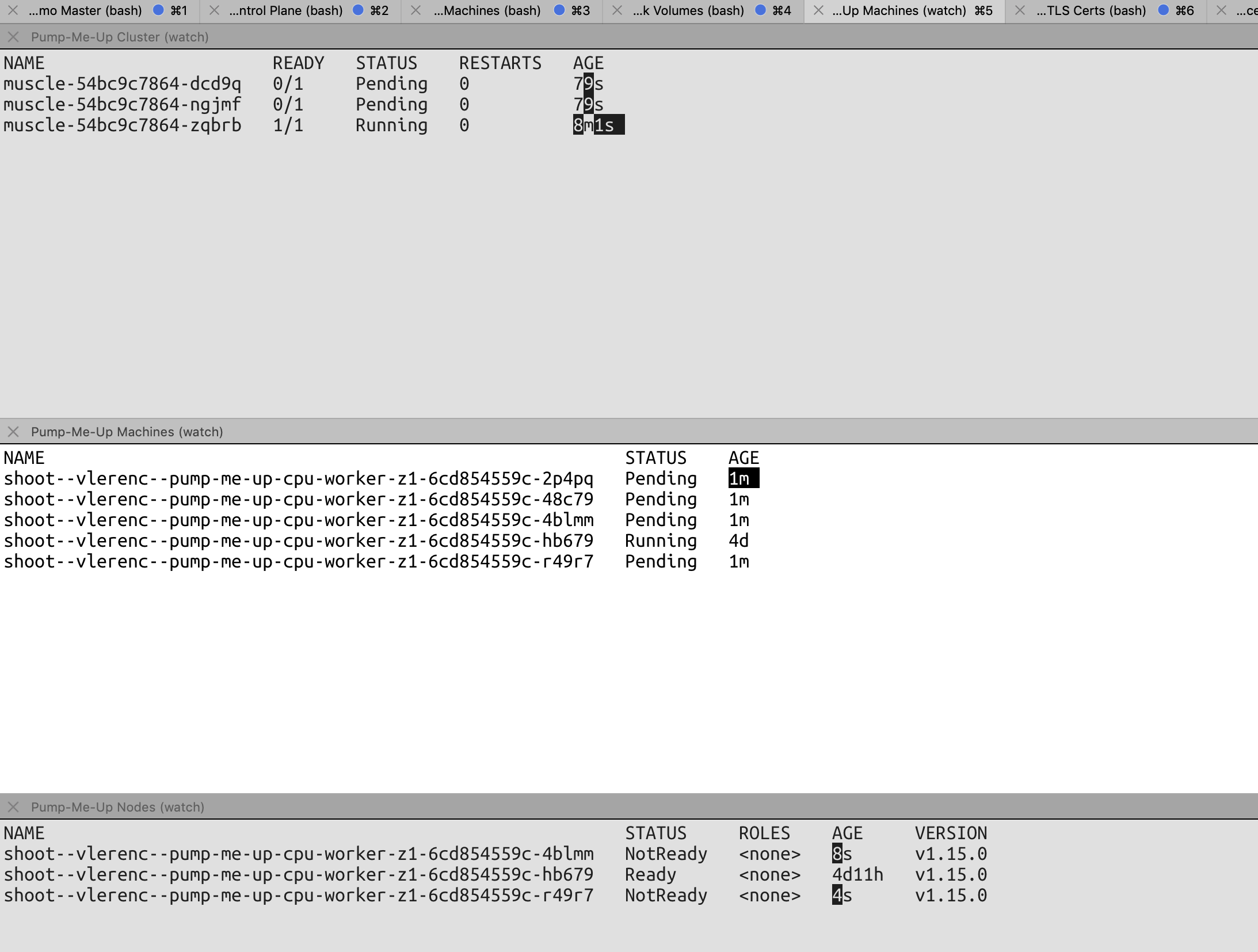
Is that to be expected or a bug?
Hi Vedran, thanks for reporting. I tried digging up a little, and found the following:
There are basically 2 main aspects wrt to this issue.
- Theoretical:
- Cluster Autoscaler internally uses the
first fit decreasing bin-packing algorithmwhile scaling-up the cluster. Basically, autoscaler uses this algorithm to determine the exact number of machines to be added in the cluster to accommodate the new/un-schedulable workload. This problem is known to beNP-hard, and an algorithm may not offer optimal solution every time. It means Cluster autoscaler might over-provision a little[given upper-bound] with complicated work-load setup. Refer the comment from the code to know more- link - We might have to live with it.
- Implementation:
-
This aspect is better related to us, and we could probably optimize a little here.
-
While reproducing the steps mentioned above, I observed :
- Autoscaler seems to be getting confused specifically when machine-objects are deleted abruptly, which is not a smooth scale-up/down scenario. - that's what happens[from CA PoV] when machine deployments replica is reduced.
- I could see 2 re-conciliations from CA, wherein the first reconciliation, CA sets the MachineDeployment to optimal number, in the case above that's 3.
- But in the next reconciliation, it is changed to 4/5, where it over-provisions. We are looking more into it to understand how to avoid extra provisioning in second re-conciliation.
-
But it is also important to mention that, in normal scale-up/down scenarios where replica field of MachineDeployment is only updated by CA[and not manually], it seems to be behaving as expected.
We shall keep this thread up to date with new findings.
I think there is a case if we directly update the MachineDeployment managed by CA, CA may end up misbehaving. I suggest we keep it open, to take a further look once again after autoscaler-rebase.